Building Large-Scale Social Network Graphs with MongoDB
Nowadays, many popular apps incorporate social network features, such as Twitter, WhatsApp, and Facebook. These platforms need to scale to accommodate billions of users (graph nodes), which is no small feat. Building and maintaining a scalable social network infrastructure requires careful planning and strategic data modeling. In fact, specialized social networking applications like Facebook have dedicated teams focusing solely on optimizing their performance to the highest level. However, for smaller apps or startup projects looking to add social networking capabilities, creating a full team to handle such architecture is often impractical and unnecessary.
So, is it possible to build a high-performance, scalable social network using the right data modeling and storage solutions? The answer is yes. Early versions of Facebook used MySQL as the underlying storage to construct their social network, but today we have more advanced and efficient storage options available: MongoDB.
Problem Description and Challenges
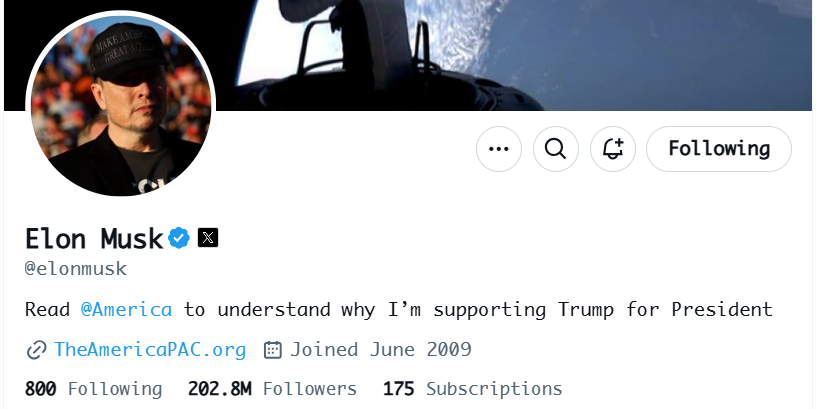
To begin, let’s outline and simplify the problem. Our goal is to build a social network where any user can follow other users. Each user should be able to view whom they are following, who follows them, and the counts for both. For example, on Twitter, Elon Musk’s profile shows that he follows 800 people and has 202.8M followers.
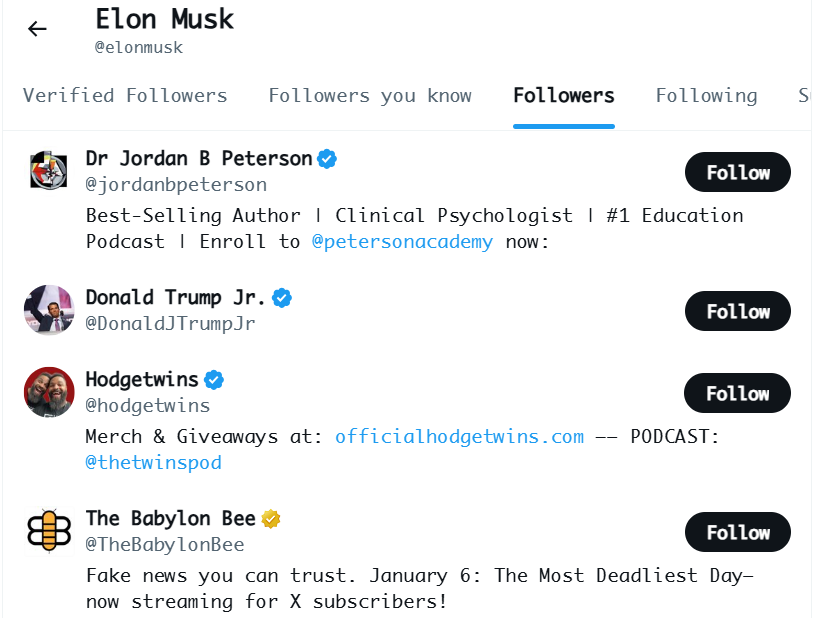
By opening his followers' page, you can see detailed information about each follower, such as Dr. Jordan B. Peterson and others.
After simplifying the problem, we need to support the following core functionalities: following and unfollowing users, viewing the count of followers and following, and viewing the list of followers or the people a user follows. It's worth noting that since many celebrities have an enormous number of followers, Twitter only allows viewing a limited number of follower profiles.
