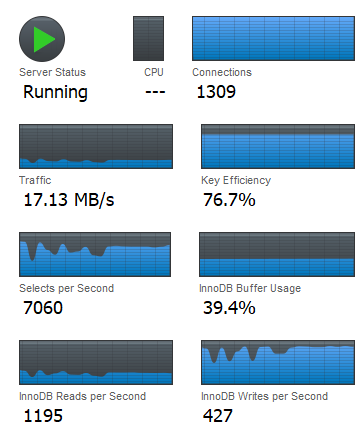
MongoDB Agent Monitoring and Backup not Working
Today I try to import an existing MongoDB deployment (out of the kubernetes cluster) into MongoDB Ops Manager which is running in kubernetes. After installing MongoDB Agent to the deployment, only automation functionality works while monitoring and backup not work. The root cause is that the agent still try to post data into Ops Manager’s internal endpoint.
The latest MongoDB Agent consists of a single binary that contains all three functions: Automation, Monitoring, and Backup. So theoretically install and configure the all-in-one automation agent in the deployment VM is enough.