训练中文垂类大模型:Lawyer LLaMA
开源的通用能力大模型越来越多,但真正有用和落地的是在某个领域专精的垂类模型。初看上去,似乎大模型仅需要少量prompt工作就可以很好地在垂类工作,可事实并非如此。不进行领域微调的通用模型可以很快地构建80分的应用,可是大部分的实用场景,需要95甚至98分的模型效果。这也是为什么在各个领域(如金融、车载、虚拟人)大家都在训练或微调自己大模型的原因。
微调这件事看上去不难,但却有很多未解问题:
- 如何基于英文大模型继续训练一个中文大模型?
- 垂类数据应该在预训练阶段引入,还是指令微调时引入?
- 通用指令数据与垂类任务数据的混合比例有什么讲究?
上面的每个问题都有很多种不同的方案,但限于时间和成本,逐一实验是不可行的,AB测试也会带来额外的成本。所以有趣的事情出现了,各个玩家对自己训练时的细节都讳莫如深,自己训练的时候也都遇到过各种各样奇怪的坑。更有意思的是,即使别人提供了一些细节参考,自己在训练时未必能够复现 :-( 。
代码库:# Lawyer LLaMA
Lawyer LLaMA技术报告:# Lawyer LLaMA Technical
Report
先来看个Demo: 
BELLE是基于LLaMA使用通用中文语料训练的模型,从上面的对比可见通用中文模型缺少法律领域的知识,即使给定了参考法条,它也不能很好地利用它生成比较好的回复。
训练过程
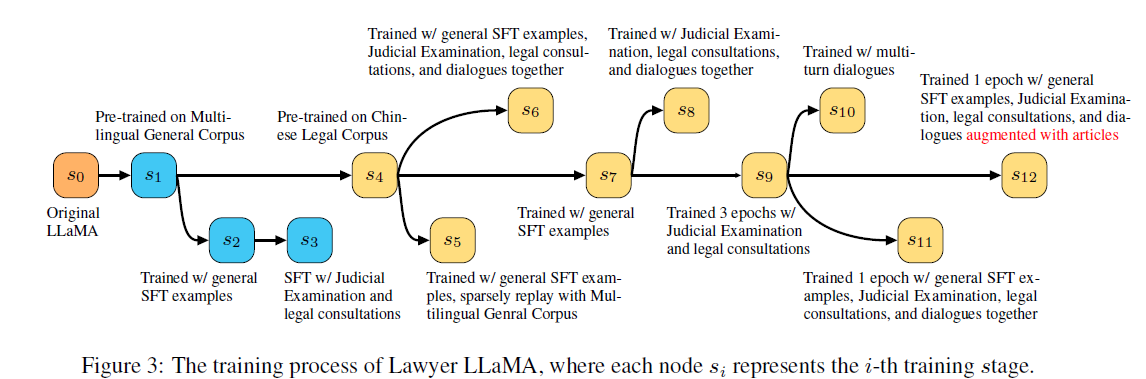
上图说明了Lawyer
LLaMA的训练过程,主要关注主线s0->s1->s4->s7->s9->s12:
预训练:
- s0->s1: 用多语言通用语料使模型可以理解中文
- s1->s4: 用中文法律语料给模型补充法律知识
SFT:
- s4->s7: 用通用SFT训练数据使模型可以完成指令
- s7->s9: 用法考数据与法律咨询数据继续训练,使模型提升推理能力
- s9->s12: 增加检索模块,增强模型使用外部知识的回复能力
增强中文能力
s0->s1阶段,由于LLaMA是个英文模型,首先需要提升它的中文理解能力。
此阶段的问题之一,是否要扩展词表?LLaMA原始词表中只有700个中文字符,但作者之前的研究显示扩展词表在下游中文任务上的表现不好,因此本文保持了原始词表。
另一个问题在于,继续预训练是仅使用中文,还是中英语料混合训练?考虑到英文预训练能带来部分推理能力,最终选择多语言通用语料混合训练(均经过采样):
- 中文:WuDaoCorpora, CLUECorpus2020, 中文Wikipedia
- 英文:C4
注入法律领域知识
s1->s4继续预训练阶段,作者收集了一些法律领域的中文文本,包括法律文章和司法解释。同时也加入了一些通用文本避免模型在法律文本上过拟合。
学习推理能力
s4->s7,进入SFT阶段,作者使用国家法考数据JEC-QA,同时利用ChatGPT进一步构造数据,让它给出更详细的解释。JEC-QA包括26365个单选和多选问题,但不包括对这些答案的解释。因此,在训练阶段,论文以QA对为指令,让ChatGPT对它进行解释。此外,还收集了真实用户咨询律师的一些问题,并使用ChatGPT构造回复。然后用构造的数据训练模型,增加其在法律领域的推理能力。
用ChatGPT构造回复时,在prompt中有六个要求:
- 恰当引用法条
- 基于事实和法条给出可靠的分析
- 给出详尽的分析,并给出潜在的可能性
- 适当反问挖掘事实,帮助给出更好回答
- 使用直白和普通的语言描述
- 给出初步的法律观点和咨询结论
下面是ChatGPT生成的答案解析范例:
Human:
根据《物权法》,下列关于物权变动的特别规定,表述正确吗?