While these features may seem straightforward, scaling them to handle billions of users presents significant challenges. Reading and updating the social relationships between users becomes an extremely frequent operation, raising the question: can the data model and underlying storage support such massive data volume and the high QPS (queries per second) required for a high-concurrency environment?
Data Modeling and Scalability
To achieve the above functionalities, data modeling is the key. The following six APIs are needed:
api/Follow
api/Unfollow
api/GetFollowers
api/GetFollowings
api/GetFollowerCount
api/GetFollowingCountAssuming each user is represented by a UUID, a straightforward data modeling approach would be to store two records for each relationship. Each record represents a directional relationship, such as:
| SrcUuid | DstUuid | Status | Notes |
|---|---|---|---|
| u1 | u2 | Follow | u1关注了u2 |
| u2 | u1 | Follow | u2关注了u1 |
| u3 | u4 | Follow | u3关注了u4 |
Since u1 follows u2, and u2 follows u1, u1 and u2 have a mutual following relationship. On the other hand, if u3 follows u4 and there's only one record, then it represents a one-way following relationship.
With this type of data modeling, implementing follow and unfollow
operations becomes straightforward, as it only involves inserting or
deleting a record. Retrieving a user's followers can be accomplished
using a query like DstUuid == x, while counting the number
of followers can be done with Count(DstUuid == x). The same
applies for finding who a user is following.
Thus, a single table can be used to store the relationship data between users, defined as follows:
public class FollowEntry
{
public string SrcUuid { get; set; }
public string DstUuid { get; set; }
public FollowStatus Status { get; set; }
public DateTime CreateTime { get; set; }
public DateTime UpdateTime { get; set; }
}
public enum FollowStatus
{
None = 0,
Follow = 1
}How Can This Data Model Scale to Millions of Users?
The answer lies in leveraging sharding and replicaset nodes for scalability. Sharding enhances write capabilities by distributing data across multiple shards, while adding replicaset nodes increases read capacity. This scaling approach is transparent to the upper-layer application, unlike MySQL's sharding and partitioning, which can impose constraints on application queries. This is one of the advantages of using MongoDB.
System Implementation
In this section, we will implement each API and identify the required indexes and shard keys based on actual read patterns.
Follow API
The implementation of the Follow API is straightforward: it involves an upsert operation to insert or update a follow record, regardless of whether the record previously existed or its status:
Follow API
The implementation of the Follow API is quite simple. It involves performing an upsert operation to insert or update a follow record, regardless of whether the record already exists or its previous status:
public async Task FollowAsync(string srcUuid, string dstUuid)
{
using (var cts = new CancellationTokenSource(TimeSpan.FromSeconds(5)))
{
var update = Builders<FollowEntry>.Update
.Set(x => x.Status, FollowStatus.Follow)
.Set(x => x.UpdateTime, DateTime.UtcNow)
.SetOnInsert(x => x.SrcUuid, srcUuid)
.SetOnInsert(x => x.DstUuid, dstUuid)
.SetOnInsert(x => x.CreateTime, DateTime.UtcNow);
var option = new UpdateOptions { IsUpsert = true };
await _followCollection.UpdateOneAsync(x => x.SrcUuid == srcUuid && x.DstUuid == dstUuid, update, option, cts.Token);
}
}The implementation of the Unfollow API is similar to the Follow API,
with the only difference being that the FollowStatus is set
to None to indicate that the user has unfollowed.
Both the Follow and Unfollow APIs require an index:
(SrcUuid, DstUuid).
GetFollowers API
The implementation of the GetFollowers API needs to consider
pagination and a maximum return limit. Here’s a straightforward approach
that returns the earliest n followers based on their
creation timestamp:
public async Task<List<FollowEntry>> GetFollowersAsync(string uuid, int n = 10)
{
using (var cts = new CancellationTokenSource(TimeSpan.FromSeconds(5)))
{
var result = await _followCollection.Find(x => x.DstUuid == uuid && x.Status == FollowStatus.Follow).SortBy(x => x.CreateTime).Limit(n).ToListAsync(cts.Token);
return result;
}
}The implementation of the GetFollowings API is similar to the
GetFollowers API: Simply replace DstUuid with
SrcUuid.
These two APIs require indexes:
(DstUuid, FlowStatus, CreateTime) and
(SrcUuid, FlowStatus, CreateTime). The inclusion of the low
cardinality field FollowStatus in the indexes is beneficial
because, over time, there may be many unfollow entries present in the
dataset. By indexing this field, query performance can improve,
especially when filtering for active relationships. However, it's
important to choose indexes based on the specific application scenarios,
as unnecessary indexes can lead to increased overhead during write
operations.
