Claude Code: 1.6% AI, 98.4% Scaffolding
I’ve written about Claude Code’s memory management, context compaction, RAG, security classifier, Edit tool, and sub-agent cache sharing — each time reading the source code line by line. But after reading this paper, I realized I’d been looking at individual parts without seeing the whole machine.
The paper is Dive into Claude Code: The Design Space of Today’s and Future AI Agent Systems , 46 pages, a complete architectural dissection of Claude Code from source code. Not a usage tutorial, not a benchmark evaluation, but an answer to an engineering question: what is a production AI agent system’s code actually doing?
1.6% vs. 98.4%
The paper’s sharpest number: only 1.6% of Claude Code’s codebase is AI decision logic. The remaining 98.4% is deterministic infrastructure — permission gates, tool routing, context management, error recovery.
This ratio reflects a design philosophy: don’t constrain what the model decides, build an environment where the model can decide well. The paper calls it “model judgment within a deterministic harness.” Frameworks like LangGraph take a different path, using explicit graph nodes and typed edges to constrain model output flow. Claude Code does the opposite — maximum decision latitude for the model, all engineering complexity invested in the scaffolding.
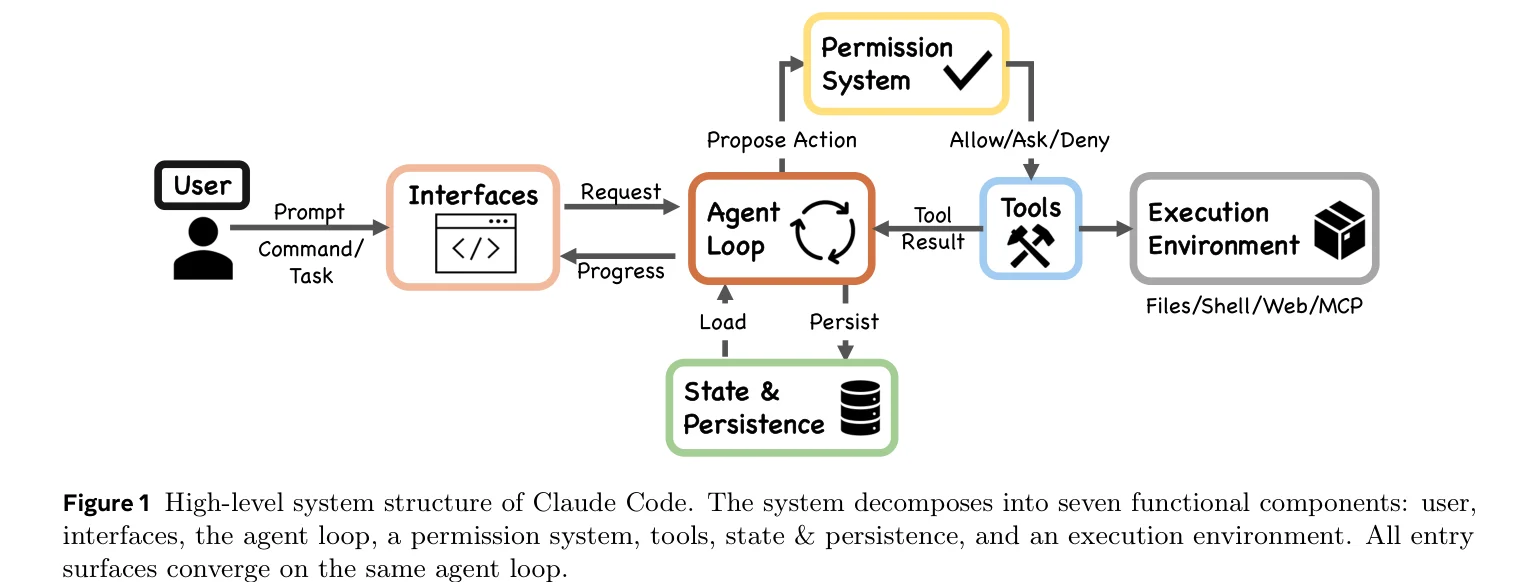
This also explains why most of Claude Code’s source reads like it has nothing to do with AI. Seven-layer permission cascade, five-layer compaction pipeline, five-step tool pool assembly, four extension mechanisms at different context cost tiers. All deterministic code, no model inference involved. The model gets called once per loop iteration, like a stateless completion endpoint.
