深度文本检索模型:DPR, PolyEncoders, DCBERT, ColBERT
文本匹配与检索是NLP中的经典问题,主要研究两个文本的主义相似度,通常用在检索系统的召回阶段。传统的召回方案如tf-idf和BM25具有速度优势,但在语义匹配方面有所欠缺。随着预训练模型的发展,使用深度模型进行文本检索变得必要与可行。
使用深度模型进行检索,主要矛盾是检索性能与速度的平衡。 本文对几篇经典的文本检索模型工作DPR, Poly-Encoders, DC-BERT 与 ColBERT 的主要思想进行介绍与对比。
[EMNLP2020] Dense Passage Retrieval for Open-Domain Question Answering
[ICLR2020] Poly-encoders:Architectures and Pre training Strategies for Fast and Accurate Multi sentence Scoring
[SIGIR2020] DC-BERT: Decoupling Question and Document for Efficient Contextual Encoding
[SIGIR2020] ColBERT: Efficient and Effective Passage Search via Contextualized Late Interaction over BERT
文本匹配最经典的模型无过于双塔模型 (Siamese Network),也即图(a)所示的情形。思路很直接,把query和doc进行分别编码成一个向量,再对它们计算cosine similarity或点积作为最终打分。双塔模型的代表作有DSSM,SmartReply还有下文提到的DPR。
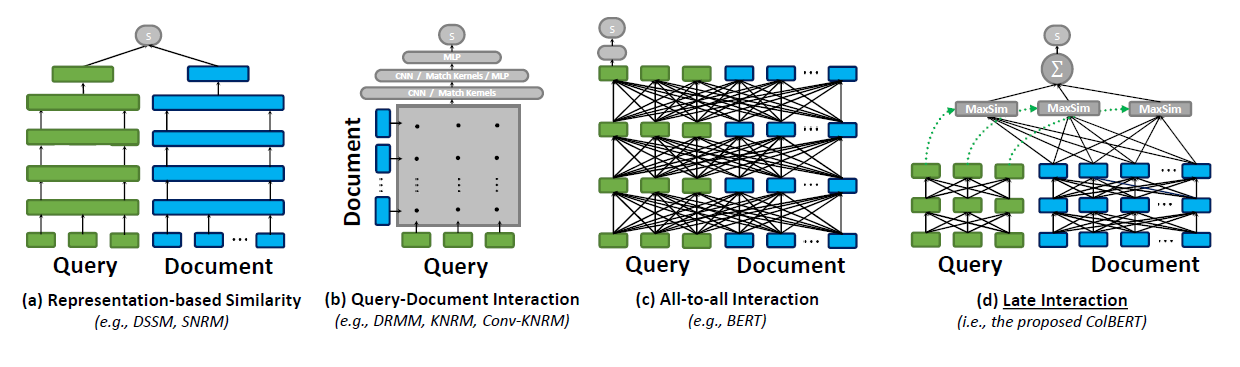
在预训练模型兴起之后,所谓的 full interaction (图b中称为 all-to-all interaction,或在Poly-Encoders中称之为 cross-encoder,都是一个意思) 的形式变得常见。思路一样直观,把query和doc都输入预训练模型,通过attention在整个神经网络的每一层都进行交互计算,想想都觉得效果不错,对吧?实验结果确实也证明了这一点。但缺点是,计算速度慢,对于低延迟的应用场景不适用。**更严重的问题是,doc无法进行线下预计算和建立索引。**因此,这种方案效果虽好,但不能应用在大规模文本检索任务上。一种折衷的方案是将此模型用在精排阶段而非召回阶段,有点“如果不能解决问题,就解决提出问题的人”的意思,哈哈。
另一个折衷方案则是所谓 late interaction 。前半程先用各种方法进行预计算编码,然后在后半程对编码后的向量做full interaction,达到性能与速度折衷的目的。如 Poly-Encoders, DC-BERT 和 ColBERT 就是从这个角度出发而提出的模型。
下面我们具体看一下这几个工作的想法和特点。
DPR
[EMNLP2020] Dense Passage Retrieval for Open-Domain Question Answering
