Claude Code:1.6% 的 AI,98.4% 的脚手架
拆过 Claude Code 的记忆管理、上下文压缩、RAG、安全分类器、Edit 工具、子 Agent 缓存共享,每篇都是对着源码一行一行看。但看完这篇论文才意识到,我一直在看零件,没看整台机器。
论文叫 Dive into Claude Code: The Design Space of Today’s and Future AI Agent Systems ,46 页,从源码出发对 Claude Code 做了一次完整的架构解剖。不是使用教程,不是 benchmark 评测,而是回答一个工程问题:一个生产级 AI Agent 系统,代码到底在干什么?
1.6% 对 98.4%
论文最锋利的一个数字:Claude Code 的代码库里,只有 1.6% 是 AI 决策逻辑,剩下 98.4% 全是确定性的基础设施——权限门控、工具路由、上下文管理、异常恢复。
这个比例反映了一种设计哲学:不限制模型做什么决定,而是构建一个让模型能做好决定的环境。论文的说法是 “model judgment within a deterministic harness”。LangGraph 那类框架走的是另一条路,用显式的图节点和类型化边来约束模型的输出流向。Claude Code 反过来,给模型最大的决策自由度,把工程复杂性全投在脚手架上。
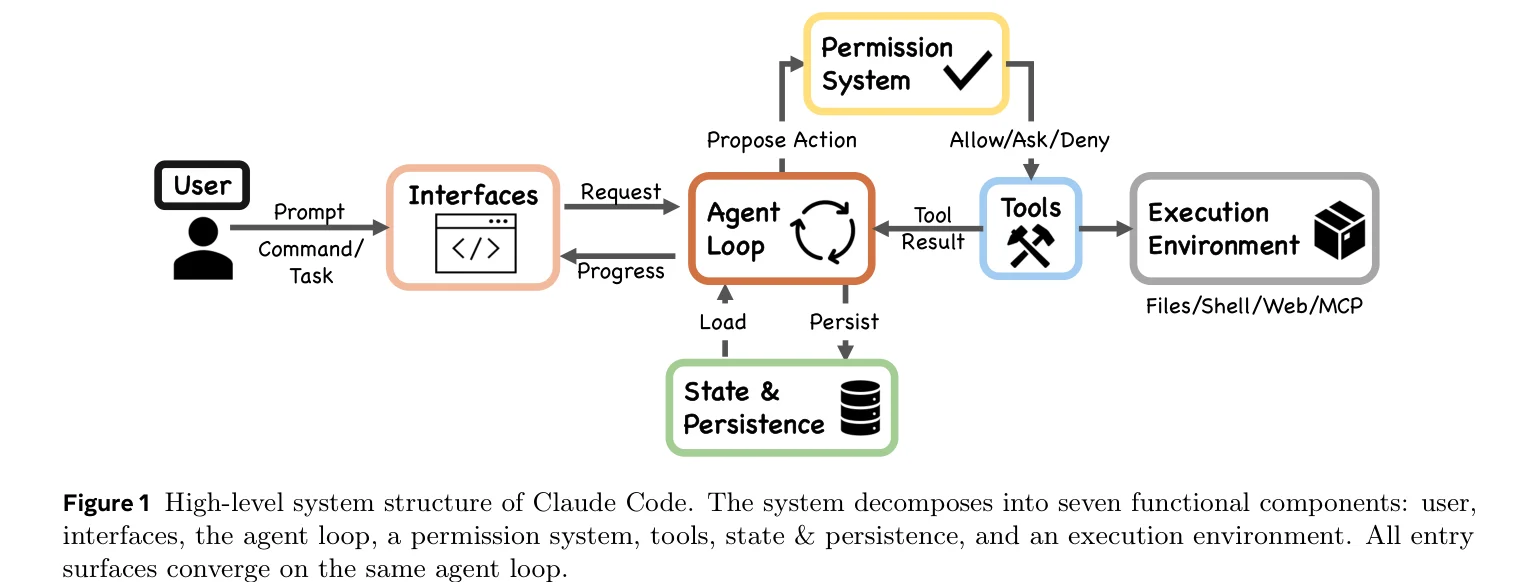
