LLM2Vec: Turning Decoder LLMs into Embedding Models
Embedding models have long been BERT’s territory. Semantic search, RAG, clustering — all dominated by encoder-only models. Decoder-only models like GPT and LLaMA crush generation tasks, but the community has assumed they’re not suitable for embeddings because causal attention only sees preceding tokens and can’t build complete sentence representations.
LLM2Vec (COLM 2024) argued this assumption is wrong. Three steps, no labeled data, no GPT-4 synthetic data, and any decoder-only LLM becomes a SOTA embedding model on MTEB. Two years later, the approach has been validated and adopted by many subsequent works — worth revisiting what it actually did.
LLM2Vec Method
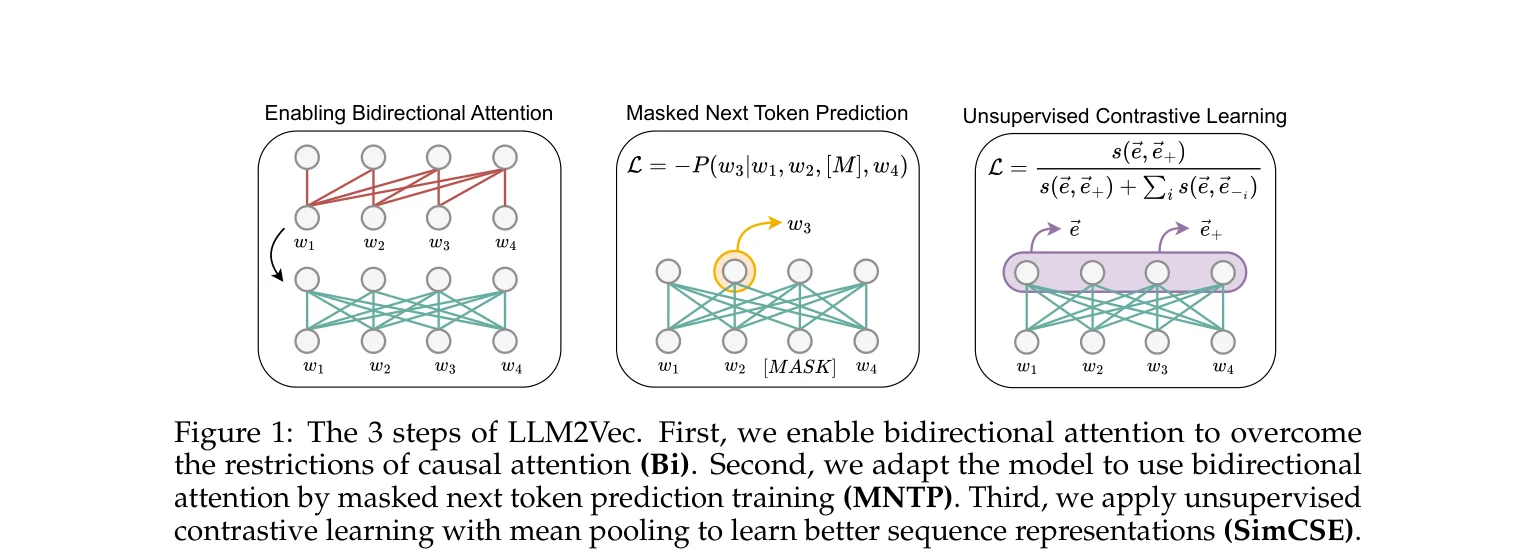
Step one: replace the causal attention mask with an all-ones matrix so every token attends to every other token. This sounds brutal — the model has never seen future information during training, and directly enabling bidirectional attention usually hurts performance.
Step two is the key. Masked Next Token Prediction (MNTP) adapts the model to bidirectional attention. Randomly mask some input tokens and have the model predict the masked tokens using the full context (including future tokens). One difference from BERT’s MLM: BERT uses the representation at the masked position itself to predict the original token; MNTP uses the representation at position i-1 to predict position i, preserving the decoder’s “predict i from i-1” habit so the model doesn’t need to learn an entirely new prediction pattern. Train with LoRA on English Wikipedia for 1,000 steps — 100 minutes on a single A100 for a 7B model.