因继承或者受遗赠取得物权的,自继承或者受遗赠开始时发生效力
请给出详细的推理过程之后再给出答案。
Assistant:
这个表述是正确的。
根据《物权法》第X条规定:“因继承或者受遗赠取得物权的,自继承或者受遗赠开始时发生效力。”这意味着,当一个人通过继承或受遗赠获得物权时,这个物权的效力是从继承或受遗赠开始时就生效的,而不是从物权转移的时间开始生效。这是因为,继承或受遗赠是一种法定的方式来获得物权,因此,物权的效力应该从这个法定的时间点开始生效。检索相关法条
论文发现即使在预训练阶段反复学习这些文章,模型在生成回复时依然不能很好地利用这些法条(幻想问题):模型很可能参考了一个无关文章或字面相近的法律条文。所以此处训练了一个检索模块,用类似knowlege grounded conversation的方式进行知识增强。
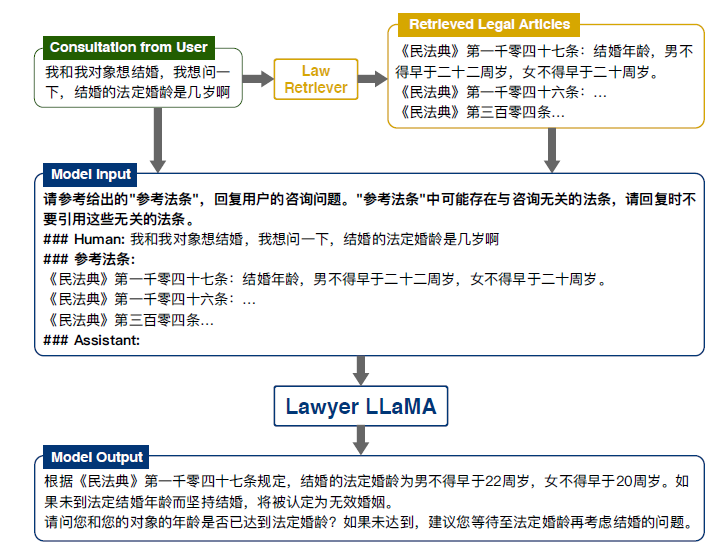
检索模块的数据构造使用法律咨询的真实问题,并对每个问题让法律从业人员标注了3篇相关法条。检索模块基于RoBERTa,可达0.85Recall@1和0.94Recall@5。
训练生成模型时发现它倾向于将所有检索出的内容都加入回复,即使它们不相关。因此作者在训练时加入了无关文章,让模型可以更好区分无用信息。此外,对于prompt模板也进行了修改,使用检索模块的数据范例:
Related Legal Articles:
《民法典》第一千零八十七条:离婚时,夫妻的共同财产由双方协议处理;协议不成的,由人民法院根据财产的具体情况,按照照顾子女、女方和无过错方权益的原则判决。对夫或者妻在家庭土地承包经营中享有的权益等,应当依法予以保护。
《民法典》第一千零六十三条:下列财产为夫妻一方的个人财产:(一)一方的婚前财产;(二)一方因受到人身损害获得的赔偿或者补偿;(三)遗嘱或者赠与合同中确定只归一方的财产;(四)一方专用的生活用品;(五)其他应当归一方的财产。
《民法典》第一千零六十二条:夫妻在婚姻关系存续期间所得的下列财产,为夫妻的共同财产,归夫妻共同所有:(一)工资、奖金、劳务报酬;(二)生产、经营、投资的收益;(三)知识产权的收益;(四)继承或者受赠的财产,但是本法第一千零六十三条第三项规定的除外;(五)其他应当归共同所有的财产。夫妻对共同财产,有平等的处理权。
Human:
你好,离婚后夫妻的财产是怎么分配的
Assistant:
您好,根据《民法典》的相关规定,离婚后夫妻的财产分配可以通过夫妻双方协商处理,如果没有协商一致,则需要由法院根据财产的具体情况,按照照顾子女、女方和无过错方权益的原则进行判决。对于夫妻在婚姻关系存续期间所得的共同财产,包括工资、奖金、劳务报酬、生产、经营、投资的收益、知识产权的收益、继承或者受赠的财产以及其他应当归共同所有的财产,应当平分。而夫妻在婚姻关系存续期间所获得的个人财产,包括婚前财产、因受到人身损害获得的赔偿或者补偿、遗嘱或者赠与合同中确定只归一方的财产、一方专用的生活用品,应当归该方所有。请问你们在婚姻关系存续期间所得的财产情况如何呢?实验结果
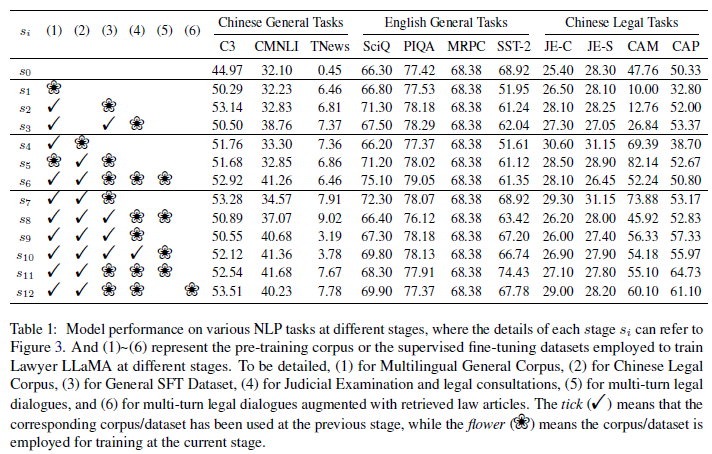
实验结果基于LLaMA-7B,一些主要结果:
- s0->s1: C3中文QA数据集提升 5.3%,显示用多语言通用语料训练后,模型中文理解能力提升,英文理解能力无损失。但在CAM和CAP任务上指标显著下降,作者猜想是由于新加的中文数据集多是新闻和wiki,与原始LLaMA的预训练数据分布差异较大所致。
- s0->s4: CAM数据集提升21.6%,显示用中文法律数据继续预训练后,模型学习到了婚姻法相关知识。
- s0->s4->s7: 法考JE-C和JE-S上分别有3.9%和2.85%的提升,显示用中文法律数据和通用指令训练后,模型可以更好地处理法律相关的任务。但如果使用对话指令微调数据训练后(s8,s10,s11),在法考指标上有所下降。猜想是法考问题和实际法务咨询问题相差较大所致。
- s12在大部分任务上都超过了s0,也是多轮法律咨询中表现最好的模型
从实验结果来看,很多地方还是靠经验和猜测得出结论,有没有效果还是得看炼丹的感觉。目前能找到的论文或报告,对数据和任务混合的一些细节还是涉及得较少。但个人认为这也不是壁垒,模型效果的可解释和可复现,才是真正值得深入挖掘的地方,是大模型持续发展的基石。
总结
Lawyer LLaMA训练中文垂类模型的思路很符合直觉,在预训练和SFT阶段都加入了垂类数据,最后还使用检索模块增加回复的可靠性。从结果来看,验证了上述方案微调垂类模型的可行性。
不过有一个问题,对垂类数据的构造是使用ChatGPT完成的,是不是说明ChatGPT已经很好地完成了通用+垂类任务?当然,ChatGPT的规模更大,Lawyer LLaMA相当于它在中文法律领域蒸馏的一个垂类模型。