这也解释了为什么 Claude Code 的源码读起来大部分跟 AI 没什么关系。权限系统七层级联,上下文压缩五层管线,工具池组装五步流水线,扩展机制四种不同的上下文成本等级。所有这些都是确定性代码,不涉及任何模型推理。模型只在循环中间被调用一次,像一个无状态的补全端点。
一个 while 循环
整个 Agent 的核心是一个 while 循环,论文给了伪代码:
每轮三步:组装上下文(模型看到什么)、模型决策(模型能调用什么)、执行(是否允许执行、怎么执行)。三个注入点对应四种扩展机制:
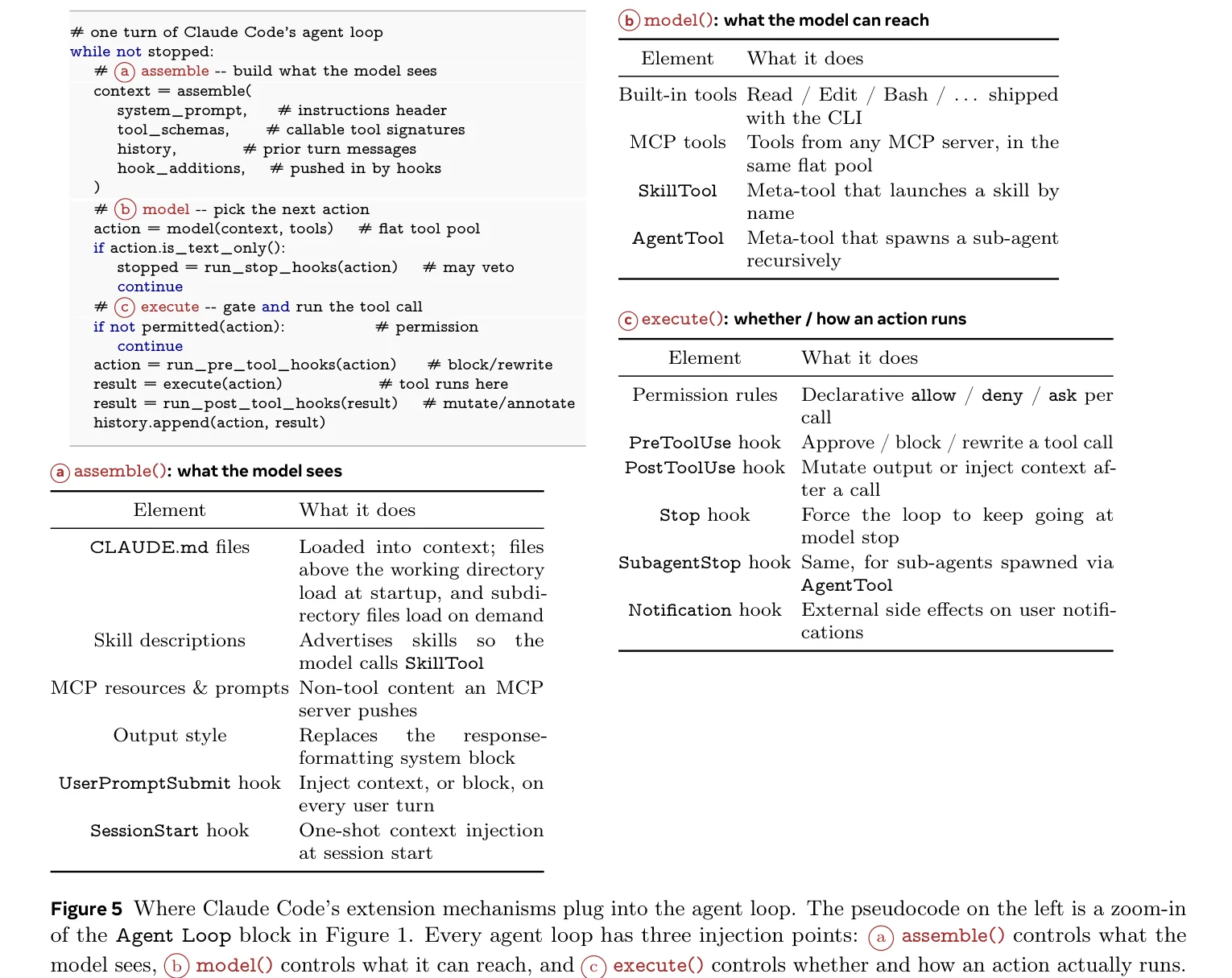
MCP Server 往工具池加工具(高上下文成本),Skill 往上下文注入指令(低成本),Hook 在执行前后拦截(零成本),Plugin 是前三种的打包分发格式。
为什么需要四种?因为不同类型的扩展对上下文窗口的消耗差异巨大。Hook 不占上下文,可以大量挂载;MCP 每注册一个工具就要塞一套 schema,必须节制。一种机制无法覆盖从零成本生命周期钩子到重量级工具服务的全部场景。
权限:七层安全和 93% 的批准率
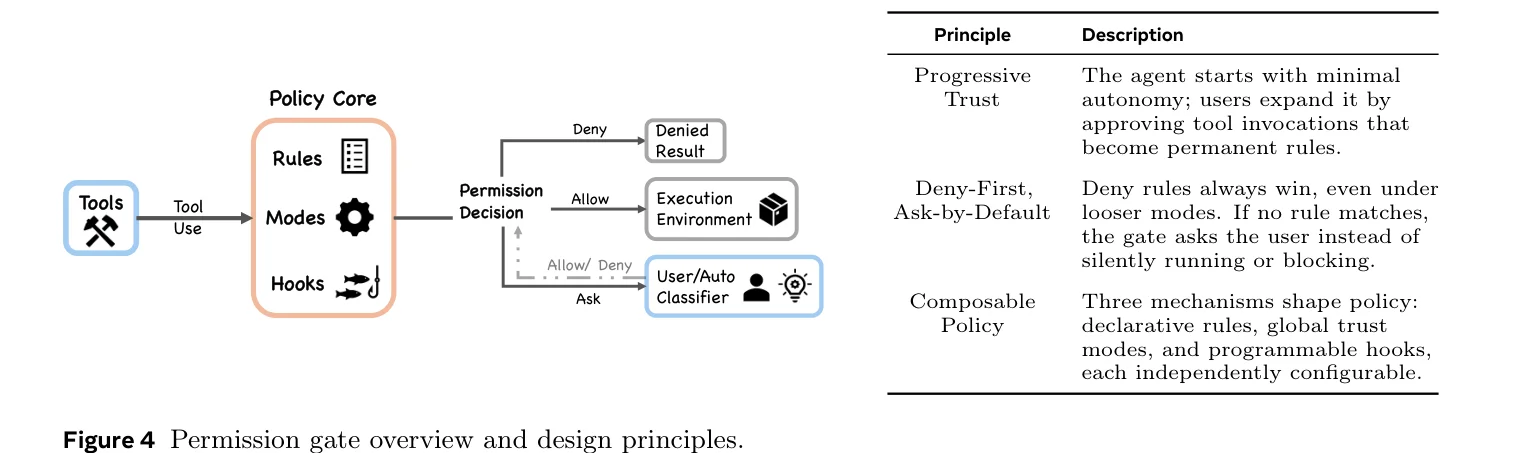
deny-first 的意思是默认拒绝一切,只有明确允许的操作才能执行。七个权限模式从 plan(用户批准所有操作)一路升到 bypassPermissions(跳过大部分提示)。deny-first 规则评估、ML 分类器、shell 沙箱、Hook 拦截,多层防御叠在一起。