Step three: unsupervised contrastive learning with SimCSE. Pass the same sentence through dropout twice to get two different representations, pull them closer while pushing apart other sentences in the batch. This step aggregates token-level bidirectional representations into good sentence-level representations.
Total training cost for all three steps: 1,000 steps MNTP + 1,000 steps SimCSE, one A100, a few hours.
Difference Between Causal and Bidirectional Representations
The Mistral-related finding in the paper is interesting. After enabling bidirectional attention, LLaMA models suffer a sharp performance drop without MNTP training — as expected. But Mistral-7B with bidirectional attention and no additional training shows almost no performance change, even gaining 0.6% on NER.
The paper analyzes this by running the same input through both causal and bidirectional attention and comparing representations at each layer and token position. LLaMA shows massive differences, with cosine similarity approaching zero. Mistral’s representations remain highly consistent, staying close to 1.0 throughout.
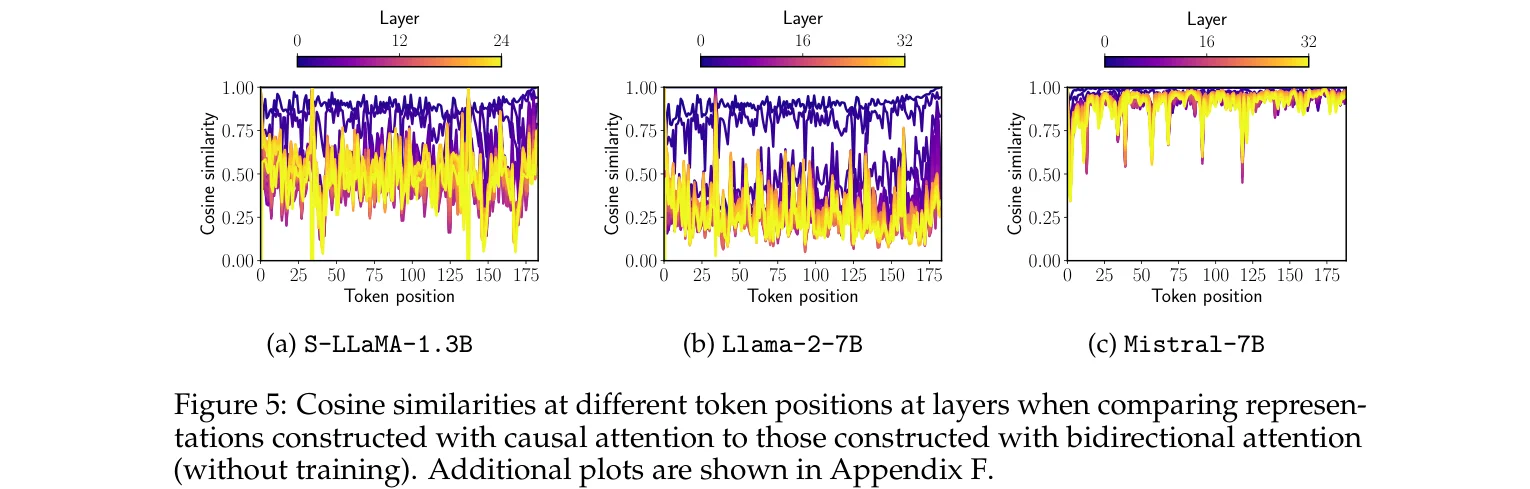
The paper speculates that Mistral may have used some form of bidirectional attention during pretraining, such as prefix language modeling. Training details aren’t public so this can’t be confirmed, but the experimental results are hard to explain otherwise. Either the architecture has special handling, or the training strategy already included bidirectional signals.
As a side note, the traditional approach for decoder embeddings is to take the last token’s (EOS) representation. Intuitively this makes sense since under causal attention the last token sees all preceding information.
But the paper’s experiments show that even for unmodified causal models, mean pooling outperforms EOS pooling. The gap widens after enabling bidirectional attention. While the EOS token’s representation theoretically aggregates all information, in practice tokens near the end contribute far more than those at the beginning — the information distribution is uneven. Mean pooling avoids this problem.
