向量检索的理论天花板
向量检索(dense retrieval)这几年几乎成了 RAG 的标配。把文档编码成一个向量,查询也编码成一个向量,算个余弦相似度就能检索。但一个基本问题很少被认真讨论过:一个 d 维向量,到底能表示多少种不同的 top-k 检索结果?
ICLR 2026 这篇来自 Google DeepMind 和 JHU 的论文 “On the Theoretical Limitations of Embedding-Based Retrieval” 给出了一个数学上的回答:不够。而且远远不够。
论文地址: arxiv.org/abs/2508.21038
维度下界:一个组合爆炸的问题
先建立直觉。假设有 n 篇文档,每次检索返回 top-k 篇。所有可能的 top-k 组合数量是 $\binom{n}{k}$,当 n 和 k 都不小时,这个数字增长极快。
每种 top-k 组合要被某个查询向量"实现",就需要在向量空间里存在一个查询点,使得这 k 篇文档的得分比其他所有文档都高出一个 margin $\gamma$。论文的 Theorem 1 证明了:
$$d \geq \frac{\log \binom{n}{k}}{\log(1 + 1/\gamma)}$$
这个下界的含义很直接:要让 d 维向量能表示所有可能的 top-k 组合,维度 d 至少要这么大。
用 $\gamma = 0.1$ 代入看看具体数字:
| 文档数 n | k=2 | k=10 | k=100 | k=1000 |
|---|---|---|---|---|
| $10^3$ | 6 | 23 | 135 | - |
| $10^5$ | 10 | 42 | 329 | 2334 |
