TextCNN pytorch实现
TextCNN 是一种经典的DNN文本分类方法,自己实现一遍可以更好理解其原理,深入模型细节。本文并非关于TextCNN的完整介绍,假设读者比较熟悉CNN模型本身,仅对实现中比较费解的问题进行剖析。
项目地址:https://github.com/finisky/TextCNN
这里的实现基于: https://github.com/Shawn1993/cnn-text-classification-pytorch
主要改动:
- 简化了参数配置,希望呈现一个最简版本
- Fix一些由于pytorch版本升级接口变动所致语法错误
- Fix模型padding导致的runtime error
- 解耦模型model.py与training/test/prediction逻辑
- 定制tokenizer,默认中文jieba分词
- 使用torchtext的TabularDataset读取数据集:text abel
NLP中CNN的Channel与Filter
注:此处的Filter与Kernel的意义相同。
# Understanding Convolutional Neural Networks for NLP 对Channel和Filter的解释比较清楚。CNN是源于CV领域的一个概念,对于一张图来讲,RGB天然就是3个不同的Channel输入,而迁移到NLP中之后,文本其实只有一个Channel,但也可以通过使用不同的embedding(word2vec, glove, BERT等)或rephrase等方法将输入变成多个Channel。而Filter的目的是对于同一个输入用不同的kernel做卷积,从而提取出不同的Feature。用一个不是非常严谨的表述,Channel像是输入本身的一个天然存在的性质,而Filter是人为增加不同维度来提取Feature。
TextCNN模型
模型的细节参考下图(wildml盗图),无须赘述: 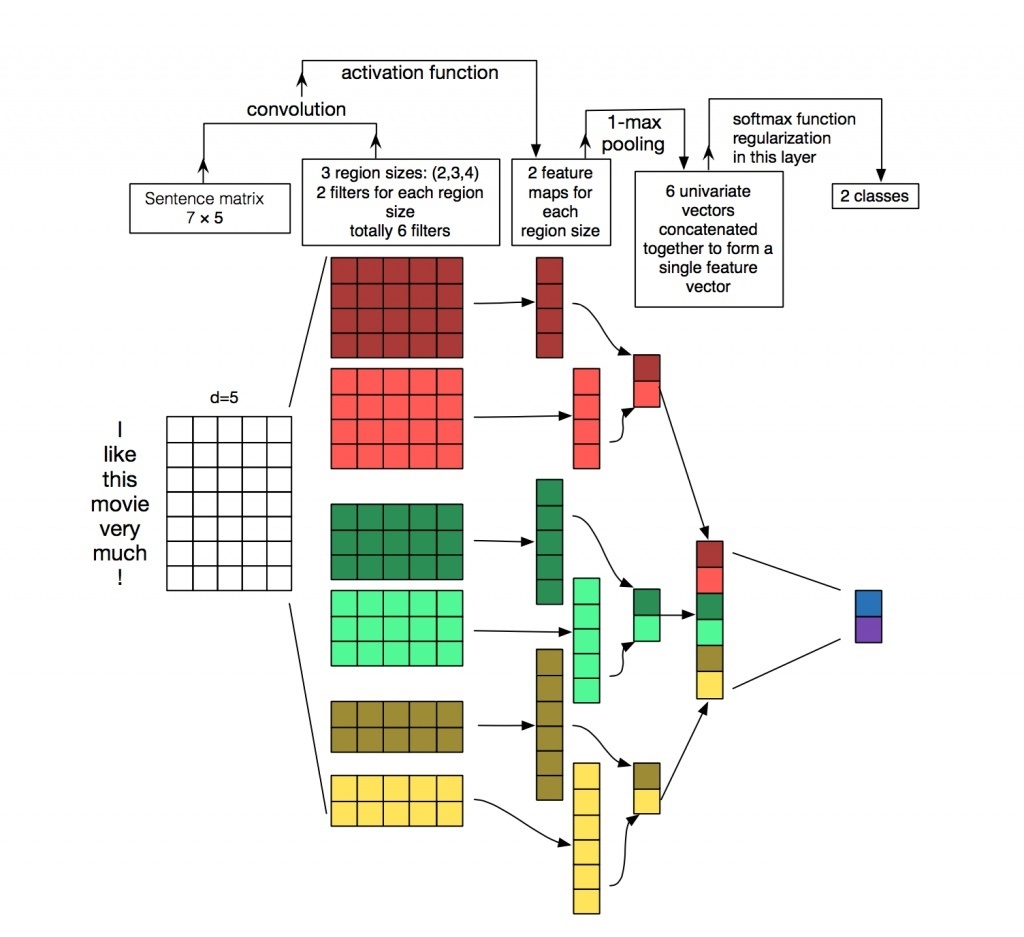
值得一提的是NLP的卷积操作和CV中有所不同,CV中的图像为二维输入,卷积会在横纵两个方向上进行,而NLP中的输入虽然看起来是二维的(token_num, embedding_dim),但卷积只在第一维方向进行,即每个滑动窗口都包括了整个embedding vector。道理很容易理解,每个token的语义由整个embedding vector表示,在局部的embedding vector上做卷积不太说得通。
nn.Conv2d详解
torch.nn.Conv2d(in_channels, out_channels, kernel_size, stride=1, padding=0, dilation=1, groups=1, bias=True, padding_mode='zeros')参数含义
stride, padding,
dilation这些参数的意义,a picture is worth a thousand words,
直接看动画即可: #
Convolution animations
kernel_size, stride, padding,
dilation参数类型可以是int也可以是tuple of two
ints,若为tuple,分别用在H维度与W维度。
输入与输出
输入:(N,C_{in},H,W)
输出:(N,C_{out},H,W)
就TextCNN而言,N为batchsize,C_{in} = 1, C_{out}为指定的kernel_num,H为一个句子中的token_num,W为embedding_dim。
例子
假设有个句子 token_num=4, embed_dim=5,使用一个3*embed_dim的kernel进行卷积,kernel_num = Co = 2。
既然是在H维度上卷积,每个卷积操作滑过整个embedding vector,所以kernel_size的第二个维度必定是embed_dim。此外,必须满足kernel_size[0] <= token_num,否则会有如下错误:
RuntimeError: Calculated padded input size per channel: (? x 5). Kernel size: (? x 5). Kernel size can't be greater than actual input size
特别地,在kernel_size[0]=3, token_num >= 1的情景下,需要在H维度上进行padding,且一定不能在W维度上padding,以保证卷积操作有效,每次都滑过整个embedding vector。因此,padding = (1, 0)。本文参考的原始实现没有对文本进行padding,如果数据集中存在过短的文本,训练时会出现runtime error。
import torch
import torch.nn as nn
torch.manual_seed(0)
token_num = 4
embed_dim = 5
kernel_size = 3
Ci = 1
Co = 2
m = nn.Conv2d(Ci, Co, (kernel_size, embed_dim))
fixed_weight = (m.weight, m.bias)
def conv_padding(x, padding, fixed_weight = None):
conv = nn.Conv2d(Ci, Co, (kernel_size, embed_dim), padding = padding)
if fixed_weight is not None:
conv.weight = fixed_weight[0]
conv.bias = fixed_weight[1]
x = conv(x)
return x
raw_x = torch.randn(token_num, embed_dim) # (token_num, embed_dim)
x = raw_x.unsqueeze(0).unsqueeze(0) # (1, 1, token_num, embed_dim)
print ("x size: " + str(x.size()))
print (x)
print ("\nNo padding:")
print (conv_padding(x, 0).size())
print (conv_padding(x, 0))
print ("\nPadding in the height axis:")
print (conv_padding(x, (1, 0), fixed_weight).size())
print (conv_padding(x, (1, 0), fixed_weight))
print ("\nVerify padding vectors:")
pad_x = torch.cat((torch.zeros(1, embed_dim), raw_x, torch.zeros(1, embed_dim))).unsqueeze(0).unsqueeze(0)
print (pad_x)
print (conv_padding(pad_x, 0, fixed_weight))执行结果如下:
x size: torch.Size([1, 1, 4, 5])
tensor([[[[-0.6136, 0.0316, -0.4927, 0.2484, -0.2303],
[-0.3918, 0.5433, -0.3952, 0.2055, -0.4503],
[-0.5731, -0.5554, -1.5312, -1.2341, 1.8197],
[-0.5515, -1.3253, 0.1886, -0.0691, -0.4949]]]])
No padding:
torch.Size([1, 2, 2, 1])
tensor([[[[ 0.1010],
[ 0.3119]],
[[ 0.3740],
[-0.1368]]]], grad_fn=<MkldnnConvolutionBackward>)
Padding in the height axis:
torch.Size([1, 2, 4, 1])
tensor([[[[-0.1523],
[ 0.3070],
[-0.0044],
[ 0.1774]],
[[ 0.4631],
[ 0.5886],
[-0.5039],
[-0.4035]]]], grad_fn=<MkldnnConvolutionBackward>)
Verify padding vectors:
tensor([[[[ 0.0000, 0.0000, 0.0000, 0.0000, 0.0000],
[-0.6136, 0.0316, -0.4927, 0.2484, -0.2303],
[-0.3918, 0.5433, -0.3952, 0.2055, -0.4503],
[-0.5731, -0.5554, -1.5312, -1.2341, 1.8197],
[-0.5515, -1.3253, 0.1886, -0.0691, -0.4949],
[ 0.0000, 0.0000, 0.0000, 0.0000, 0.0000]]]])
tensor([[[[-0.1523],
[ 0.3070],
[-0.0044],
[ 0.1774]],
[[ 0.4631],
[ 0.5886],
[-0.5039],
[-0.4035]]]], grad_fn=<MkldnnConvolutionBackward>)易得,原始的句子输入为 45,如果是未padding的输入经过35卷积核后结果为21,在H维度padding之后卷积的结果为41。
从nn.Conv2d中很难拿到padding之后的输入vector,为了验证padding与我们预期的结果一致,将nn.Conv2d中的weight和bias都固定下来,分别计算no padding input + model padding = (1,0) 与padding input + model padding = 0的结果,二者输出一致,证明padding正确。
代码实现
https://github.com/finisky/TextCNN
model.py
https://github.com/finisky/TextCNN/blob/master/model.py
核心模型代码,比较简洁,与args解耦:
import torch
import torch.nn as nn
import torch.nn.functional as F
class TextCnn(nn.Module):
def __init__(self, embed_num, embed_dim, class_num, kernel_num, kernel_sizes, dropout = 0.5):
super(TextCnn, self).__init__()
Ci = 1
Co = kernel_num
self.embed = nn.Embedding(embed_num, embed_dim)
self.convs1 = nn.ModuleList([nn.Conv2d(Ci, Co, (f, embed_dim), padding = (2, 0)) for f in kernel_sizes])
