ChatGPT擅长搜索排序吗?
大语言模型在各种与语言相关的任务中表现出了显著的零样本泛化能力,包括搜索引擎。然而,现有的工作主要利用LLM的生成能力进行信息检索,而不是直接进行段落排序。这篇EMNLP2023的论文(Outstanding Paper)研究了LLM是否擅长搜索排序的问题。
# Is ChatGPT Good at Search? Investigating Large Language Models as Re-Ranking Agents
两个问题:
- ChatGPT在段落重排序任务中的表现如何?
- 如何在一个更小的专用模型中模仿ChatGPT的排序能力?
对第一个问题,文章提出了permutation generation的方案,让LLM直接输出对一组段落的排序组合。 对第二个问题,文章采用蒸馏技术,以在更小的专用排序模型中模仿ChatGPT的段落排序能力。
具体而言,零样本段落重排序的三种指令如下图,灰色和黄色块表示模型的输入输出:
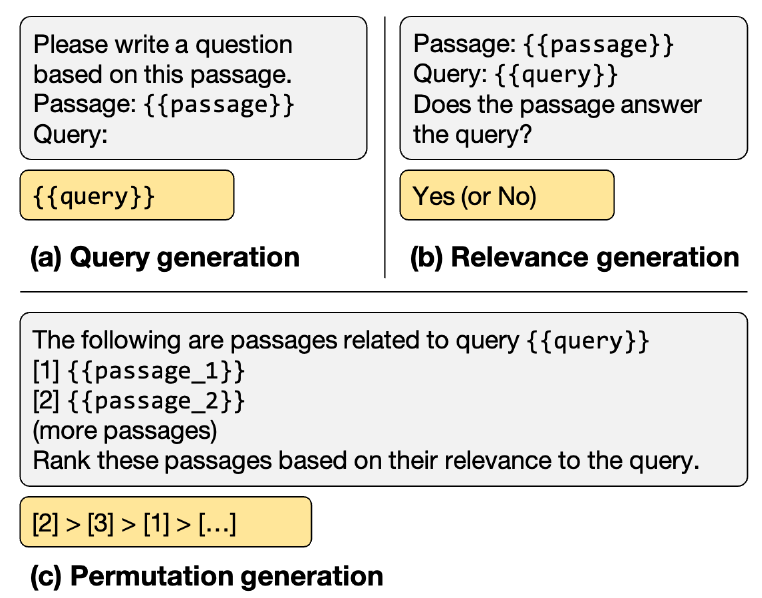
- 查询生成:依赖于LLM的对数概率,根据段落生成查询。
- 相关性生成:指示LLM输出相关性判断。
- 排序生成:生成一组段落的排序列表。
文章的方案是最后一个,将一组段落输入到LLM,每个段落都有一个唯一的标识符(例如,[1],[2],等)。然后,要求LLM根据段落与查询的相关性生成降序排列的段落顺序。段落使用标识符进行排序,格式如[2] > [3] > [1] > [...]。该方法直接对段落进行排序,而不生成中间的相关性分数,有点类似list-wise的思想。
用于排序的prompt模板如下:
text-davinci-003
This is RankGPT, an intelligent assistant that can rank passages based on their relevancy to the query. The following are passages, each indicated by number identifier []. I can rank them based on their relevance to query: [1] [2] (more passages) ... The search query is: I will rank the passages above based on their relevance to the search query. The passages will be listed in descending order using identifiers, and the most relevant passages should be listed first, and the output format should be [] > [] > etc, e.g., [1] > [2] > etc. The ranking results of the passages (only identifiers) is:
gpt-3.5-turbo和gpt-4
system: You are RankGPT, an intelligent assistant that can rank passages based on their relevancy to the query. user: I will provide you with passages, each indicated by number identifier []. Rank them based on their relevance to query: . assistant: Okay, please provide the passages. user: [1] assistant: Received passage [1] user: [2] assistant: Received passage [2] (more passages) ... user Search Query: . Rank the passages above based on their relevance to the search query. The passages should be listed in descending order using identifiers, and the most relevant passages should be listed first, and the output format should be [] > [], e.g., [1] > [2]. Only response the ranking results, do not say any word or explain.
