大模型训练不稳定问题及解决方案
大规模语言模型的春风已经吹遍大地,大家都惊叹于大模型出色的对话能力,但是在训练大模型时遇到的训练不稳定问题(training instabilities),可能关注的人并不太多。所谓量变引起质变,模型每大一个量级,就可能会出现一些意想不到的问题,比如莫名其妙的训练崩溃。当然,也有好的方面,在模型有一定规模后,是否有可能表现出一些弱智能,也很难说。
言归正传,今天聊聊在训练10B以上模型时遇到的训练不稳定现象,问题原因及当前的解法。
OPT (175B)
# OPT: Open Pre-trained Transformer Language Models
Meta希望发布一个完全开放的模型供大家研究使用,于是训练了Open Pre-trained Transformer (OPT),与GPT-3一样大。抛去模型的细节,我们主要关注的是在训练中遇到的工程问题:训练不稳定。
OPT对训练不稳定问题记录和描述得最为详细,甚至开源了训练的 logbook 。从这些训练日志中,能切身体会到这些工程师在被训练崩溃困扰时有多么痛苦:
All in all, working around infrastructure issues has dominated the last two weeks of the team’s time, given that these hardware issues can take the experiment down for hours at any time of the day.
感恩节On-call的 无眠之夜 :
Since the sleepless night of Thanksgiving break, this past week has been filled with gradient overflow errors / loss scale hitting the minimum threshold (which was put in place to avoid underflowing) which also causes training to grind to a halt. We restarted from previous checkpoints a couple of times, and found that occasionally training would get a bit further (~100 or more steps) before hitting the same issue again.
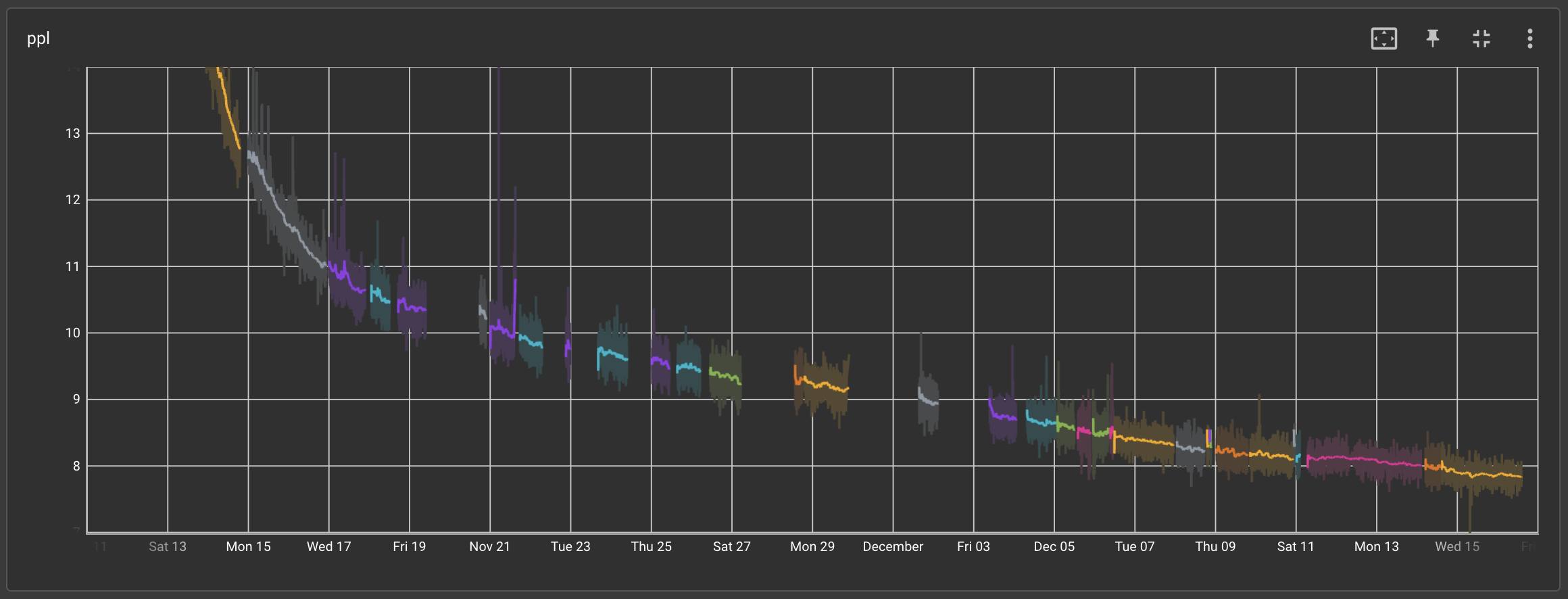
从上图能看出有许多训练停止的节点,尤其是在感恩节假期,所以训练不稳定问题发生得极为频繁。
至于引起instability的原因,部分可能是由于数据,因此他们将一些引发问题的数据清除了出去:
Other subsets of the Pile were eliminated as we found they increased the risk of instabilities, as measured by tendency to cause spikes in gradient norms at the 1.3B scale.