但论文引了一个让人不安的数字:用户对权限提示的批准率大约 93%。长期使用数据显示,auto-approve 率从 50 次会话时的 20% 上升到 750 次会话时的 40% 以上。用久了之后,大部分人就是无脑点批准,交互式确认形同虚设。
论文的判断是,架构层面对这个问题的回应不是让用户更警觉,而是减少用户需要做决定的次数。沙箱引入后,权限提示频率下降了约 84%。
安全研究者也确实找到了实际漏洞。论文引用了四个已公开的安全漏洞(CVE),其中两个共享同一个根因:项目初始化阶段(Hook、MCP Server 连接、设置文件解析)的代码在信任对话框弹出之前就已经执行。这个时序窗口绕过了 deny-first 评估管线。论文把这个叫做 “pre-trust initialization ordering”,安全检查的每一层都在,但在时间上有一个窗口期,初始化代码跑在安全机制生效之前。
上下文管理
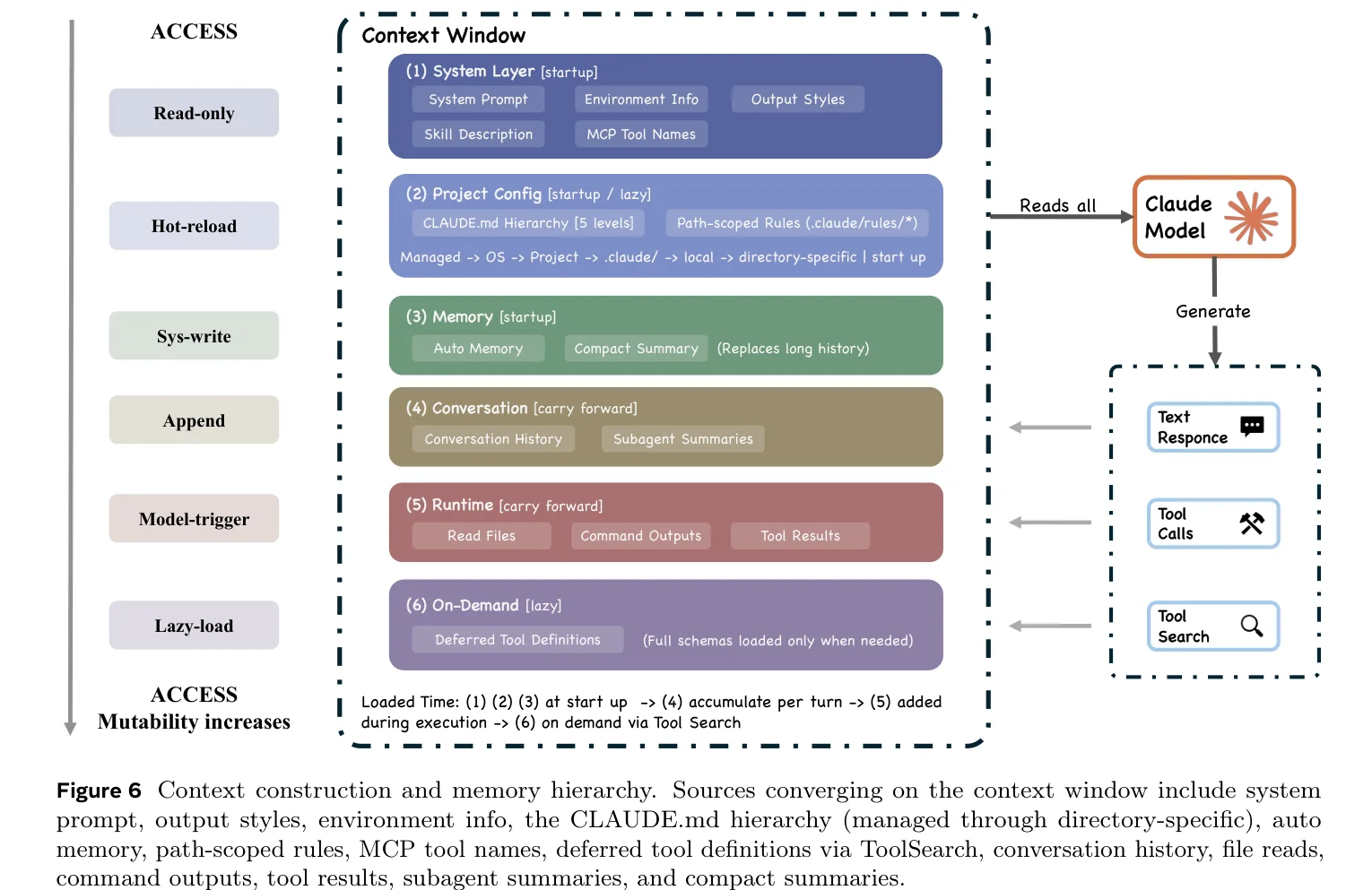
论文把上下文窗口类比为操作系统的内存管理,不是比喻,是结构性的相似。Claude Code 的五层压缩管线(budget reduction → snip → microcompact → context collapse → auto-compact)就像操作系统的分页和交换,用最低成本策略先处理,不够了才升级到更激进的方案。
每个子 Agent 拥有独立的上下文窗口,只有最终摘要返回父对话。Agent 团队模式下的 token 消耗约为标准会话的 7 倍,不做摘要隔离根本撑不住。
