为什么语言模型的本质是压缩器?
最早听说语言模型的本质是压缩器的想法是在黄仁勋和Ilya的围炉对谈,当时只是直觉上觉得这个说法很有意思,但却没想明白原理是什么。2023年9月,DeepMind写论文进一步论证了语言建模与压缩的等价性:
# Language Modeling Is Compression
长期以来,人们已经确认预测模型可以转化为无损压缩器,反之亦然。值得注意的是,近年来,机器学习领域一直专注于训练规模越来越大且功能强大的自监督语言模型。由于这些大语言模型展示了很强的预测能力,它们自然而然地也被认为是强大的压缩器。文中研究者主张通过压缩的视角来审视预测问题,并依此评估大型基座模型的压缩能力。实验证明大语言模型也是强大的通用预测器,语言模型即压缩的视角为扩展定律和上下文学习提供了新的见解。例如,Chinchilla 70B虽然主要用文本训练,但却能将ImageNet patches和LibriSpeech样本压缩到其原始大小的43.4%和16.4%,分别超过了领域特定的压缩器,如PNG(58.5%)和FLAC(30.3%)。最后,研究者证实基于预测与压缩的等价性可以使用任何压缩器来构建条件生成模型。
本文试图用简洁的语言(无公式)来说明“语言建模即压缩”的思想。原论文的思路是借助算术编码的原理和过程,然后将语言模型建模的过程与算术编码过程进行映射并证明它们等价。这个思路有些类似于NP难问题的证明:将一个问题在多项式时间归约成已知的某个NP难问题。
首先来看一下算术编码的过程,算术编码是一种无损压缩算法。算术编码的原理不容易直接描述,用例子来说明:
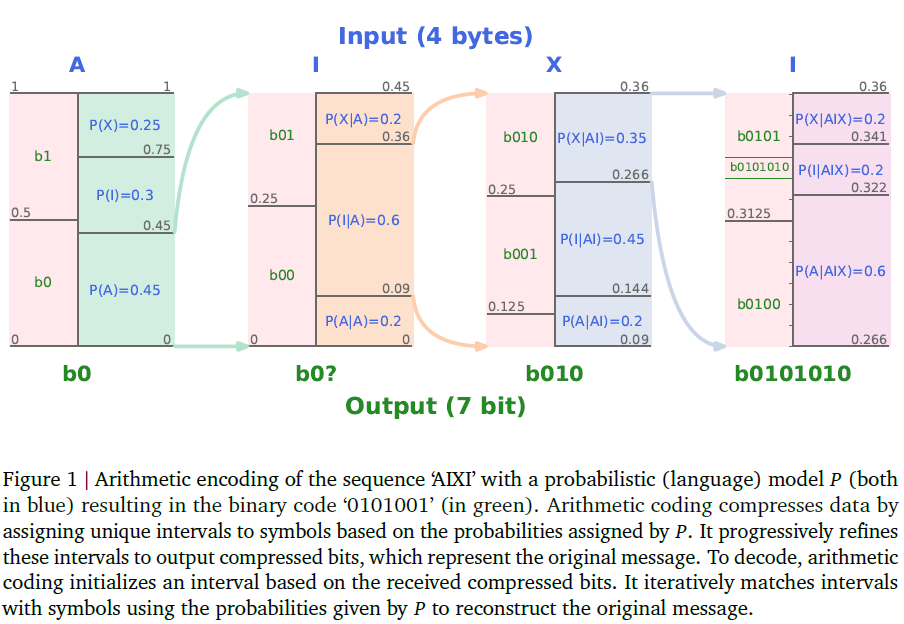
假设我们需要将AIXI用一个概率模型(也就是语言模型)P进行表示:
- P(A), P(I)和P(X)的概率可由语料库中统计得出,如左起第1张图所示。
- 由于
AIXI第一个字符为A,因此将落入第一个区间P(A)=0.45。下面继续将[0, 0.45)区间进行进一步分割成三个条件概率区间:P(X|A),P(I|A),P(A|A),如左起第2张图所示。 - 由于
AIXI第二个字符为I,因此将落入第二个区间P(I|A)=0.6。下面继续将[0.09, 0.36)区间进行进一步分割成三个条件概率区间:P(X|AI),P(I|AI),P(A|AI),如左起第3张图所示。 - 由于
AIXI第三个字符为X,因此将落入第一个区间P(X|AI)=0.35。下面继续将[0.266, 0.36)区间进行进一步分割成三个条件概率区间:P(X|AIX),P(I|AIX),P(A|AIX),如左起第4张图所示。 - 由于
AIXI第四个字符为I,最终落在P(I|AIX)区间,对应的二进制编码为b0101010。
解码的过程即是将上述过程反过来执行,不断查找当前数字所落区间对应的字符即可解码。
显然,上面每一步的条件概率都可以用一个语言模型进行表示,学到的概率分布即是训练语料库中字符的概率分布。因此,可以将语言模型看做一个是算术编码器,所以,最小化对数损失相当于最小化将该模型用作无损压缩器(采用算术编码)的压缩率,也就是说,当前语言模型的训练目标就是最大化其压缩率。
Minimizing the log-loss is equivalent to minimizing the compression rate of that model used as a lossless compressor with arithmetic coding, i.e., current language model training protocols use a maximum-compression objective.
