LLM2Vec:把 Decoder LLM 变成 Embedding 模型
Embedding 模型一直是 BERT 家族的领地。做语义搜索、做 RAG、做聚类,用的都是 encoder-only 模型。GPT、LLaMA 这些 decoder-only 模型虽然在生成任务上碾压一切,但大家默认它们不适合做 embedding,因为 causal attention 只能看前面的 token,无法构建完整的句子表示。
2024 年的 LLM2Vec (COLM 2024)发现这个默认假设可能不对。三步改造,不需要标注数据,不需要 GPT-4 生成的合成数据,就能把任意 decoder-only LLM 变成 MTEB 上的 SOTA embedding 模型。
LLM2Vec 方法
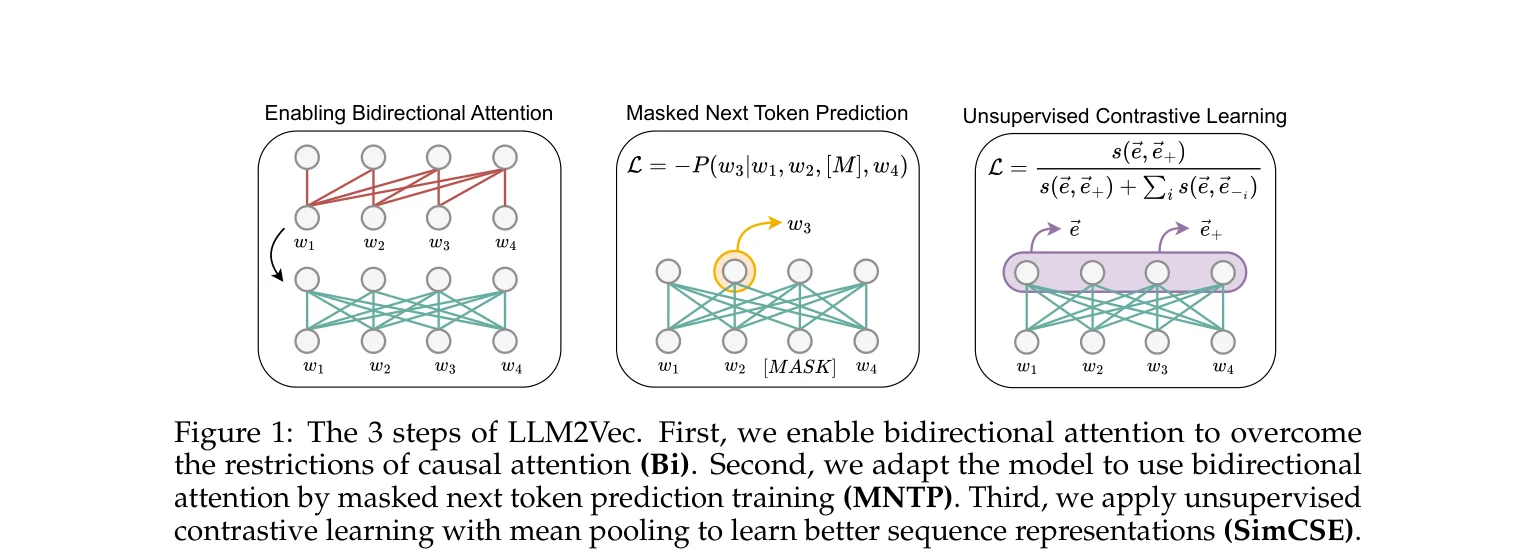
第一步,把 causal attention mask 换成全 1 矩阵,让每个 token 都能看到其他所有 token。这一步听起来粗暴,因为模型训练时从来没见过来自未来的信息,直接开放双向注意力性能通常会变差。
第二步是关键。用 Masked Next Token Prediction(MNTP)让模型适应双向注意力。随机 mask 输入中的一些 token,让模型根据上下文(包括未来的 token)预测被 mask 的 token。跟 BERT 的 MLM 有一个区别:BERT 用被 mask 的位置本身的表示来预测原词,MNTP 用前一个位置的表示来预测,保持了 decoder “用 i-1 预测 i"的习惯,模型不用学一套全新的预测方式。用 LoRA 在 English Wikipedia 上训练 1000 步,7B 模型在单卡 A100 上只需要 100 分钟。