One while Loop
The entire agent’s core is a while loop. The paper provides pseudocode:
Three steps per turn: assemble context (what the model sees), model decision (what the model can call), execution (whether and how it runs). Three injection points map to four extension mechanisms:
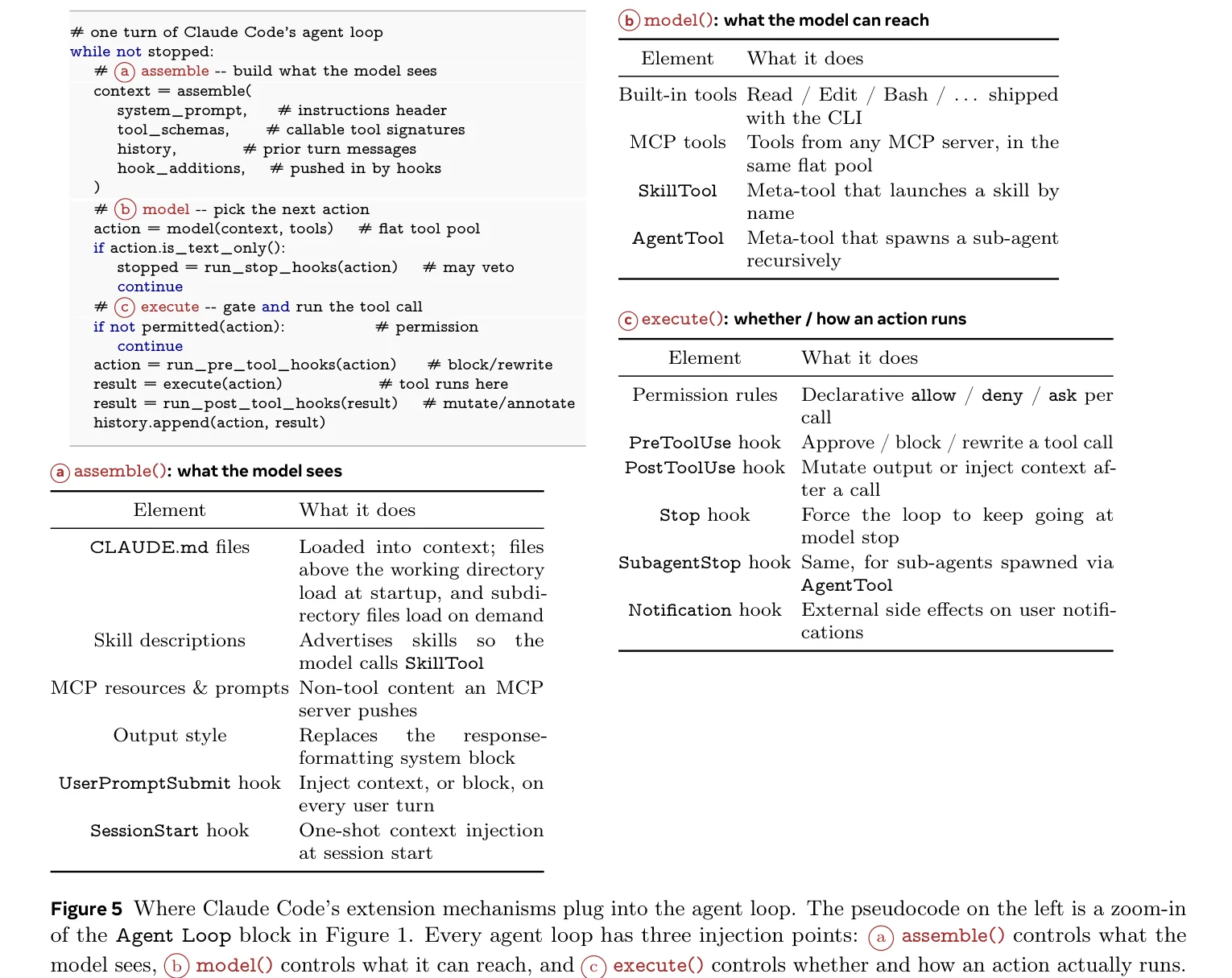
MCP Servers add tools to the pool (high context cost), Skills inject instructions into context (low cost), Hooks intercept before and after execution (zero cost), Plugins package and distribute the other three.