GetFollowerCount API
The implementation of the GetFollowerCount API:
public async Task<long> GetFollowerCountAsync(string uuid)
{
using (var cts = new CancellationTokenSource(TimeSpan.FromSeconds(5)))
{
var result = await _followCollection.CountDocumentsAsync(x => x.DstUuid == uuid
&& x.Status == FollowStatus.Follow, cancellationToken: cts.Token);
return result;
}
}The implementation of the GetFollowingCount API is similar. Simply
replace DstUuid with SrcUuid.
These two APIs can reuse the indexes established for the GetFollowers and GetFollowings APIs.
Indexes and Shard Keys
Based on the above implementations and considering the leftmost prefix matching principle, we need three indexes:
- (SrcUuid, DstUuid)
- (DstUuid, FlowStatus, CreateTime)
- (SrcUuid, FlowStatus, CreateTime)
At the same time, these indexes can also support APIs such as "GetTwoUserRelationship()", which will not be elaborated on further.
Considering that user IDs use UUIDs, which are already uniformly
distributed, there is no need to use hashed sharding. We only need to
consider which is more commonly used in the application context:
GetFollowers or GetFollowings. Assuming GetFollowings is more commonly
used, we can choose SrcUuid as the shard key. This ensures
that all users followed by a given user reside in the same shard,
improving read efficiency.
Sharding can be executed in the MongoDB shell with:
sh.shardCollection("Test.Test", { "SrcUuid": 1 })
Sharded clusters can significantly increase the upper limits of the system, and they do not require code modifications; the capacity of the system can be expanded online.
Test Code
Randomly generate 1,000 users and 2,000 follow relationships, and print the follower information for one user who has more than 5 followers.
public async Task RunAsync()
{
var rand = new Random(0);
var userList = new List<string>();
// Generate 1000 users
for (int i = 0; i < 1000; ++i)
{
userList.Add(Guid.NewGuid().ToString("N").ToUpper());
}
// Generate 2000 relationships
for (int i = 0; i < 2000; ++i)
{
var src = userList[rand.Next(userList.Count)];
var dst = userList[rand.Next(userList.Count)];
if (src == dst) continue;
await FollowAsync(src, dst);
}
foreach (var user in userList)
{
var followerCount = await GetFollowerCountAsync(user);
if (followerCount > 5)
{
var followers = await GetFollowersAsync(user, 5);
foreach (var entry in followers)
{
Console.WriteLine($"{entry.SrcUuid} follows {user} at {entry.CreateTime}");
}
Console.WriteLine($"{user} followers: {followerCount}");
break;
}
}
}The results:
7289820430DA4BCD930CFE1067A3DC89 follows 5798C300560A4C09B35F7B48AF57ACF5 at 11/4/2024 1:41:57 PM F2E95841840C45B496C6629181DD2C77 follows 5798C300560A4C09B35F7B48AF57ACF5 at 11/4/2024 1:42:05 PM 7FFB5DE3E3A94AFF8AB487EA82DA2A68 follows 5798C300560A4C09B35F7B48AF57ACF5 at 11/4/2024 1:42:07 PM AE9D38F638C145848997F2E0E8BF62DF follows 5798C300560A4C09B35F7B48AF57ACF5 at 11/4/2024 1:42:09 PM 4E15001E616E441395FBC04CA0F3F36E follows 5798C300560A4C09B35F7B48AF57ACF5 at 11/4/2024 1:42:10 PM 5798C300560A4C09B35F7B48AF57ACF5 followers: 8 Done
Connect to the database deployed on MongoDB Atlas using MongoDB Compass:
Discussion and Optimization
The social relationship data modeling introduced in this article is a simplified design aimed at demonstrating how to utilize MongoDB's sharded cluster to build a large-scale social network graph. In a real production environment, there are several issues that need to be considered and optimized:
Write-heavy or Read-heavy: Here, we use user IDs to represent users, concealing user information. The actual implementation would require APIs for bulk reading of user information. If user details are included in the
FollowEntry, it would improve read efficiency but significantly lower update efficiency (Write-heavy). The current design transitions a write-heavy model into a read-heavy model by fetching the latest user information in real-time.Caching: Although MongoDB offers excellent performance, front-end caching (such as Redis) is still essential and can greatly enhance system throughput. This is particularly important for APIs like
GetFollowersCount, where caching an approximate count is crucial for efficiency.Support for Complex Business Logic: The scenarios for platforms like Twitter are much more complex than those described here. They must consider not only social relationships but also the read/write interactions of each tweet and the integration with recommendation systems. Due to space limitations, a deeper discussion on this topic is not provided.