| $10^7$ | 14 | 61 | 521 | 4257 |
| $10^9$ | 17 | 81 | 713 | 6177 |
当前主流模型的最大维度是 4096(Qwen3 Embed),多数场景还会用 MRL 截断到 1024 甚至更低。对照表格,n 到百万量级、k=100 时,理论下界已经接近甚至超过 4096。而这还只是一个极端宽松的下界。
Free Embedding:最理想条件下的表现
理论下界是"至少需要这么多维",实际模型受限于梯度下降、分词器、语言建模等约束,可能需要更多。但具体多多少?
论文设计了一个"free embedding"实验来回答这个问题。做法是:不用任何语言模型,直接把查询和文档的向量当作可优化参数,在测试集的 qrel 矩阵上用 InfoNCE 损失做梯度优化。这是一个理论上的最优情况,因为向量可以自由摆放,不受自然语言约束。
实验固定 k=2,逐渐增大文档数 n,找到每个维度 d 下能 100% 解决所有 top-2 组合的最大 n(称为 critical-n)。
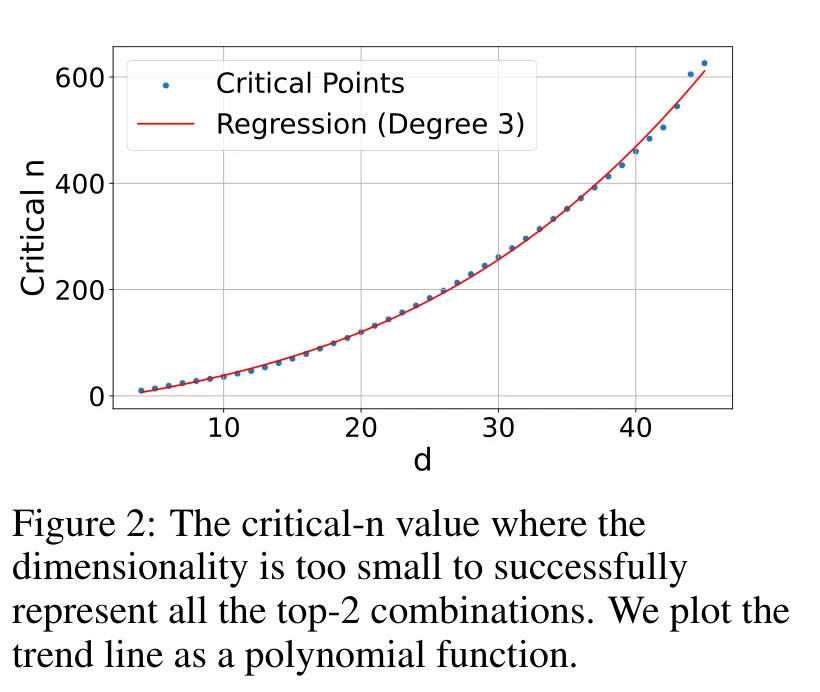
这条曲线拟合为三次多项式 $y = -10.53 + 4.03d + 0.052d^2 + 0.0037d^3$,$r^2 = 0.999$。外推到常见维度:
- d=512 → critical-n 约 50 万
- d=1024 → 约 400 万
- d=3072 → 约 1.07 亿
- d=4096 → 约 2.5 亿