Why four? Because different types of extensions consume vastly different amounts of context window. Hooks take zero context and can be mounted freely; each MCP tool registration stuffs a full schema into the window. One mechanism can’t span the range from zero-cost lifecycle hooks to heavyweight tool services.
Permissions: Seven Layers of Safety and a 93% Approval Rate
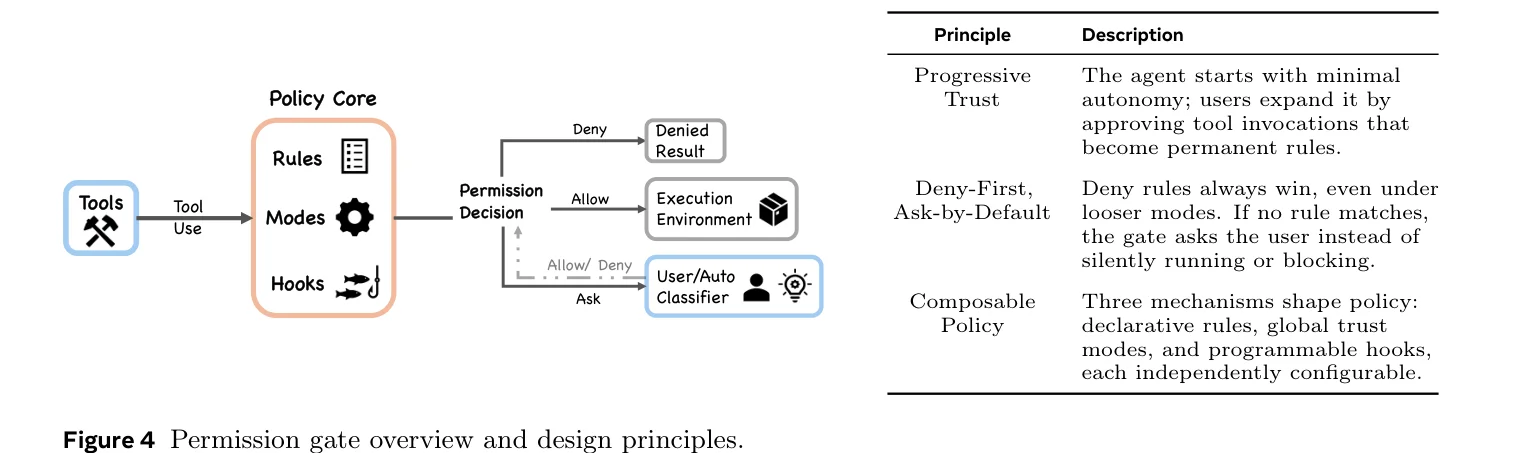
Deny-first means everything is rejected by default — only explicitly allowed operations can execute. Seven permission modes range from plan (user approves all actions) up to bypassPermissions (skips most prompts). Deny-first rule evaluation, ML classifier, shell sandbox, hook interception — multiple defense layers stacked together.
But the paper cites an unsettling number: users approve about 93% of permission prompts. Longitudinal data shows auto-approve rates climbing from 20% at 50 sessions to over 40% by 750 sessions. After enough use, most people just click approve without thinking. Interactive confirmation becomes a rubber stamp.