Supervised MTEB Results
After the three unsupervised steps, an additional round of supervised contrastive learning can be applied. The paper uses the public portion of the E5 dataset (about 1.5 million samples), achieving SOTA among models trained on public data on MTEB.
More interesting is the sample efficiency comparison.
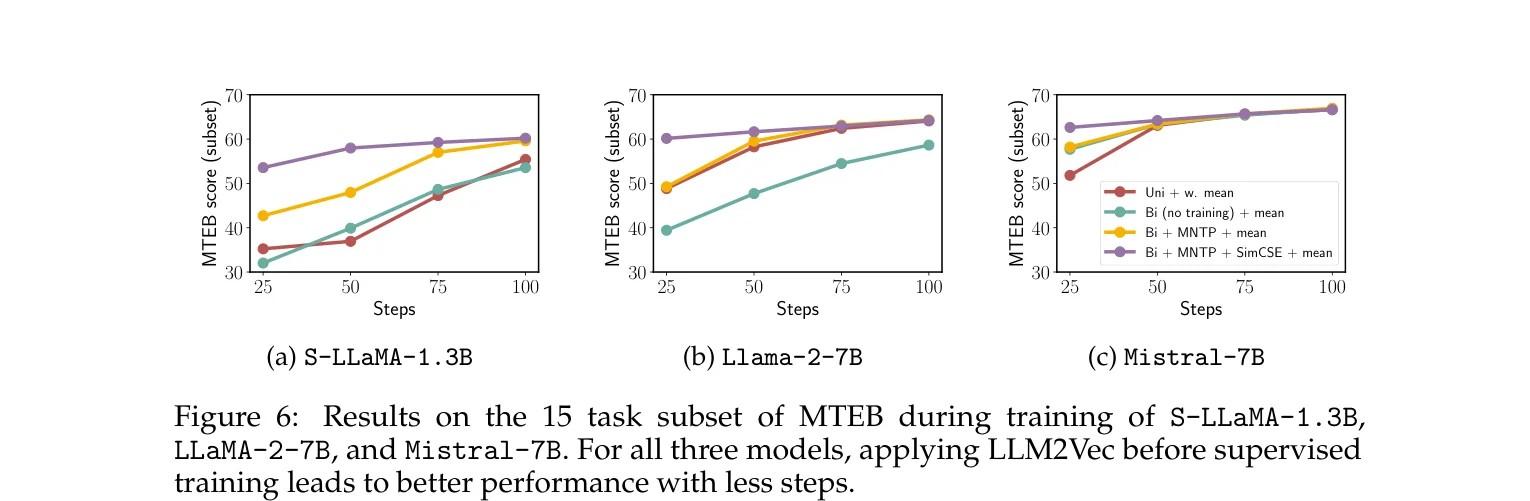
Models transformed by LLM2Vec surpass the untransformed baseline’s full 1,000-step performance within just the first 25 supervised training steps. The three unsupervised steps serve as a warm-up — the model already has decent sentence representation ability before seeing any labeled data.
One counterintuitive detail: in the supervised setting, skipping SimCSE (doing only bidirectional attention + MNTP) actually performs slightly better than doing all three steps. SimCSE’s value is mainly in purely unsupervised and data-scarce scenarios. With sufficient supervised signal, the contrastive signal learned by SimCSE gets overridden, and the extra step introduces a slight bias.
Summary
LLM2Vec has no new architecture, no new loss function — each of the three steps combines existing techniques. Replacing the attention mask with all-ones is a one-line code change, MNTP is a splice of MLM and NTP, and SimCSE is a 2021 paper. The core insight is simple: decoders are bad at embeddings because of the causal mask, not because they lack the ability.
On MTEB, LLM2Vec + Mistral-7B achieves an unsupervised score of 56.80, surpassing all previous unsupervised models including BERT + SimCSE’s 45.45. With supervised training, Meta-LLaMA-3-8B + LLM2Vec reaches 65.01, ranking first among models using only public data. LLM2Vec shows that decoders’ poor embedding performance is a causal mask limitation, not a capability issue. Remove that limitation with simple adaptation training, and they surpass encoder models specifically trained for embeddings on MTEB.