这些数字看起来不小,但要注意:这是 k=2 的情况,而且是直接在测试集上优化、没有任何泛化要求的理想场景。真实模型的 critical-n 会低得多。论文也验证了这一点:理论下界说 n=100 时 d=4 就够,但 free embedding 实际需要 d>18,差了 4.5 倍。
LIMIT 数据集:最简单的查询,SOTA 全面失败
理论和 free embedding 都还是抽象的。为了在真实语言上验证,论文构造了 LIMIT 数据集。
构造方法很巧妙。每篇文档是一个虚构人名加上一组随机属性,比如"Jon Durben likes Quokkas, Apples, and Scuba Diving"。查询形式都是"Who likes X?",答案恰好是 2 篇文档(k=2)。
核心设计思路是这样的:论文想让数据集尽可能难,就需要覆盖所有可能的 top-2 组合。具体来说,选出 46 篇核心文档,为每一对文档分配一个独特的属性词——这两篇文档共享这个词,别的文档没有。这样每条"Who likes X?“查询恰好有 2 篇相关文档,而 $\binom{46}{2} = 1035$ 对组合就产生了 1035 条查询(论文取约 1000 条)。这意味着向量模型必须能区分所有 1035 种不同的 top-2 集合,每种对应不同的两篇文档。再加上 49954 篇不和任何查询相关的干扰文档,总共 50000 篇。

查询和文档之间是简单的词汇匹配任务,任何人看一眼就能答对。但 SOTA 向量模型的表现:
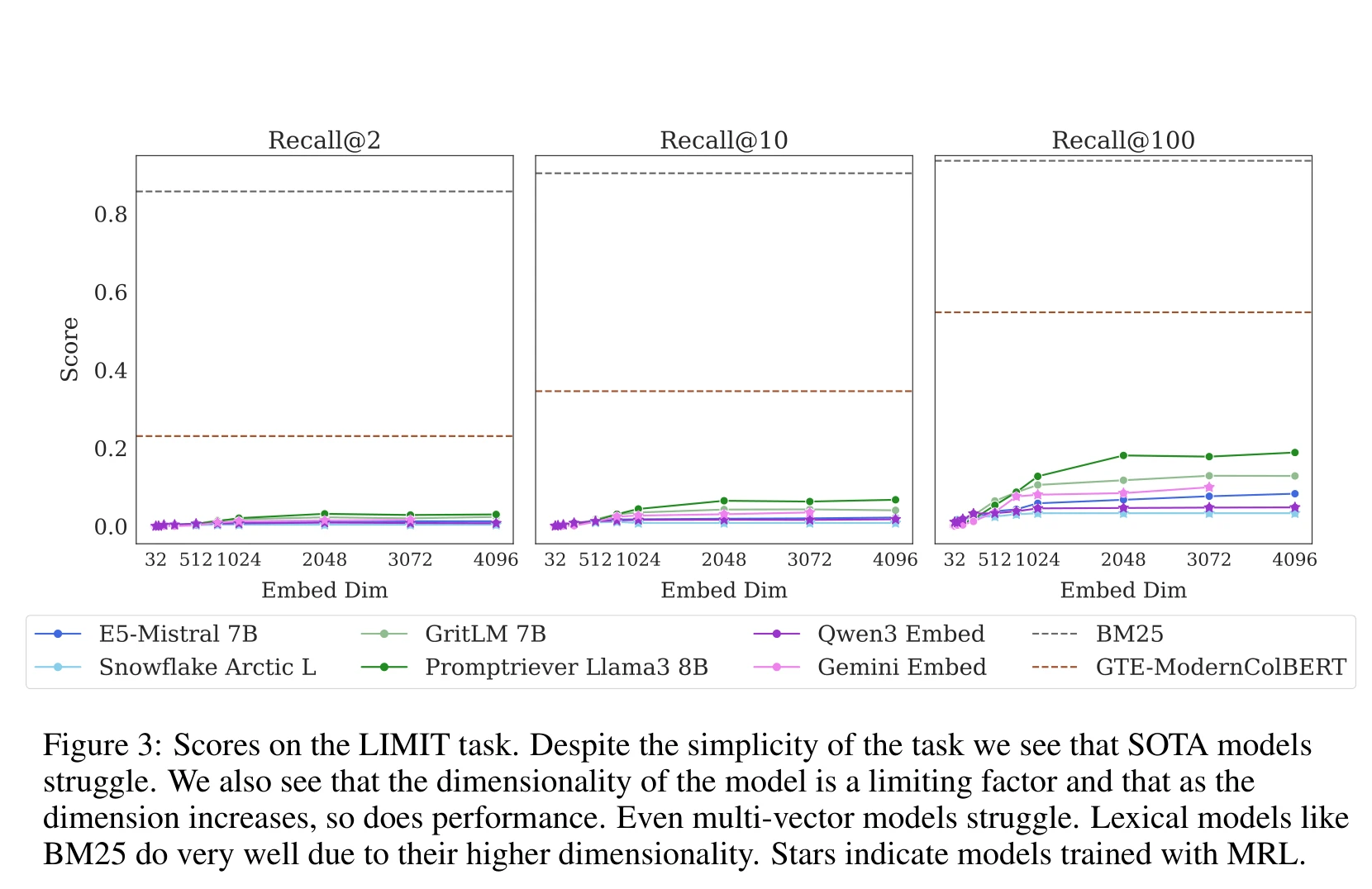
在全量 50k 文档的设置下,所有单向量模型的 Recall@2 都不到 5%——最好的 Promptriever 8B(维度 4096)也只有 3.0%,Qwen3 Embed 只有 0.8%。即使放宽到 Recall@100,最好也不过 18.9%。对于一个人类一眼就能答对的检索任务,最强的向量模型几乎完全失败。