The architectural response isn’t to make users more vigilant — it’s to reduce the number of decisions users need to make. After sandboxing was introduced, permission prompt frequency dropped by roughly 84%.
Security researchers did find real vulnerabilities. The paper cites four published CVEs, two sharing the same root cause: code running during project initialization (hooks, MCP server connections, settings file resolution) executes before the trust dialog appears. This timing window bypasses the deny-first evaluation pipeline. The paper calls it “pre-trust initialization ordering” — every safety layer is in place, but there’s a temporal window where initialization code runs before the safety mechanisms activate.
Context Management
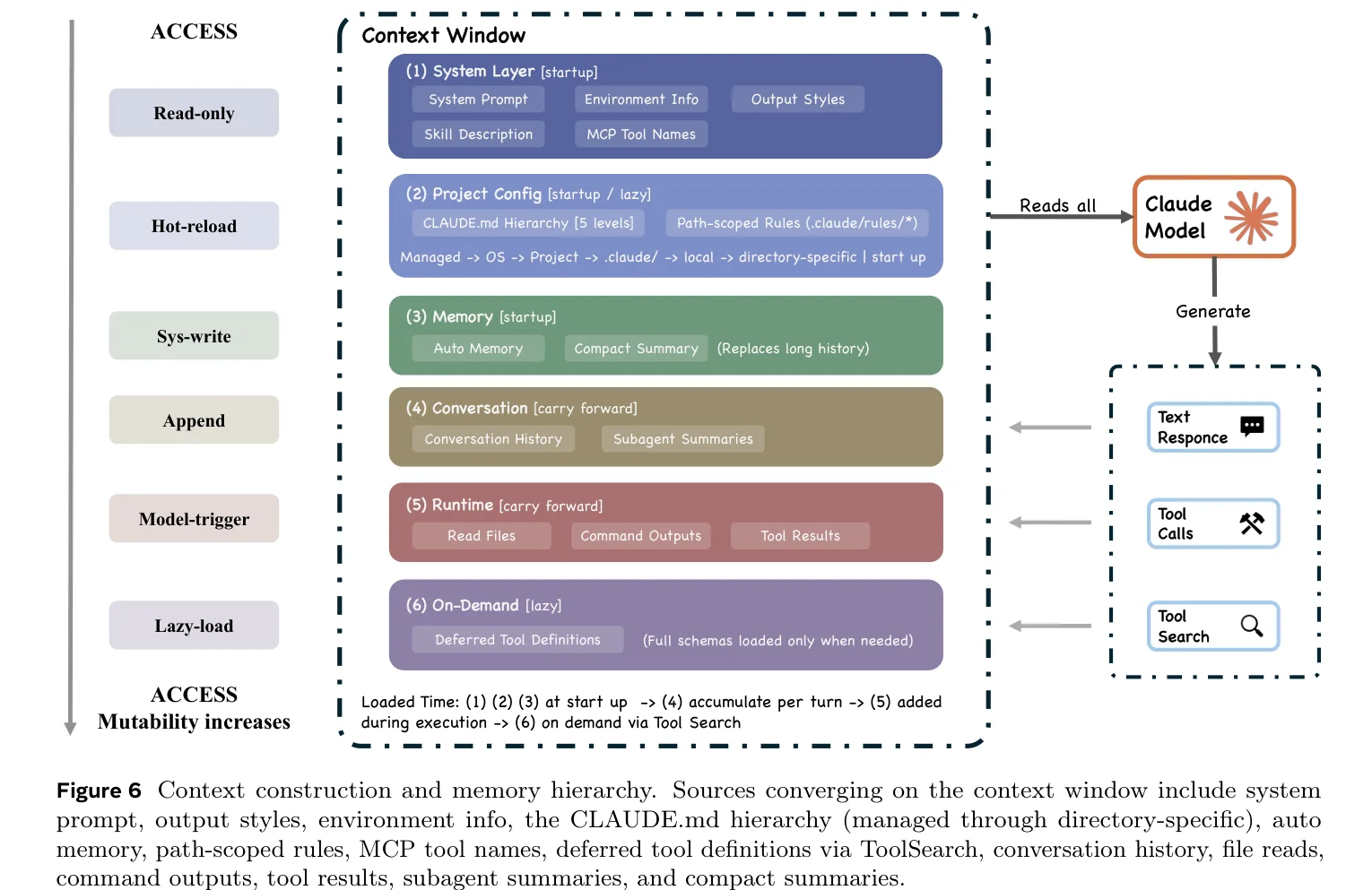
The paper draws an analogy between the context window and operating system memory management — not as metaphor, but as structural similarity. Claude Code’s five-layer compaction pipeline (budget reduction → snip → microcompact → context collapse → auto-compact) works like OS paging and swapping: cheapest strategy first, escalating only when cheaper approaches prove insufficient.