考虑到LLM的输入token长度限制,论文采用滑动窗口策略对更多的文档进行排序。直接看示例:
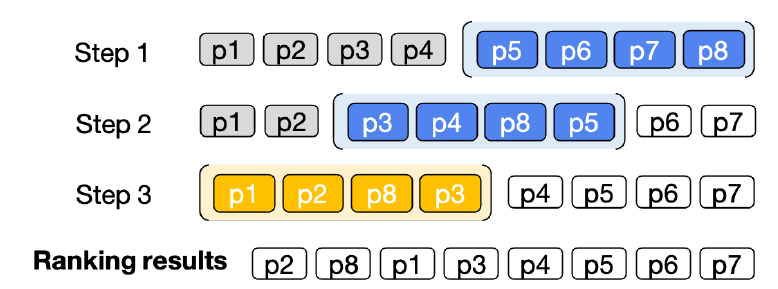
第一步先对第5-8位排序,p8和p5胜出;然后第二步对第3-6位排序,p8和p3胜出;最后对第1-4位排序,得到最终排序。
滑动窗口的方案简单,不过笔者认为从全局来看,该方案不太公平,因为不同段落之间的排序未必存在偏序传递关系:图中p4和p5未必比p6和p7更优。不过今天来看这个滑动窗口策略也没有太大意义了,LLM的长度限制已经不再是个问题。
另一方面,考虑到成本问题,用GPT-4做排序还是太贵。因此,将GPT-4的搜索排序能力蒸馏到更小的模型是很自然的做法。论文从MS MARCO中抽取了10,000个查询,并使用BM25为每个查询检索到20个候选段落。蒸馏的目标在于减少学生模型和ChatGPT对它们排序输出之间的差异。
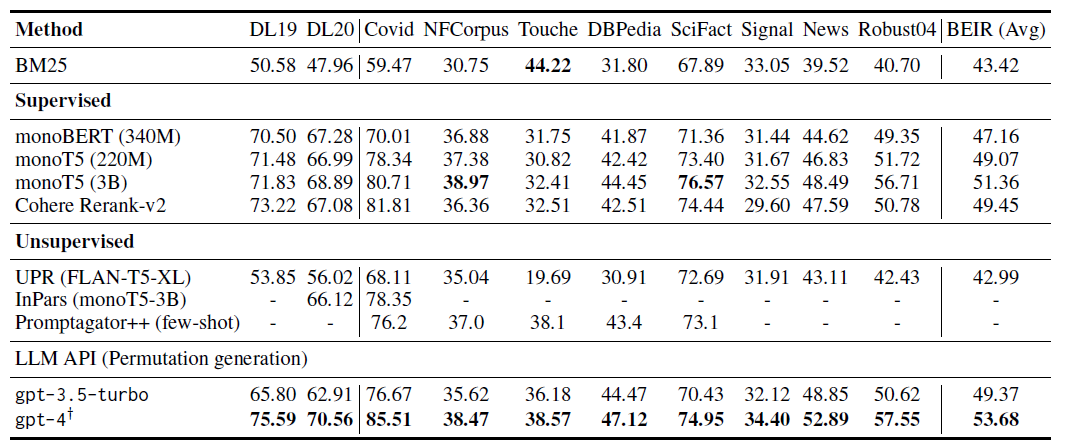
上表展示了从TREC和BEIR数据集中获得的评估结果,可以得出几个结论:
- GPT-4在这两个数据集上表现优异。值得注意的是,与monoT5 (3B)相比,GPT-4在TREC和BEIR上的nDCG@10分别平均提高了2.7和2.3。
- ChatGPT在BEIR数据集上也表现不错,超过了大多数监督基线。
- 在BEIR上使用GPT-4对由ChatGPT重排序的前30个段落进行重新排序。该方法取得了良好的结果,而成本仅为仅使用GPT-4进行重排序的1/5。
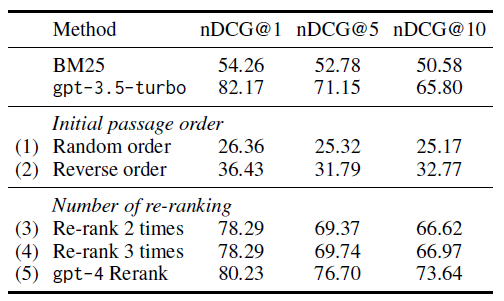
上表展示了在TREC数据集上的消融实验,有如下发现:
- 初始段落顺序敏感:原始实现使用BM25的排名结果作为初始顺序,这里实验了另两种方案:随机顺序和反向BM25顺序。结果显示模型对初始段落顺序非常敏感,原因可能是因为BM25提供了较好的初始顺序,仅使用单个滑动窗口重排就能获得不错的结果。
- 滑动窗口重排序次数的影响:表中的方法(3)(4)显示进行多次重排序可能会提高nDCG@10,但会损害nDCG@1排序性能(例如,nDCG@1下降了3.88)。而方法(5)使用GPT-4对前30个段落进行重排序显示出显著的准确性提升。这提供了一种将ChatGPT和GPT-4结合使用的方案,以减少使用GPT-4模型的高成本。