Load testing confirms that the optimized social relationship system can support 100,000+ or even higher QPS, demonstrating excellent performance and throughput. This makes it very suitable for startups looking to rapidly develop and iterate their products.
Full Demo
Fill the ConnectionString:
using MongoDB.Bson.Serialization.Conventions;
using MongoDB.Driver;
namespace MongoTest
{
class Program
{
static void Main(string[] args)
{
var model = new RelModel();
model.RunAsync().Wait();
Console.WriteLine("Done");
}
}
public class FollowEntry
{
public string SrcUuid { get; set; }
public string DstUuid { get; set; }
public FollowStatus Status { get; set; }
public DateTime CreateTime { get; set; }
public DateTime UpdateTime { get; set; }
}
public enum FollowStatus
{
None = 0,
Follow = 1,
Deleted = 2
}
public class RelModel
{
private readonly IMongoClient _mongoClient;
private readonly IMongoCollection<FollowEntry> _followCollection;
private const string DatabaseName = "Test";
private const string CollectionName = "Test";
public const string ConnectionString = "";
public RelModel()
{
_mongoClient = new MongoClient(ConnectionString);
var database = _mongoClient.GetDatabase(DatabaseName);
var ignoreExtraElementsConvention = new ConventionPack { new IgnoreExtraElementsConvention(true) };
ConventionRegistry.Register("IgnoreExtraElements", ignoreExtraElementsConvention, type => true);
_followCollection = database.GetCollection<FollowEntry>(CollectionName);
}
public async Task RunAsync()
{
var rand = new Random(0);
var userList = new List<string>();
// Generate 1000 users
for (int i = 0; i < 1000; ++i)
{
userList.Add(Guid.NewGuid().ToString("N").ToUpper());
}
// Generate 2000 relationships
for (int i = 0; i < 2000; ++i)
{
var src = userList[rand.Next(userList.Count)];
var dst = userList[rand.Next(userList.Count)];
if (src == dst) continue;
await FollowAsync(src, dst);
}
foreach (var user in userList)
{
var followerCount = await GetFollowerCountAsync(user);
if (followerCount > 5)
{
var followers = await GetFollowersAsync(user, 5);
foreach (var entry in followers)
{
Console.WriteLine($"{entry.SrcUuid} follows {user} at {entry.CreateTime}");
}
Console.WriteLine($"{user} followers: {followerCount}");
break;
}
}
}
public async Task FollowAsync(string srcUuid, string dstUuid)
{
using (var cts = new CancellationTokenSource(TimeSpan.FromSeconds(5)))
{
var update = Builders<FollowEntry>.Update
.Set(x => x.Status, FollowStatus.Follow)
.Set(x => x.UpdateTime, DateTime.UtcNow)
.SetOnInsert(x => x.SrcUuid, srcUuid)
.SetOnInsert(x => x.DstUuid, dstUuid)
.SetOnInsert(x => x.CreateTime, DateTime.UtcNow);
var option = new UpdateOptions { IsUpsert = true };
await _followCollection.UpdateOneAsync(x => x.SrcUuid == srcUuid && x.DstUuid == dstUuid, update, option, cts.Token);
}
}
public async Task<List<FollowEntry>> GetFollowersAsync(string uuid, int n = 10)
{
using (var cts = new CancellationTokenSource(TimeSpan.FromSeconds(5)))
{
var result = await _followCollection.Find(x => x.DstUuid == uuid && x.Status == FollowStatus.Follow).SortBy(x => x.CreateTime).Limit(n).ToListAsync(cts.Token);
return result;
}
}
public async Task<long> GetFollowerCountAsync(string uuid)
{
using (var cts = new CancellationTokenSource(TimeSpan.FromSeconds(5)))
{
var result = await _followCollection.CountDocumentsAsync(x => x.DstUuid == uuid
&& x.Status == FollowStatus.Follow, cancellationToken: cts.Token);
return result;
}
}
}
}