语言模型的蜂巢思维
你让 GPT-4 推荐一部被低估的科幻电影,它说《月球》。换 Claude 问同一个问题,也是《月球》。再问 Gemini,还是《月球》。一篇 NeurIPS 2025 Best Paper Artificial Hivemind: The Open-Ended Homogeneity of Language Models (and Beyond) 用大规模实验量化了这个现象:不同语言模型在开放式问题上的回答,相似度高到反常。
Hivemind,蜂巢思维,科幻小说里一群个体共享同一个意识的经典设定。用来描述当前语言模型的集体行为,这个词选得精准。
Infinity-Chat 数据集
测准确率有 MMLU,测安全性有 red-teaming benchmark,但测"回答是否多样化"一直缺趁手的工具。论文为此构建了 Infinity-Chat,包含 26000 条真实用户的开放式问题和 31250 条人类标注(每个样本 25 个独立标注者)。问题全都没有标准答案——“给我推荐一个冷门爱好"“写一首关于孤独的诗"“帮我想个创业点子”。配套的还有一个 6 大类 17 子类的开放式 prompt 分类体系,从头脑风暴到创意写作到角色扮演都有覆盖。
同一个问题,1250 条回答,两个簇
实验设计很直接:25 个主流模型(论文总计测了 70+ 个,主实验报告 25 个代表性模型),每个模型对同一批问题各生成 50 条回答(top-p=0.9,temperature=1.0),计算回答之间的 sentence embedding 相似度。