不过压缩都是有损的,而且五层压缩中的大部分对用户不可见。budget reduction 替换了长输出、context collapse 用摘要替代了原始消息、snip 裁剪了旧历史,丢了什么信息用户无从得知。
局部看都对,全局看不一定
论文做了一件挺有意思的事:从架构属性出发推导可测试的预测。有限的上下文窗口意味着模型永远无法同时感知整个代码库。五层压缩保留了最近和最相关的信息,但每层都引入信息损失。子 Agent 隔离意味着并行 Agent 可能独立重新实现已有的方案。
论文引用了两项外部研究来佐证:一项对 807 个代码库的因果分析发现,使用 Cursor 后代码复杂度上升 40.7%,初始速度提升在三个月内回落到基线;一项对 304,000 个 AI 提交的审计发现,约四分之一的 AI 引入问题持续到最新版本,安全问题的留存率更高。
这些研究针对的不是 Claude Code,但架构上的共性(有限上下文、工具使用循环、单次生成)让结论具有迁移性。论文的措辞很谨慎:“whether these mechanisms are sufficient to overcome the structural limitations of bounded context is a directly measurable empirical question”。
论文还用了整个 Section 10 把 Claude Code 和 OpenClaw 做对比。Claude Code 是临时 CLI 进程,绑定单个代码库;OpenClaw 是常驻 WebSocket 网关,连接二十多个消息平台。