由于压缩目标与语言模型训练的目标一致,因此二者是等价的。
实验考虑了三种不同模态的数据集,分别是文本、图像和音频,这些数据集在压缩方面具有非常不同的先验偏差,因此为评估压缩器的通用能力提供了一个良好的测试平台。
实验的一个关键问题是如何协调不同压缩器使用的不同上下文长度C。对于Transformer模型,其上下文受限于短序列(C= 2048字节),而gzip使用最大32K字节的上下文,LZMA2则具有几乎“无限”的上下文长度。拥有更长的上下文允许压缩器利用更多的序列依赖性以获得更好的压缩率。有两种主要方法可以处理比上下文长度更长的序列,即逐字节滑动和批次划分。研究者采用了后一种方法,将所有数据集划分为长度为2048字节的序列,逐个将其输入给压缩器。
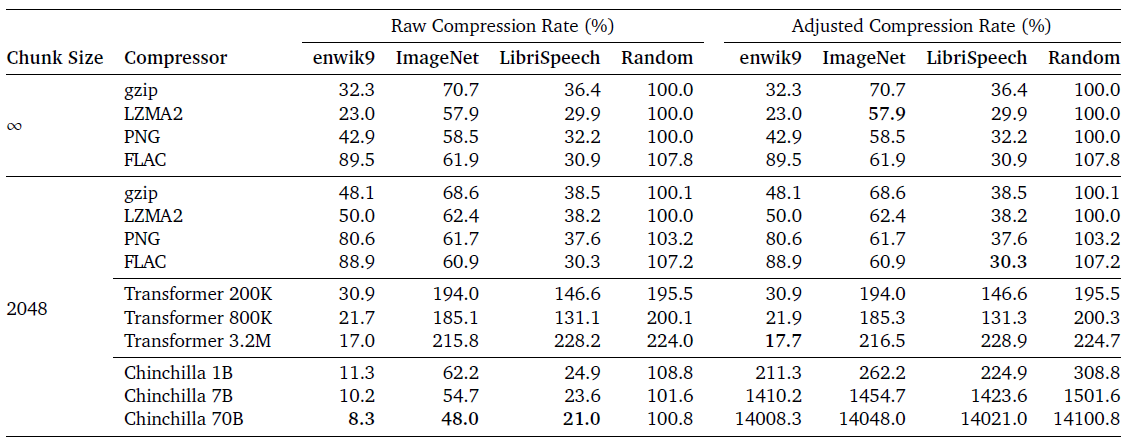
上图展示了各种压缩器在不同数据集上的效果,原始压缩率不考虑Transformer和Chinchilla模型的参数大小,而调整后的压缩率将参数大小视为压缩大小的一部分。所有数据集的原始大小均为1GB。随机数据被用作基准,不可压缩。Transformer和Chinchilla是预测模型,使用算术编码来获取无损压缩器。在enwik8上从头开始训练Transformer模型,而Chinchilla模型是在大型文本数据集上预训练的。在enwik上训练的Transformer模型过拟合于该数据模态,而Chinchilla模型对各种数据类型都是良好的压缩器。
在实践中,压缩器通常针对特定设置进行定制,例如,FLAC用于音频或PNG用于图像,因此无法很好地压缩其他模态数据。相比之下,通用压缩器如gzip,在各种数据源上都有良好的性能。有趣的是,虽然Chinchilla模型主要用文本数据训练,但它们似乎也是通用压缩器,在图像和音频数据上的压缩效果甚至优于所有其他压缩器。
这篇论文很好地解释了压缩和预测为什么等效:算术编码将一个预测模型转化为压缩器,反之亦然,通过使用编码长度构建遵循香农熵原理的概率分布,一个压缩器也可以转化为一个预测器。