Each sub-agent has its own context window, returning only a final summary to the parent conversation. In agent team mode, token consumption is roughly 7× that of a standard session. Without summary isolation, it simply can’t hold up.
Compaction is lossy, though, and most of the five layers are invisible to the user. Budget reduction replaces long outputs, context collapse substitutes summaries for original messages, snip trims older history. What information gets dropped, the user has no way of knowing.
Locally Correct, Globally Questionable
The paper does something interesting: it derives testable predictions from architectural properties. A finite context window means the model can never perceive the entire codebase simultaneously. Five layers of compaction preserve the most recent and most relevant information, but each layer introduces information loss. Sub-agent isolation means parallel agents may independently re-implement solutions that already exist.
Two external studies provide supporting evidence: a causal analysis of 807 repositories found that Cursor adoption increased code complexity by 40.7%, with initial speed gains reverting to baseline within three months; an audit of 304,000 AI-authored commits found roughly a quarter of AI-introduced issues persisting to the latest revision, with security issues persisting at even higher rates.
These studies don’t target Claude Code specifically, but the architectural commonalities — finite context, tool-use loops, single-pass generation — make the findings transferable. The paper is careful: “whether these mechanisms are sufficient to overcome the structural limitations of bounded context is a directly measurable empirical question.”
The paper also devotes an entire Section 10 to comparing Claude Code with OpenClaw. Claude Code is an ephemeral CLI process bound to a single repository; OpenClaw is a persistent WebSocket gateway connecting over twenty messaging platforms. The two systems give opposite answers to the same design questions: Claude Code puts safety at every tool invocation (deny-first), OpenClaw puts safety at the gateway perimeter (identity and access control). Claude Code’s agent loop is the architectural center; OpenClaw’s agent loop is one component within a gateway control plane.
What’s interesting is that they can stack. OpenClaw invokes Claude Code as an external coding harness through ACP (Agent Client Protocol). The AI agent design space isn’t a flat taxonomy but a layered one, where gateway-level systems and task-level tools can compose.
The Value Tensions
The paper’s discussion of five value tensions is worth more thought than the architecture itself. Authority (user control) and Safety (system protection) are in structural conflict: a 93% approval rate shows human oversight is unreliable under fatigue, but fully automated decisions lose the human backstop. Capability and Reliability pull against each other too: finite context lets the model make good local decisions, but local optima don’t guarantee global optima.
The paper also cites a randomized controlled trial where 16 experienced developers became 19% slower with AI tools, despite perceiving a 20% improvement. A brain imaging study found that LLM users showed weakened neural connectivity that persisted after AI was removed. These issues have little to do with Claude Code’s specific architecture — any agent system faces them.
The paper draws an analogy: agent architectures are converging toward OS-like abstractions, the core loop as kernel, everything else as OS. If that direction holds, the 1.6%-to-98.4% ratio is probably not unique to Claude Code.