在只有 46 篇文档的小版本上,结果依然不好:
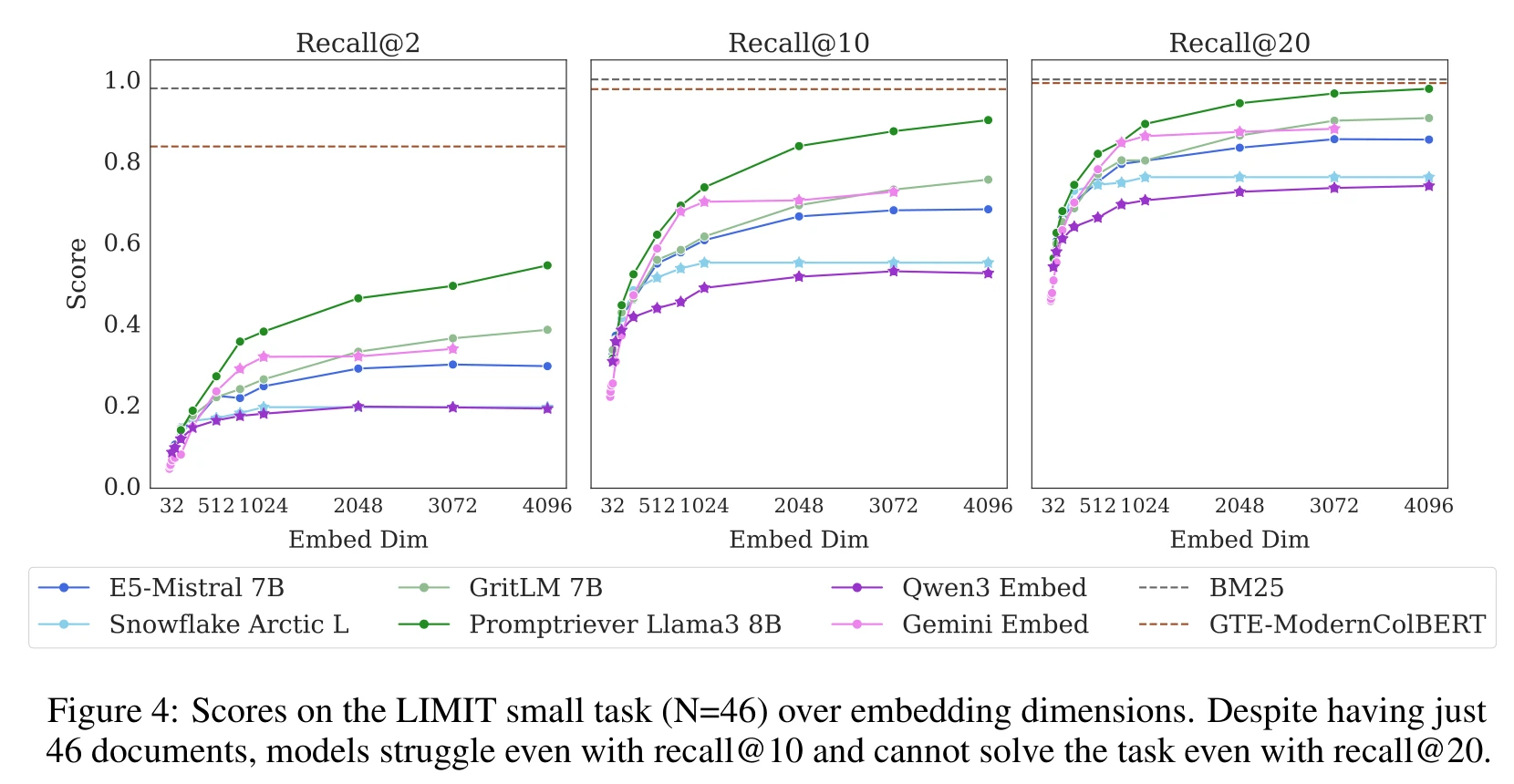
即使只从 46 篇文档里找 2 篇,Promptriever 4096 维 Recall@2 也只有 54.3%,Qwen3 Embed 只有 19.0%。Recall@20 都不到 100%——返回 20 篇都不一定能包含正确答案。
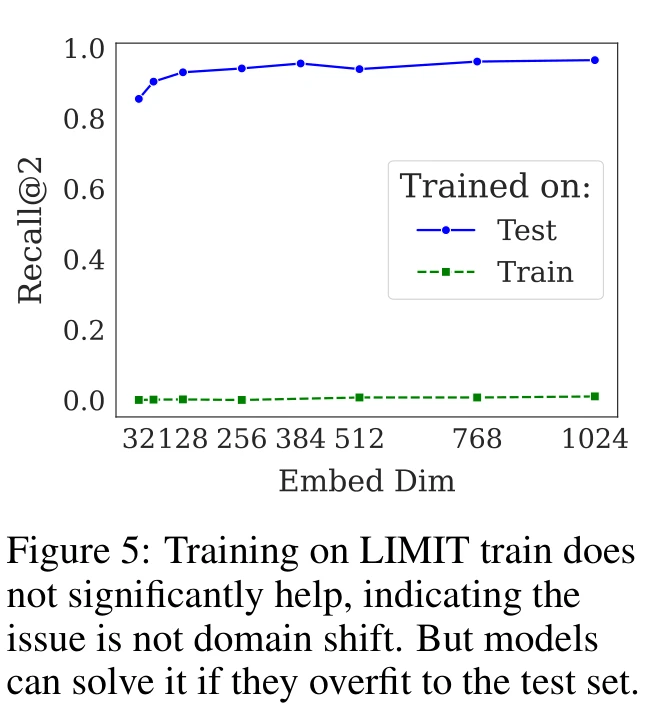
论文还排除了"领域偏移"的解释。用 LIMIT 训练集微调模型后,效果几乎没有提升(Recall@10 从约 0 到 2.8)。但如果直接在测试集上微调,模型可以过拟合到接近 100%。这说明问题不在数据分布,而在向量表示能力本身。
BM25 赢了,但也不是答案
一个有趣的发现:BM25 在 LIMIT 上接近满分(Recall@2 = 97.8%)。原因很简单,BM25 的"维度"等于词表大小,远高于向量模型的几千维,在这个词汇匹配任务上天然占优。
但这不代表稀疏模型就能解决问题。论文做了一个同义词实验:把 LIMIT 文档里的属性替换成同义词(比如"glasses"改成"spectacles”),查询保持不变。
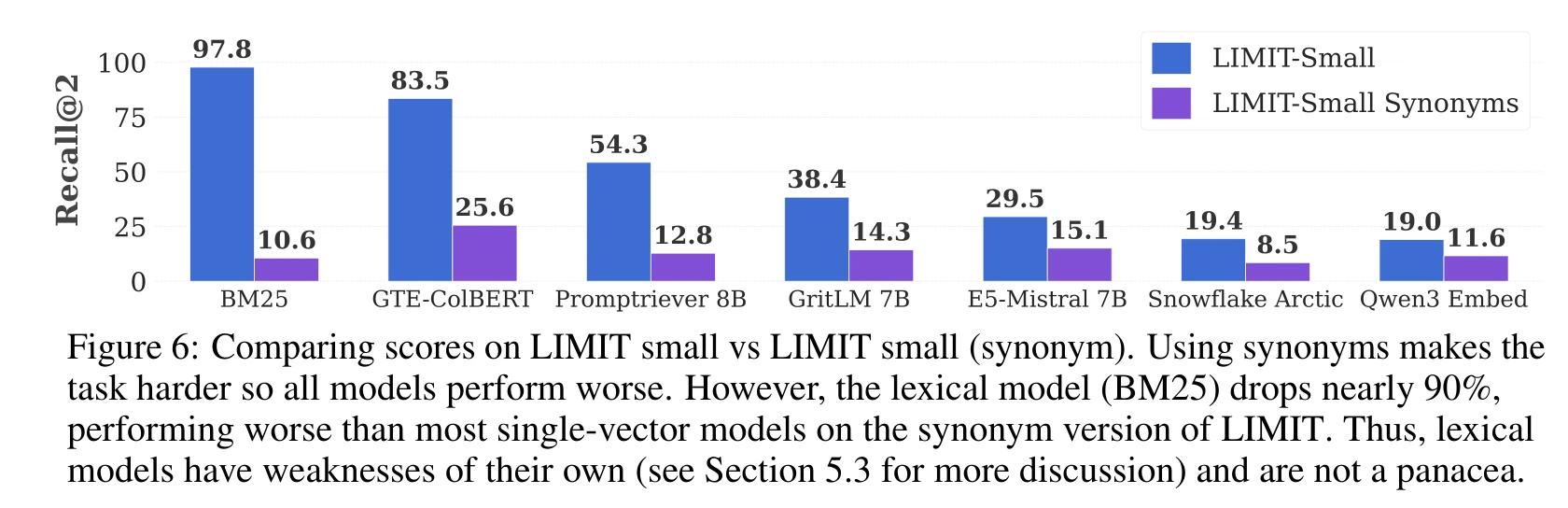
BM25 的 Recall@2 从 97.8% 暴跌到 10.6%,下降了近 90%。向量模型虽然也下降,但幅度小得多(Qwen3 Embed 下降 38.9%)。所以 BM25 的高分只是因为这个特定数据集恰好全是精确词汇匹配,换成语义匹配场景就露馅了。