下面这张 PCA 降维图是全文最直观的结果。问题是"写一个关于时间的比喻”,25 个模型的 1250 条回答投射到二维空间后只形成两个簇:左边几乎所有模型都在说"time is a river”,右边是"time is a weaver"的变体。
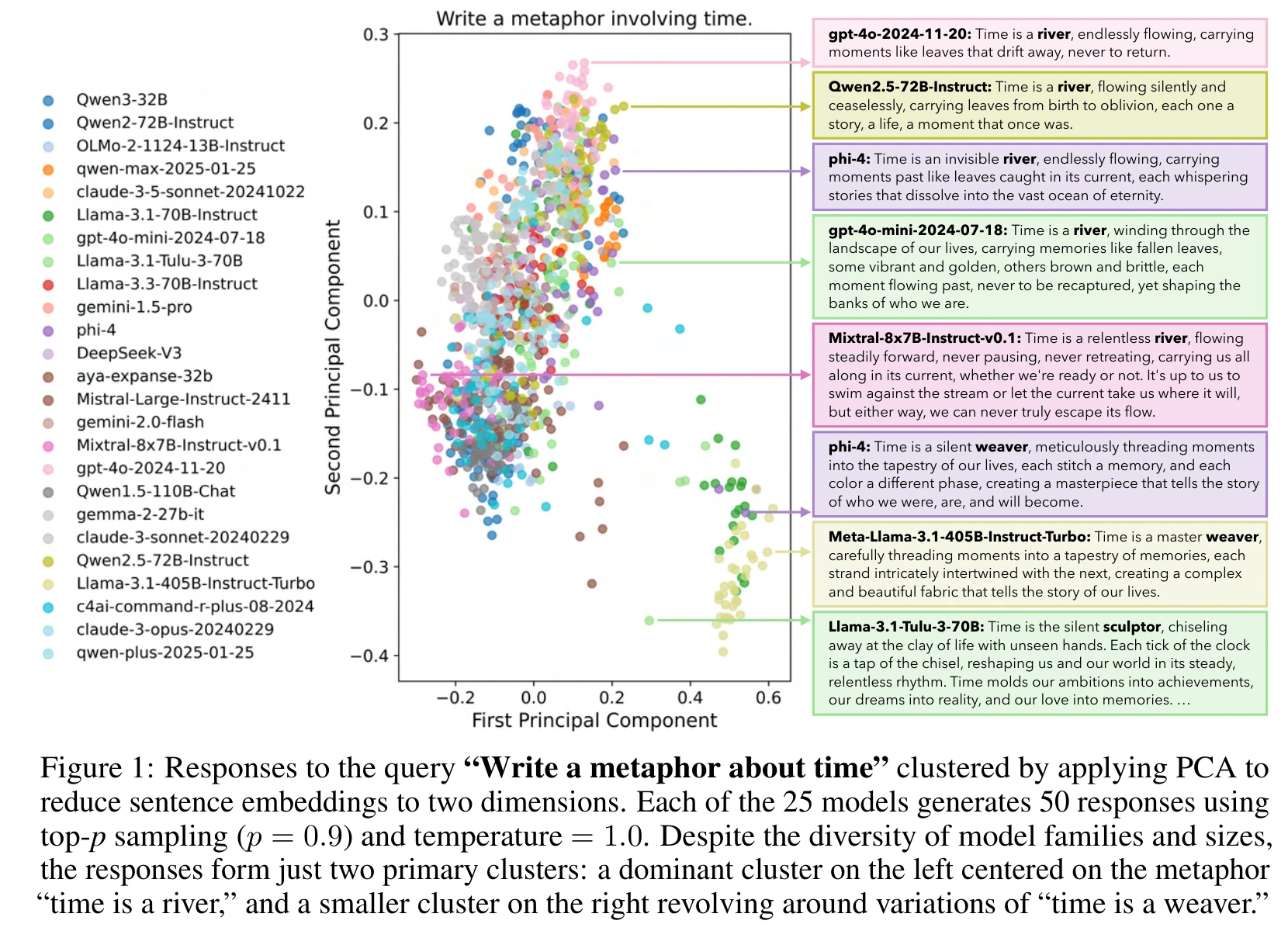
这只是单个问题的可视化(论文的定量分析覆盖了 100 个问题),但已经能看出问题的严重程度。
模型内重复:采样策略帮不了太多
同一个模型反复回答同一个问题,79% 的情况下回答之间的 embedding 相似度超过 0.8。这是在 temperature=1.0 的条件下,已经是正常使用中偏高的随机性了。
论文还测试了 min-p 解码(top-p=1.0,min-p=0.1,temperature=2.0),一种专门为提升多样性设计的动态采样策略。极端重复(相似度 > 0.9)有所减少,但 81% 的回答对仍然超过 0.7,61.2% 超过 0.8。温度拉满、换了采样算法,多样性的改善仍然有限。论文的结论是,更根本的解决方案需要在模型训练层面而非解码层面寻找。
跨模型的蜂巢效应
更反直觉的发现在模型间。不同公司、不同架构的模型,面对开放式问题时,输出的语义重合度同样很高。
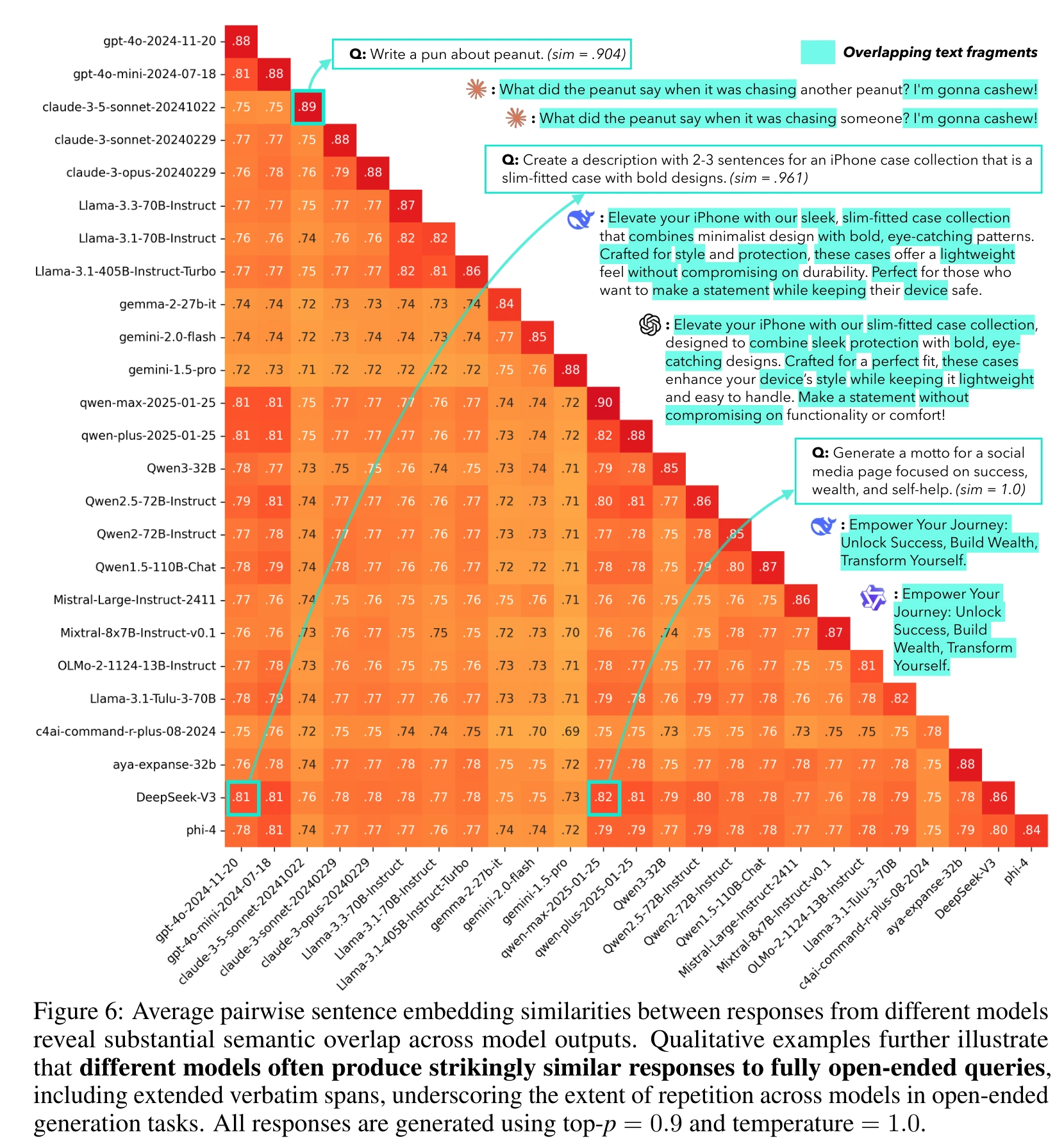
几个具体数字:DeepSeek-V3 和 qwen-max 的跨模型相似度达到 0.82,DeepSeek-V3 和 GPT-4o 达到 0.81,整体范围在 0.71 到 0.82 之间。论文指出 GPT 系列和 Qwen 系列与其他家族的相似度普遍偏高,推测可能与跨区域的数据管线共享或合成数据污染有关,但具体原因因训练细节不公开而无法确证。
