MongoDB Aggregation Pipeline入门
MongoDB 的 Aggregation Pipeline 是处理和分析数据的强大工具,适用于实时查询和离线数据分析。它允许开发者使用多个阶段(stages)来转换、过滤、分组和排序数据,从而高效地执行复杂的计算。本文将探讨 Aggregation Pipeline 的基本概念、应用示例、性能分析及优化方案。
Aggregation Pipeline 基础
Aggregation Pipeline 由多个 stage 组成,每个 stage 负责特定的数据处理任务,例如:
$match:用于筛选文档,类似 SQL 的WHERE,用于减少数据扫描量。例如,SELECT * FROM orders WHERE status = 'active';相当于{ "$match": { "status": "active" } }。$group:对数据进行分组并计算聚合值,类似 SQL 的GROUP BY。例如,SELECT category, COUNT(*) FROM orders GROUP BY category;在 MongoDB 中可用{ "$group": { "_id": "$category", "count": { "$sum": 1 } } }实现。$sort:对数据进行排序,类似 SQL 的ORDER BY,例如SELECT * FROM orders ORDER BY createdAt DESC;相当于{ "$sort": { "createdAt": -1 } }。$project:调整字段输出,类似 SQL 的SELECT column1, column2 FROM table;,在 MongoDB 中可用{ "$project": { "name": 1, "price": 1 } }。