其他架构的表现
Cross-encoder:Gemini 2.5 Pro 作为重排器,在 46 篇文档的小版本上一次性解决全部 1000 条查询,正确率 100%。Cross-encoder 不受嵌入维度限制,因为它对每个 query-document pair 做独立打分,表达能力远强于单向量。代价是不能做大规模第一阶段检索。
Multi-vector 模型:GTE-ModernColBERT(ColBERT 架构)在 LIMIT 上大幅优于单向量模型(Recall@2 = 83.5%),但离满分还差不少。多向量模型用了更多参数来表示每个文档(每个 token 一个向量 + MaxSim),有更强的表达能力,但在高密度组合场景下仍然有限。
对 RAG 和实际应用的启示
这篇论文的核心信息是:单向量检索有一个硬性的组合上限,不是靠更好的训练数据或更大的模型能解决的。
对做 RAG 系统的人来说,几个直接的含义:
当查询的 relevance 定义变得复杂(指令跟随、逻辑组合、推理型查询),需要覆盖的 top-k 组合数量会快速膨胀,向量检索会越来越力不从心。这跟模型质量无关,是表示能力的物理限制。
BM25 和向量检索的互补不是锦上添花,是必要的。两者的弱点恰好互补:BM25 高维但只能做词汇匹配,向量模型低维但能做语义匹配。
对于需要高覆盖率的关键场景(比如法律、医疗文档检索),单纯依赖向量检索可能存在系统性盲区。Cross-encoder 重排或多向量模型是必要的补充,而不只是"锦上添花"。
论文最后也坦承了局限:理论结果只适用于单向量模型,无法直接推广到多向量架构;也没有给出"允许部分错误"情况下的维度界。这些留给了后续研究。