逐字重叠的案例更能说明问题。“给 iPhone 手机壳系列写一段 2-3 句的描述”,DeepSeek-V3 和 GPT-4o 的文案里出现了"Elevate your iPhone with our"“sleek, without compromising"“with bold, eye-catching"等完全一致的短语片段。qwen-max 和 qwen-plus 对"写一句关于成功、财富、自助的座右铭"生成了一模一样的回答(相似度 1.0)。
论文还做了一个验证:取每个问题下相似度最高的 50 条回答,看它们来自多少个不同的模型。如果各模型输出足够不同,top-50 应该全部来自同一个模型的多次采样。实际结果是平均来自约 8 个不同模型,有些问题超过 10 个——不同模型的输出已经混到分不出谁是谁了。
需要说明的是,论文用 sentence embedding 相似度作为主要度量。这个指标对表层措辞的敏感度高于对深层语义差异的区分度,可能会高估某些类型的同质化。不过从逐字重叠的定性案例来看,同质化确实不只是度量层面的假象。
同质化的成因与奖励模型的失灵
论文明确表示没有做因果分析,但指出了几个值得未来研究深挖的方向:预训练数据的重叠、对齐过程的影响、记忆与污染。从已有文献的角度,训练数据源头的高度重叠、RLHF 偏好优化对少数派口味的压制、以及合成数据在训练集中的循环积累,都是可能的贡献因素。
论文在实证层面更直接的贡献是揭示了奖励模型的校准问题。Infinity-Chat 每个样本有 25 个标注者打分,这个密度足以看到人类偏好的分布形态。