$lookup:进行表关联(类似 SQL 的JOIN),例如 SQL 的SELECT * FROM orders INNER JOIN customers ON orders.customerId = customers.id;在 MongoDB 中可用{ "$lookup": { "from": "customers", "localField": "customerId", "foreignField": "_id", "as": "customer" } }。$unwind:将数组字段展开,相当于 SQL 的LATERAL VIEW,用于处理嵌套数据。$merge:将结果写入新的集合,类似于 SQL 的INSERT INTO new_table SELECT * FROM old_table;。
下面是一个Aggregation的示例,筛选所有status为active的文档,然后按照 category 进行分组,并计算每个类别中的文档数量,最后按照数量从高到低排序,返回每个类别及其对应的 active 记录数。
Aggregation应用场景
实时数据分析与监控
在许多业务场景中,企业需要对实时数据进行监控和分析,以便快速做出决策。例如,在电商平台中,分析用户的实时访问数据可以帮助优化推荐系统,而在金融行业,监控交易数据可以用于欺诈检测。
Aggregation Pipeline 允许开发者构建高效的数据流处理系统。例如,利用 $match 过滤特定交易类型,结合 $group 计算统计指标,可以实时监控异常交易。例如:
这个 Aggregation Pipeline 可以实时监测高额交易,并排序用户的消费情况,有助于发现可疑交易行为。
数据ETL与预聚合
对于数据仓库和大数据分析场景,Aggregation Pipeline 可以用于数据抽取(ETL)和预聚合处理,减少查询开销,提高性能。例如,社交媒体平台可能需要分析用户的历史行为数据,以生成个性化推荐。
一个典型的 ETL 任务可能包括:
- 使用
