BlenderBot 3 对话系统简析
Meta AI在2022年8月发布了新一代的对话系统 BlenderBot 3,希望通过这样一个公开的demo收集更多的真实数据来改进对话系统,使它变得更安全、更有用。
BlenderBot 3: a deployed conversational agent that continually learns to responsibly engage
BlenderBot 3 (BB3) 只对在美国的成人开放,只用英文对话:
We present BlenderBot 3 (BB3), an open-domain dialogue model that we have deployed as an English speaking conversational agent on a public website accessible by adults in the United States.
此研究的主要目的与 Sparrow 最接近,使对话更responsible & useful:
The goal of this research program is then to explore how to construct models that continue to improve from such interactions both in terms of becoming more responsible and more useful.
这个tech report包括了BB3部署的细节,包括UI设计,本文主要关注模型部分。
Model
BB3是由Transformer model构成,发布了三个不同大小的模型:3B (encoder-decoder,R2C2), 30B 和 175B (decoder-only, OPT)。
BB3是个模块化的系统,总体来看比较复杂,但模型底层架构都是一个transformer,只不过通过不同的control codes (或者说prompt) 来让它执行不同模块的功能。思路与其他大模型一致,让模型做multi-task learning。
Training a single transformer model to execute the modules, with special control codes in the input context telling the model which module it is executing.
先来看看BB3都有哪些模块:
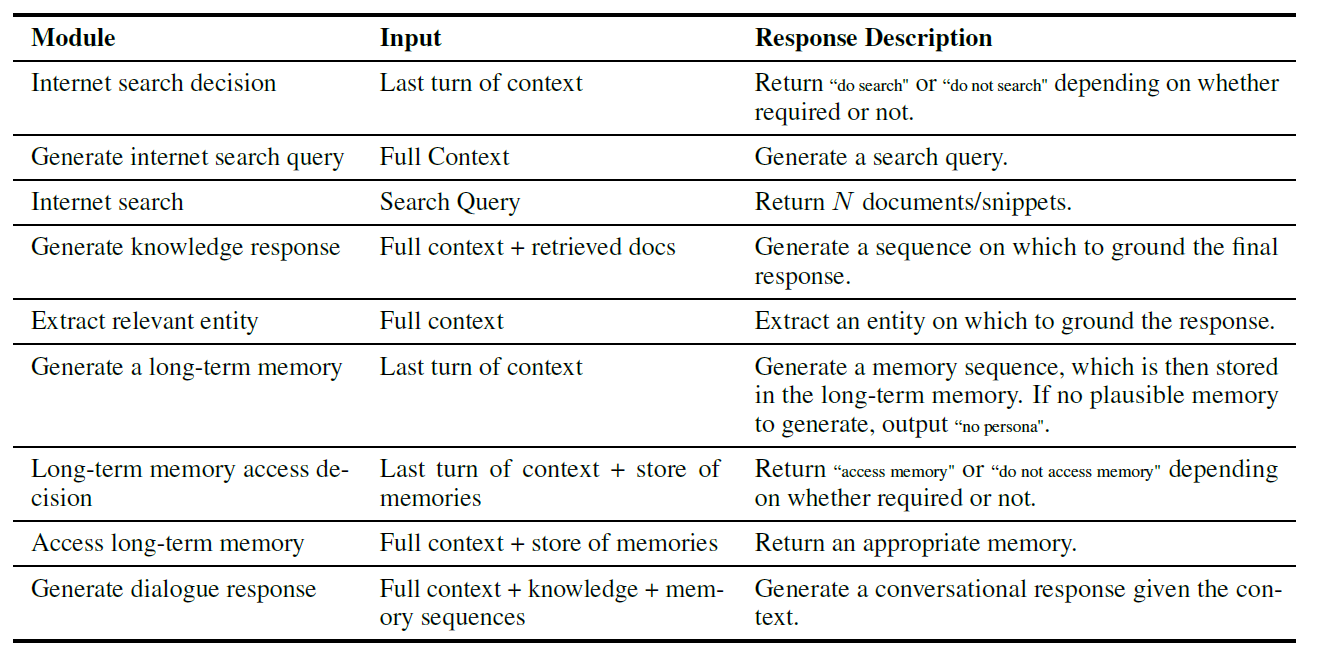
一眼望去头都大了,居然有9个模块,实际上大体分属三类:Search,Generator和long-term memory。而这些模块的执行流程如下:
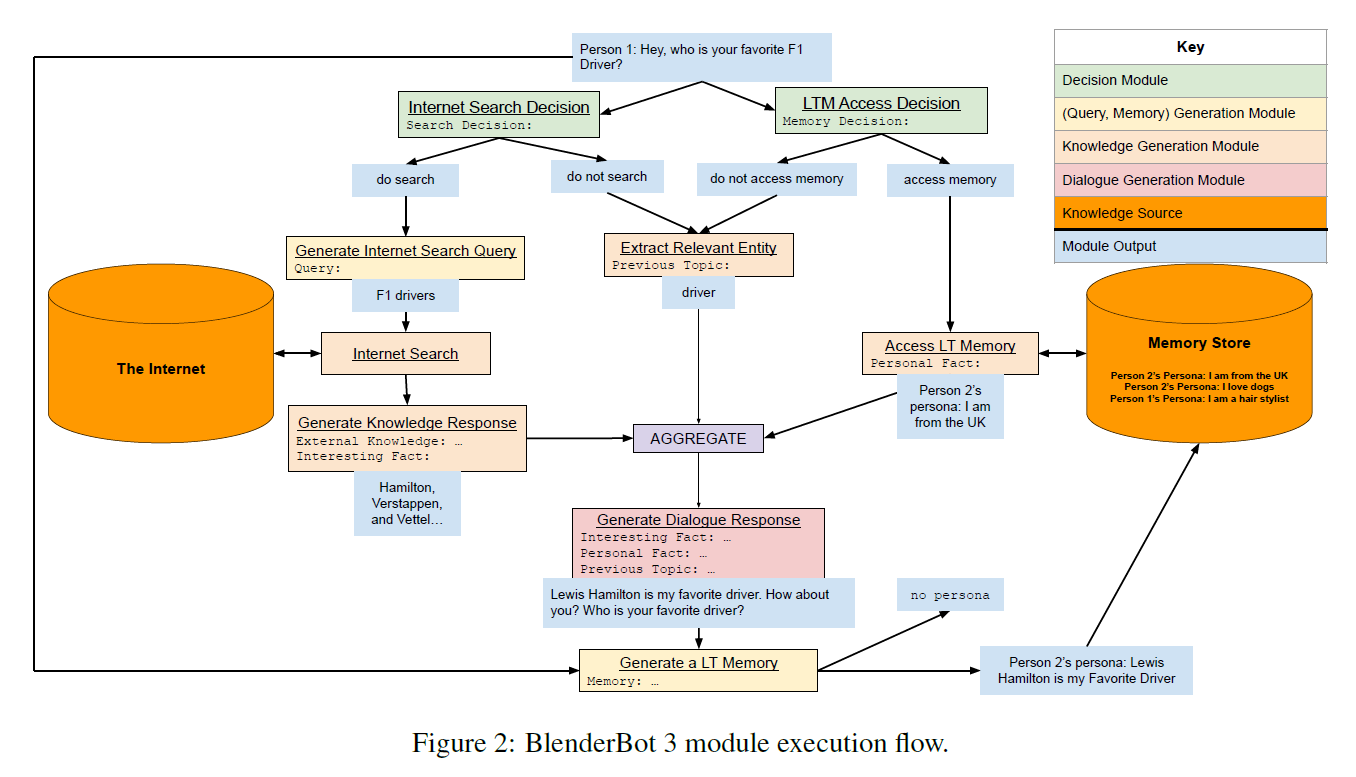
此流程看起来更为复杂,让我一度怀疑生成回复到底需要多长时间?简单描述下执行过程,收到Query后,判断是否需要Search,是否需要long-term memory,然后提取相关的entity,将Search result/memory/entity聚合,生成最终的回复。
Datasets
模型使用的预训练数据是类似的:cc100en约100B tokens,PushShift.io Reddit数据等,最终数据约有180B tokens。