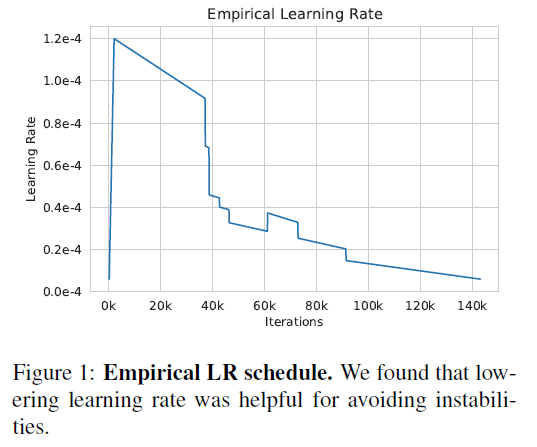
同时,为了减少训练不稳定现象,Learning Rate不能设置太大:
PaLM (540B)
# PaLM: Scaling Language Modeling with Pathways
Google在去年4月初也发布了一个巨大的模型 Pathways Language Model (PaLM),540B。其中专门有一节讲training instability:
For the largest model, we observed spikes in the loss roughly 20 times during training, despite the fact that gradient clipping was enabled. These spikes occurred at highly irregular intervals, sometimes happening late into training, and were not observed when training the smaller models. Due to the cost of training the largest model, we were not able to determine a principled strategy to mitigate these spikes.
即在训练过程中的loss可能会出现一些毛刺,它们的出现完全没有规律,但在训练较小模型时不会发生。考虑到训练大模型的成本,他们也并没有发现一个系统方案来解决这个问题。实际解法简单粗暴,采用一种启发式方案:在出现毛刺之前的100步,略去之后200~500 batch的数据,重启训练即可。
Instead, we found that a simple strategy to effectively mitigate the issue: We re-started training from a checkpoint roughly 100 steps before the spike started, and skipped roughly 200-500 data batches, which cover the batches that were seen before and during the spike. With this mitigation, the loss did not spike again at the same point.
PaLM的作者们并不认为毛刺的产生是由于某些“脏数据”,因为他们做了消融实验,尝试将这些略去的数据在其他checkpoint上进行训练,问题并没有复现。这可能说明这些毛刺仅在这些数据遇到某个模型的特殊状态时才会偶现。
This implies that spikes only occur due to the combination of specic data batches with a particular model parameter state.
WeLM (10B)
# WeLM: A Well-Read Pre-trained Language Model for Chinese
WeLM在训练10B模型时也发现了训练不稳定的问题,解决方案直接参考了PaLM和OPT的做法,略过出现问题的数据并重启训练。
We observe some instability issues when training the 10B-sized model. The training loss could suddenly increase in one batch then falls down. This loss spike, when happening frequently, would deteriorate the model weights and slows down the convergence. We mitigate this issue by re-starting the training from a checkpoint roughly 100 steps before the spike happened, then skipping the following 200 data batches. We also find it helps to reduce the learning rate and reset the dynamic loss scale.
总结
超过10B的大模型训练会遇到许多意想不到的问题,比如不收敛和训练不稳定。这些问题出现的根本原因目前还没有定论,但可以通过略去部分数据并重启训练的方式将训练最终完成。