self.dropout = nn.Dropout(dropout)
self.fc = nn.Linear(Co * len(kernel_sizes), class_num)
def forward(self, x):
x = self.embed(x) # (N, token_num, embed_dim)
x = x.unsqueeze(1) # (N, Ci, token_num, embed_dim)
x = [F.relu(conv(x)).squeeze(3) for conv in self.convs1] # [(N, Co, token_num) * len(kernel_sizes)]
x = [F.max_pool1d(i, i.size(2)).squeeze(2) for i in x] # [(N, Co) * len(kernel_sizes)]
x = torch.cat(x, 1) # (N, Co * len(kernel_sizes))
x = self.dropout(x) # (N, Co * len(kernel_sizes))
logit = self.fc(x) # (N, class_num)
return logit因为最大kernel_size是5,所以padding=(2,0),保证卷积操作有效。
还有个比较费解的地方,kernel_num和len(kernel_sizes)有什么区别?kernel_sizes是一组不同size的kernel,而kernel_num指的是有多少组这样的kernel。所以,实际上整个网络中kernel的总数是kernel_num * len(kernel_sizes)。这点从TextCNN模型图中也可看出,共有kernel_num=2组kernels,每个组中有3/4/5三个不同size的kernel,共6个kernel。
operation.py
https://github.com/finisky/TextCNN/blob/master/operation.py
完成模型的外围操作,包括train(), test(), predict()和save()。 不贴完整代码了,只有一处需要解释:
for batch in train_iter:
feature, target = batch.text, batch.label
feature.t_(), target.sub_(1) # batch first, index aligntarget为什么需要减1?原因在于label_field.vocab里包括一个<unk>:
{'<unk>': 0, '1': 1, '0': 2}main.py
https://github.com/finisky/TextCNN/blob/master/main.py
程序入口,parse参数,读取数据,分词。 也不贴完整代码了,只贴读取数据和建词表(data format: text abel):
text_field = data.Field(lower=True, tokenize = tokenize)
label_field = data.Field(sequential=False)
fields = [('text', text_field), ('label', label_field)]
train_dataset, test_dataset = data.TabularDataset.splits(
path = './data/', format = 'tsv', skip_header = False,
train = 'train.tsv', test = 'test.tsv', fields = fields
)
text_field.build_vocab(train_dataset, test_dataset, min_freq = 5, max_size = 50000)
label_field.build_vocab(train_dataset, test_dataset)
train_iter, test_iter = data.Iterator.splits((train_dataset, test_dataset),
batch_sizes = (args.batch_size, args.batch_size), sort_key = lambda x: len(x.text))替换原始实现的mydataset.py,同时建词表时设置了min_freq和max_size。
运行方法
随机选了23000条 weibo_senti_100k 数据,其中train/test分别有20000和3000条。
Train
python main.py -train
Test
python main.py -test -snapshot snapshot/best_steps_400.pt
运行结果:
Evaluation - loss: 0.061201 acc: 98.053% (2518/2568)Predict
python main.py -predict -snapshot snapshot/best_steps_400.pt
运行结果:
>>内牛满面~[泪]
0 | 内牛满面~[泪]
>>啧啧啧,好幸福好幸福
1 | 啧啧啧,好幸福好幸福虽然测试的准确率很高,但实际测试的效果一般,原因在于weibo_senti_100k的文本分类任务比较简单,这个数据集比较脏,大概率是按文本中的emoji写规则进行的正负向标注。