$lookup连接多个集合的数据,如用户行为日志和商品信息。 - 过滤无效数据,减少存储压力。
- 通过
$group进行聚合计算,生成预计算的数据表。 - 使用
$merge将数据存入新的集合,以便后续查询。
通过这样的 Aggregation Pipeline,企业可以提前计算用户的行为特征,减少在线查询时的计算压力,提升查询性能。这种方式特别适用于大规模数据处理,如推荐系统、广告投放优化和用户行为分析。
Aggregation使用示例
本节我们将使用一个完整的示例来展示Aggregation的用法。
数据准备
在开始演示 Aggregation 之前,我们需要准备一个示例数据库 sales_db,其中包含一个 orders 集合,结构如下:
使用mongoshell插入一些示例数据(包括orders和customers collection):
| |
插入数据后,用MongoDB Compass查看:
$match 筛选数据
获取 total 大于 500 的订单:
在Compass中的Aggregations Tab的执行结果(注意只使用括号内的内容):
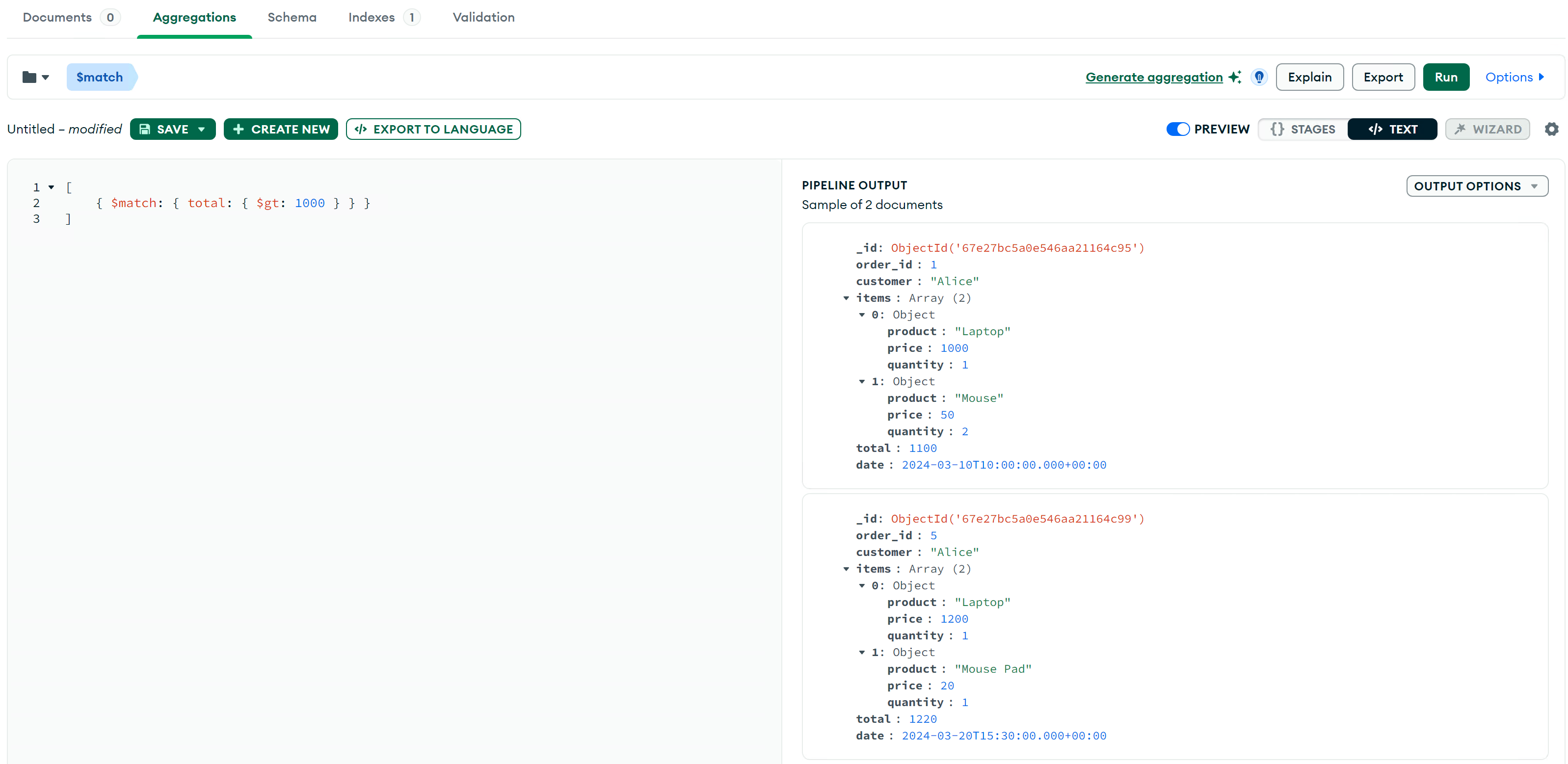
$group 分组计算
按客户分组,计算每位客户的总消费金额:
结果:
$sort 排序
按客户总消费金额降序排列:
结果:
$project 选择和修改字段
只显示订单号、客户和总金额:
结果:
| |
$unwind
展开 items 数组,使每个订单的每个商品成为单独的文档:
部分结果:
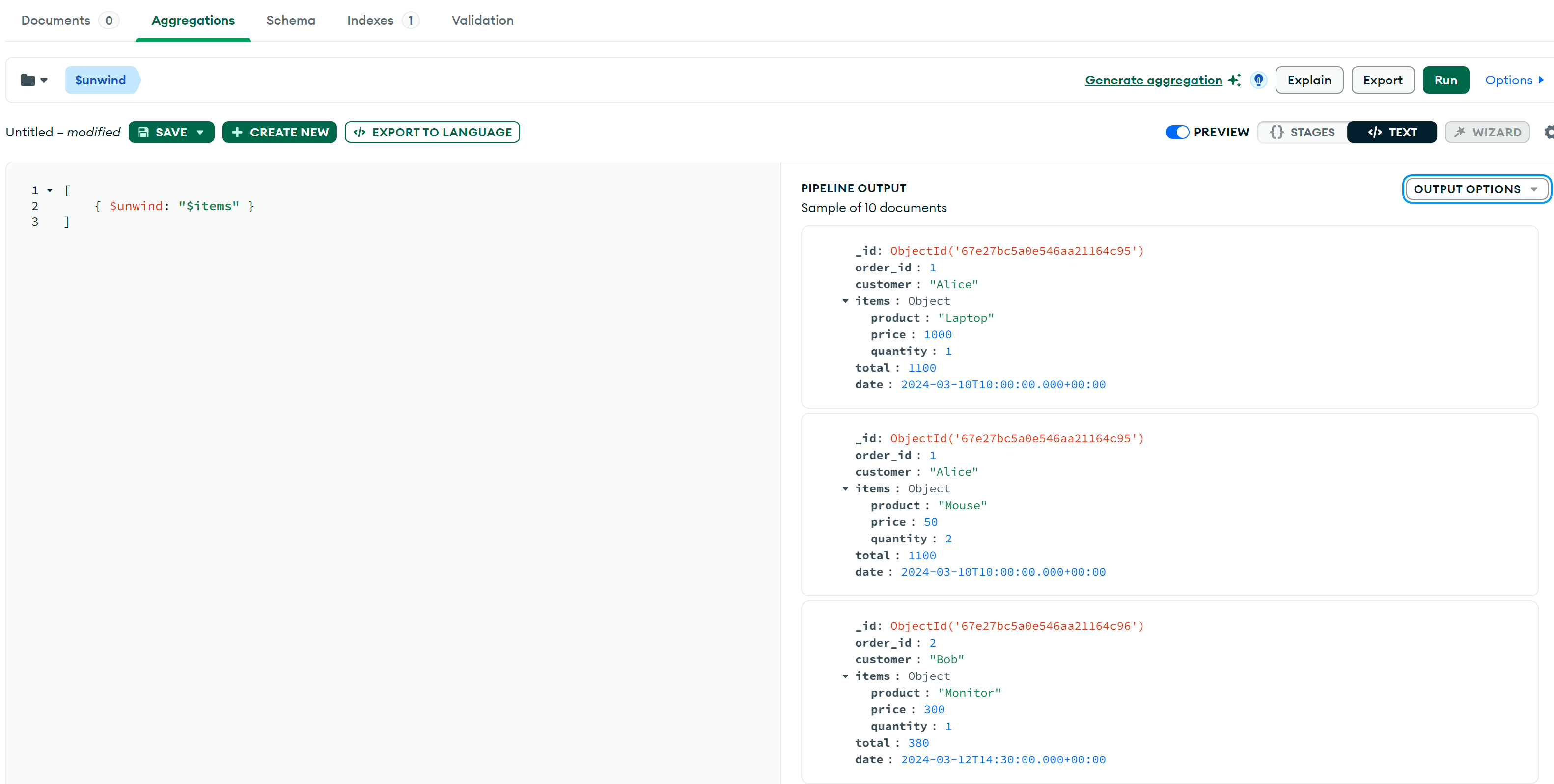
$lookup 连接另一集合
customers 集合包含客户的详细信息,我们可以使用 $lookup 进行关联查询,类似join:
部分结果,客户的详细信息已在customer_info:
| |
综合示例
我们可以将多个阶段组合在一起,实现复杂的数据分析需求。例如,统计 2024 年 3 月 每个客户的订单总数和消费总额,同时获取客户的email,并按总消费金额降序排序:
| |
结果如下:
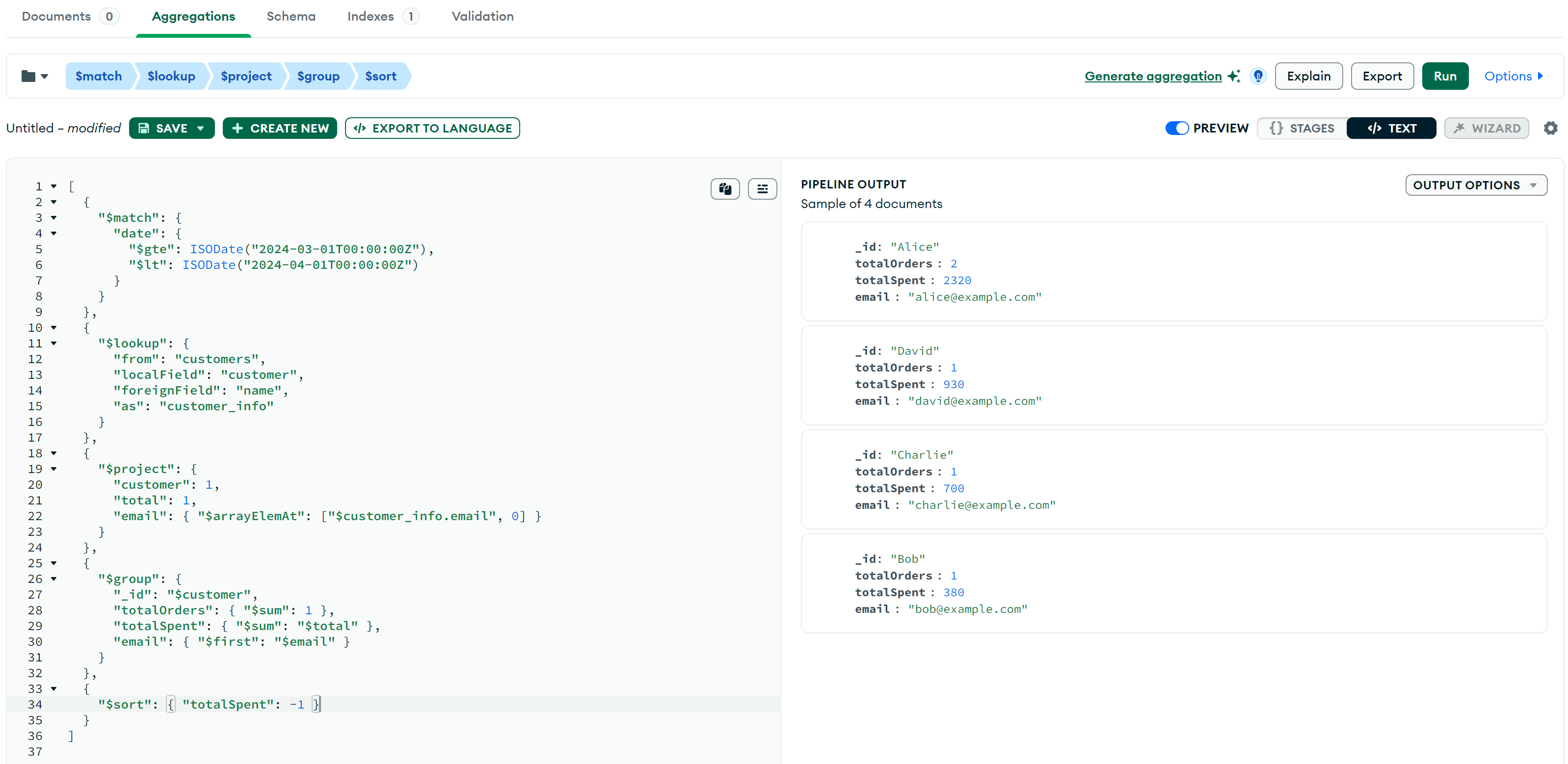
Aggregation Pipeline 性能分析与优化
性能分析
分析 Aggregation Pipeline 性能的方法包括:
explain()诊断:使用db.collection.aggregate([...]).explain("executionStats")来分析查询计划,检查索引使用情况和每个阶段的执行情况。profiler:启用 MongoDB Profiler (db.setProfilingLevel(2)) 记录慢查询,并分析system.profile集合。行时间。- MongoDB Atlas Performance Advisor(如果使用 Atlas):提供自动优化建议。
性能优化
一般而言,Aggregation的性能受以下因素影响:
- 索引使用:
$match阶段应尽量利用索引,以减少扫描数据量。 - 阶段顺序:将
$match放在最前面,以减少后续计算。 - 数据量:处理大规模数据时,Pipeline 可能占用大量内存。
索引优化
确保 $match 使用索引,提高查询效率。例如:
| |
减少 $lookup 依赖
$lookup 可能导致性能下降,一些优化方案如:
- 预处理数据,避免运行时
JOIN - 使用嵌套文档存储相关数据
Pipeline 阶段顺序优化
最佳顺序:
$match- 先过滤数据,减少后续处理量。$project- 去除不必要的字段,降低开销。$sort- 适当使用索引排序,避免内存消耗。$group- 仅在必要时聚合。
MongoDB Aggregation Pipeline 提供了强大的数据处理能力,适用于数据分析、ETL 及离线任务。通过合理使用索引、优化 Pipeline 结构和采用分片技术,可以显著提高性能。