第三步,用 SimCSE 做无监督对比学习。同一个句子过两次 dropout 得到两个不同的表示,拉近它们的距离,同时推开 batch 内其他句子。这一步让 token 级别的双向表示聚合成好的句子级表示。
三步加起来的训练成本:1000 步 MNTP + 1000 步 SimCSE,一张 A100,几个小时。
Causal 和 Bidirectional 表示的差异
论文里跟 Mistral 相关的发现有点意思。LLaMA 系列模型开放双向注意力后,不经过 MNTP 训练性能会断崖式下降,这符合预期。但 Mistral-7B 开放双向注意力后,不做任何训练,性能几乎不变,NER 任务上甚至还涨了 0.6%。
论文做了一个分析:把同一个输入分别用 causal 和 bidirectional attention 跑一遍,比较每一层每个 token 位置的表示。LLaMA 的表示差异巨大,余弦相似度趋近于零。Mistral 的表示高度一致,全程接近 1.0。
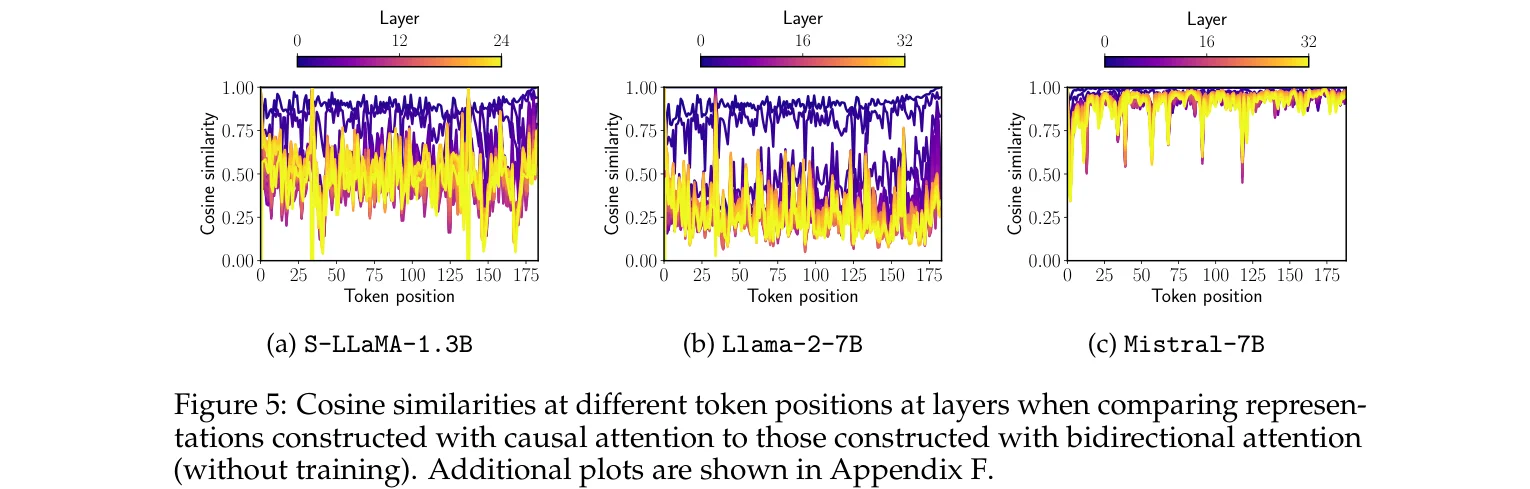
论文的猜测是 Mistral 在预训练阶段可能用了某种形式的双向注意力,比如 prefix language modeling。训练细节没有公开,无法确证,但实验结果很难有别的解释。要么是架构上有特殊处理,要么是训练策略里已经包含了双向信号。
顺带一提,decoder 模型做 embedding 的传统做法是取最后一个 token(EOS)的表示。直觉上这说得通,因为在 causal attention 下最后一个 token 能看到所有前面的信息。
但论文的实验显示,即使是没有经过 LLM2Vec 改造的原始 causal 模型,用 mean pooling 也比 EOS pooling 好。开放双向注意力之后差距更大。EOS token 的表示虽然理论上聚合了全部信息,但实际上靠近末尾的 token 对它的贡献远大于开头的 token,信息分布不均匀。Mean pooling 绕过了这个问题。