Finetune主要采用各种对话数据集,包括QA,open-domain, knowledge-grounded conversation,task-oriented dialogue,以及一些对话安全性的数据集。这些任务如下图:
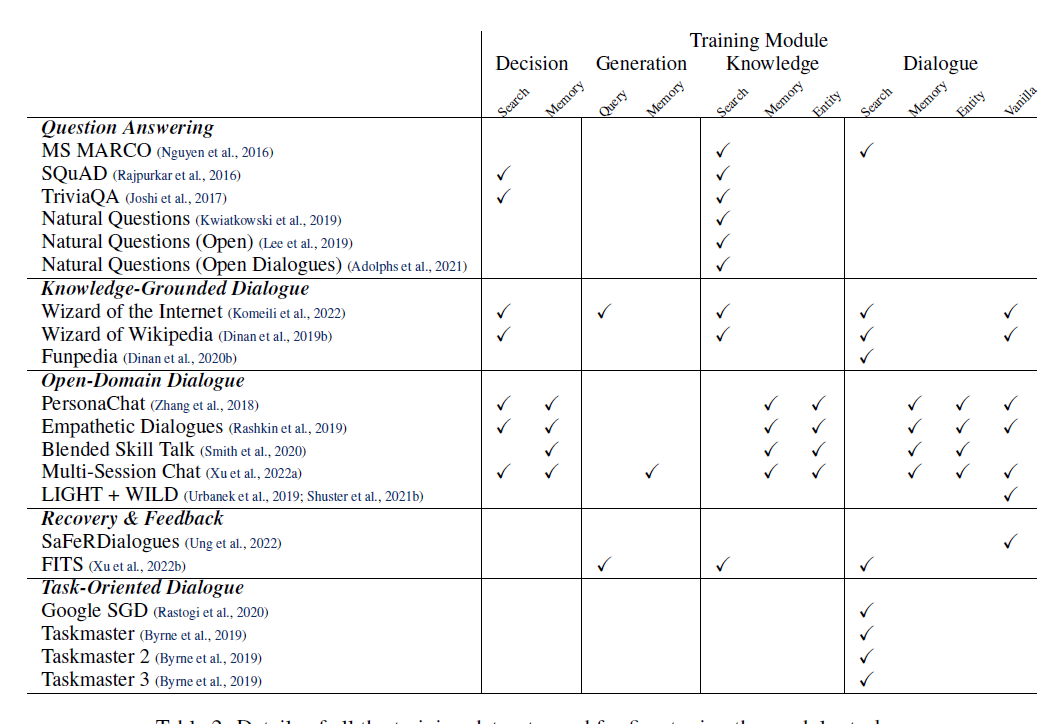
BB3部署在 https://blenderbot.ai ,不过仅能在美国使用。论文剩下的部分讨论了如何从与人类交互的数据中持续学习,其方法和结论在另两篇论文中有详细论述,此处不再赘述。
We are committed to sharing organic conversational data collected from the interactive demo system as well as model snapshots in the future.
看下BB3聊天的效果,它可以聊任何话题:

总体来看,BB3通过大模型、搜索技术与多任务学习使人机对话更聪明,安全和有用。同时收集BB3与真人对话的数据,并计划发布数据集,以探索和验证如何从人机交互中改进对话质量。相比于 ChatGPT / Sparrow / LaMDA ,BB3更偏向于系统和产品设计,旨在从真实的数据中不断学习。正如其在博客中所言:
As more and more people interact with the demo, we will aim to improve our models using their feedback, and release deployment data and updated model snapshots, for the benefit of the wider AI community.