两个系统面对相同的设计问题给出了相反的答案:Claude Code 把安全放在每次工具调用上(deny-first),OpenClaw 把安全放在网关边界上(身份验证和访问控制)。Claude Code 的 Agent 循环是架构中心,OpenClaw 的 Agent 循环是网关控制平面的一个组件。
有意思的是两者可以叠在一起用。OpenClaw 通过 ACP(Agent Client Protocol,Agent 间的通信协议)把 Claude Code 作为外部编码工具来调用。AI Agent 的设计空间不是一个扁平分类,而是分层的,网关级系统和任务级工具可以组合。
再说说价值观的拧巴
论文最后讨论了五个价值之间的张力,比 Agent 架构本身更值得想。Authority(用户控制)和 Safety(系统保护)之间有结构性冲突:93% 的批准率说明人类监督在疲劳下不可靠,但如果系统完全自动决策又失去了人类兜底。Capability(能力)和 Reliability(可靠性)之间也有:有限上下文让模型做出好的局部决策,但局部最优不等于全局最优。
论文还引了一项随机对照实验,16 位资深开发者使用 AI 工具后效率下降 19%,尽管他们自己感觉提升了 20%。一项脑电图研究发现 LLM 用户的神经连接在停用 AI 后仍然减弱。这些问题跟 Claude Code 的具体架构关系不大,任何 Agent 系统都得面对。
论文用了一个类比:Agent 架构正在收敛为操作系统式的抽象,核心循环是内核,其余一切是 OS。如果这个方向是对的,那 1.6% 对 98.4% 的比例大概不只是 Claude Code 一家的情况。