有监督的 MTEB 结果
LLM2Vec 的无监督三步做完之后,可以再接一轮监督对比学习。论文用了 E5 数据集的公开部分(约 150 万样本),在 MTEB 上达到了公开数据训练模型的 SOTA。
更有意思的是 sample efficiency 的对比。
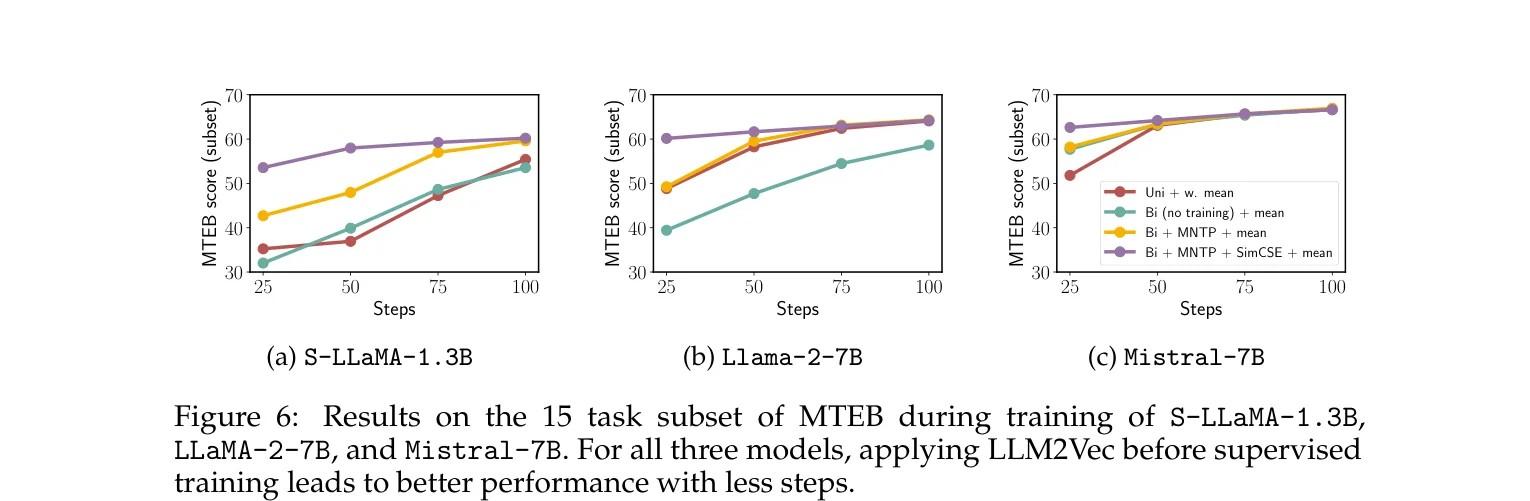
LLM2Vec 改造过的模型在监督训练的前 25 步就已经超过了没有改造的基线模型跑完全部 1000 步的性能。无监督的三步相当于热身,模型在看到标注数据之前就已经有了不错的句子表示能力。
还有一个反直觉的细节:在有监督设置下,跳过 SimCSE 这一步(只做双向注意力 + MNTP)反而比三步都做的效果略好。SimCSE 的价值主要体现在纯无监督场景和数据稀缺场景。有足够监督信号的时候,SimCSE 学到的对比信号会被监督信号覆盖,多做一步反而引入了轻微的偏差。
总结
LLM2Vec 没有新架构,没有新损失函数,三步里的每一步都是已有技术的组合。把 attention mask 换成全 1 是一行代码的事,MNTP 是 MLM 和 NTP 的拼接,SimCSE 是 2021 年的论文。说白了就是一个洞察:decoder 做不好 embedding 是因为 causal mask 挡住了,不是能力不行。
在 MTEB 上,LLM2Vec + Mistral-7B 的无监督分数 56.80,超过了之前所有无监督模型,包括 BERT + SimCSE 的 45.45。加上监督训练后,Meta-LLaMA-3-8B + LLM2Vec 拿到 65.01,在只用公开数据的模型里排第一。LLM2Vec 点出 decoder 做不好 embedding 不是能力问题,是 causal mask 的限制。去掉这个限制再做简单的适配训练,就能在 MTEB 上超过专门训练的 encoder 模型。