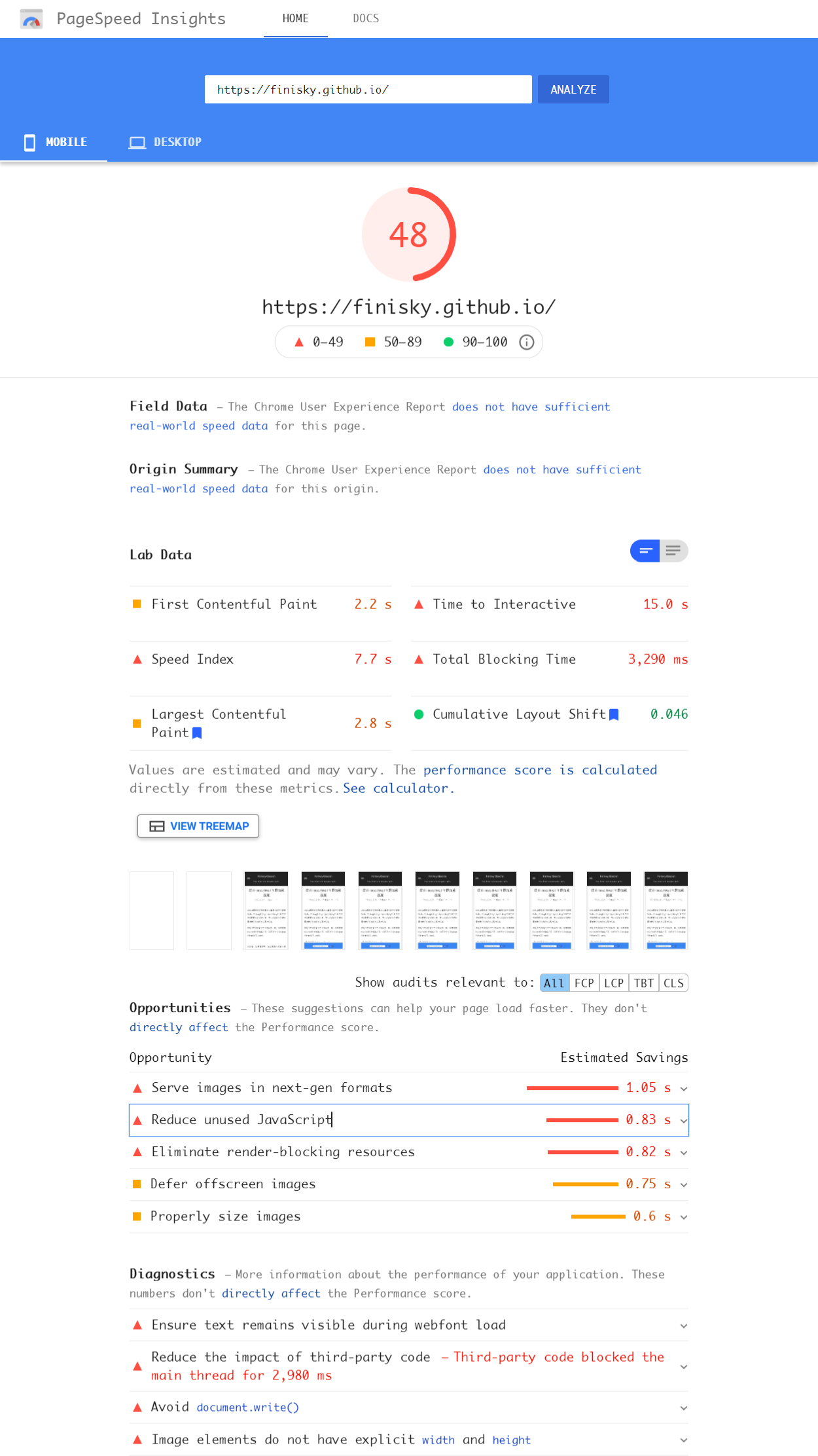
MongoDB Transaction BulkWrite Endless Retry
Previously we talked about # How to Retry MongoDB Transaction . However, if you use BulkWrite() and one of the operation is retryable (e.g. duplicated key error), the new transactions API will retry the bulk write endlessly which might lead to server CPU 100%. (MongoDB Server v4.4.6-ent, MongoDB Driver v2.12.2)
To avoid such issue, we have three suggestions:
- Add a cancellation token to limit the max retry time
- Break the transaction after max retry count
- Set BulkWriteOptions { IsOrdered = true }
The first two suggestions are also applicable to transactions which don’t use BulkWrite().