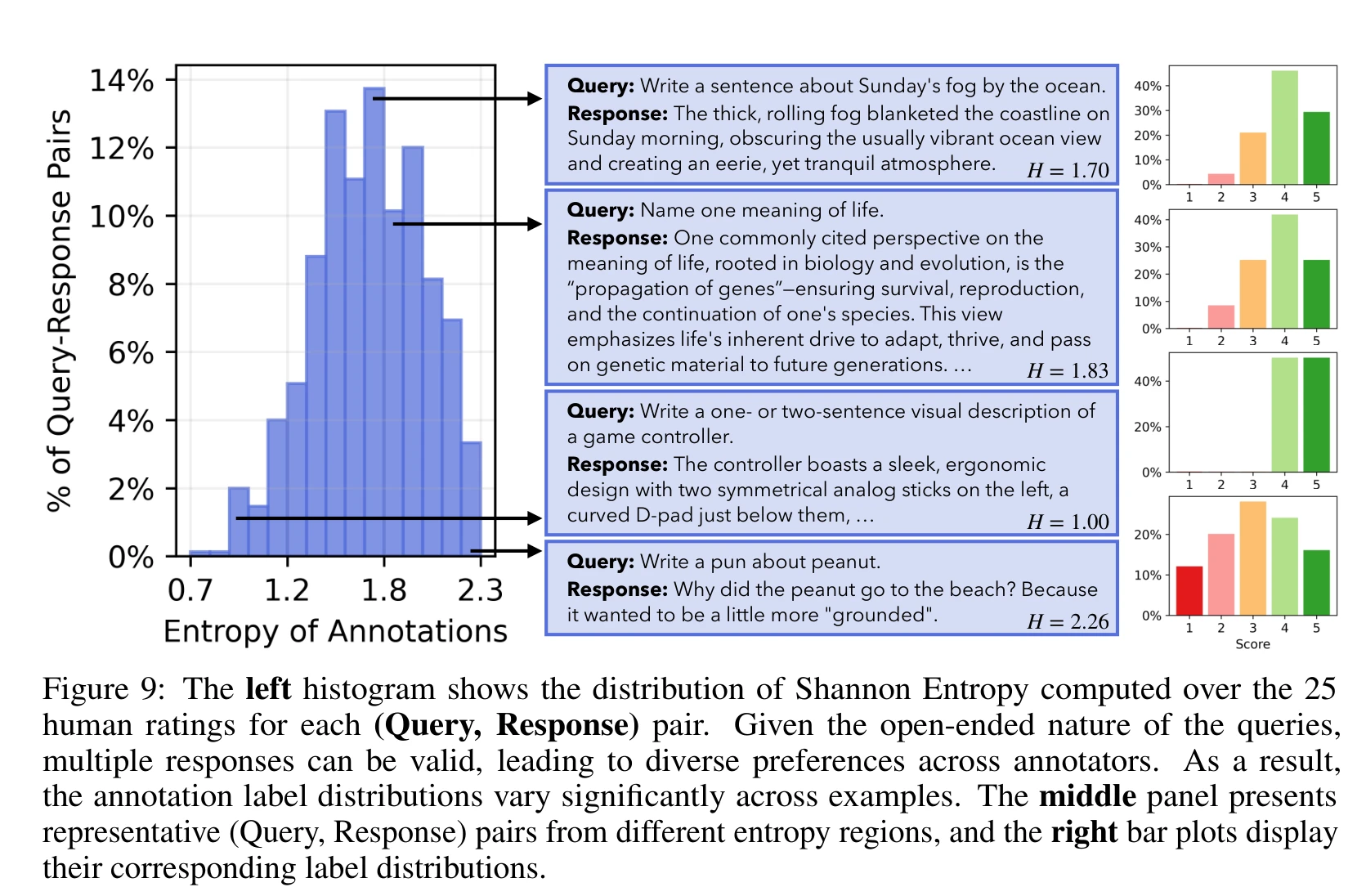
在标注者意见一致的问题上,奖励模型的校准度还行。但在标注者分歧大的问题上,校准度明显下降。论文在 56 个语言模型的困惑度评分、6 个 RewardBench 排名最高的奖励模型、4 个 LLM Judge(含 GPT-4o 和 Prometheus)上都观测到了这个趋势。
这跟同质化问题的关联在于:RLHF 用聚合偏好信号训练模型,等于把人类口味的多峰分布压成了单峰。你喜欢古典音乐,我喜欢实验电子,模型训练完一律推荐流行爵士,谁都不反感但谁都不满意。而奖励模型在需要区分"都不错但不同"的回答时,恰恰是最不可靠的——它给同质化的训练流程提供了一个有偏的信号源。
蜂巢思维的长期风险
推荐电影都推一样的,那只是体验层面的瑕疵。但语言模型正在进入写方案、做决策、参与教育这些需要多样性的场景。论文用了"long-term AI safety risks”,指向的不是模型失控,而是另一种隐患:长期高频使用同质化的思维工具,使用者自身的思考框架也会被逐渐收窄。
论文的主要贡献在诊断而非治疗。方向上能看到几条路:偏好建模从聚合走向个性化,训练数据对合成文本的去污染,以及在训练层面而非解码层面保障输出多样性。用标量奖励信号去优化一个本该多峰分布的输出空间,多样性的损失恐怕很难避免——这也许是当前对齐范式需要正视的结构性张力。
所有语言模型共用一套蜂巢审美,配方是互联网平均口味加标注者中位数偏好。下次让 AI 帮你想个创意方案的时候,记得你的竞争对手用的也是差不多的蜂巢。