DPR发表在EMNLP 2020,双塔模型,主要idea在于双塔使用了两个独立的BERT,今天看来没什么特别的,但在BERT出来两年的时间,居然没人这么做,也挺令人意外 :-)。
query和doc的相似度定义:
$$sim(q, p) = E_Q(q)^TE_P(p)$$
既然是双塔模型,自然就可以当做检索器使用,可以把doc都编码成向量并索引,这里做vector search的工具是Facebook的FAISS。
Poly-Encoders
[ICLR2020] Poly-encoders:Architectures and Pre training Strategies for Fast and Accurate Multi sentence Scoring
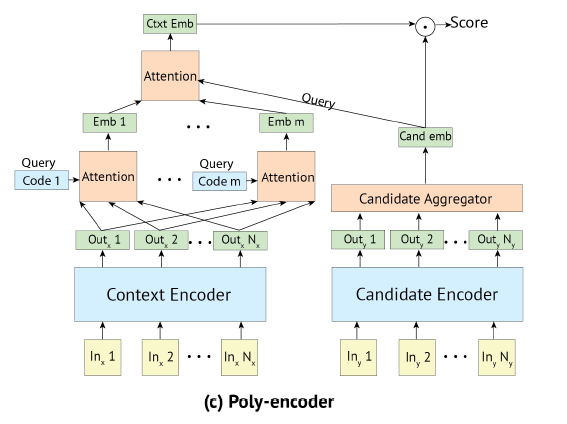
为了解决上文提到的不能离线索引的问题,并兼顾性能,Poly-Encoders被提了出来,本质上也是个双塔模型。那么如何让query和doc进行更为深入的交互?也是本文的主要创新点,就是在query embedding的计算上,通过训练m个独立的encoder,把query编码成m个向量并求和,再在最后一层进行交互。
如果说full interaction是在深度上进行充分交互,Poly-Encoders则是在query宽度上进行扩展,并达到充分交互的目的。
注意,这里的宽度扩展仅限于query,因为它是线上计算的,而doc只经过一次编码并进行了索引。这里对应用场景有假设:
the input context, which is typically much longer than a candidate
同时,超参数m值的选择会影响到线上推理的速度与性能。做vector search也是使用FAISS。
query和doc使用两个独立的Transformer进行编码。其中query编码的计算:
$$y_{ctxt} = \sum_i w_i \sum_j w_{j}^{c_i}h_j$$
DC-BERT
[SIGIR2020] DC-BERT: Decoupling Question and Document for Efficient Contextual Encoding
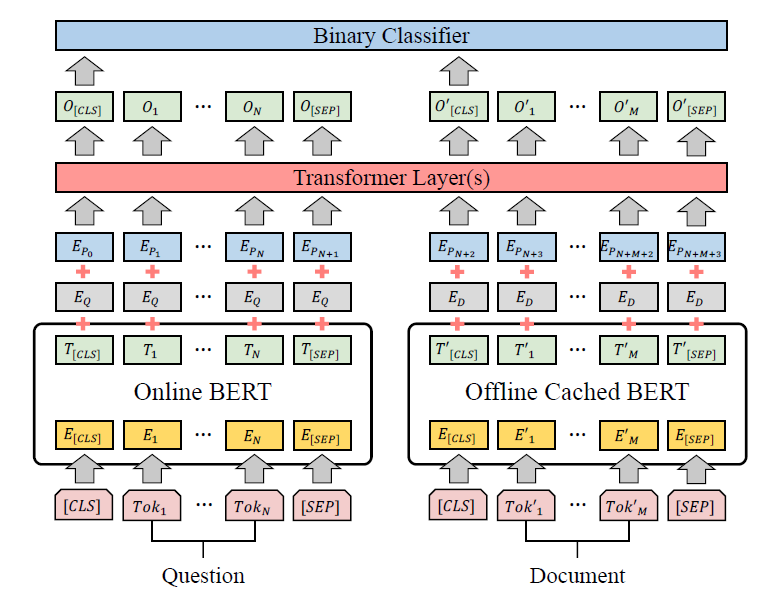
DC-BERT是一篇SIGIR2020的短文,思路是典型的late interaction。主要贡献是速度快,包括一些小的优化,如query编码只计算一次。query和doc的交互会通过k层Transformer Layer完成,可以通过调整超参数k,达到性能与速度的折衷。
DC-BERT使用两个独立的BERT模型对query和doc进行编码:
DC-BERT contains two BERT models to independently encode the question and each retrieved document.
ColBERT
[SIGIR2020] ColBERT: Efficient and Effective Passage Search via Contextualized Late Interaction over BERT
ColBERT是SIGIR2020的一篇长文,对已有的工作做了比较全面的总结,本文开始的对比图就取自ColBERT论文。
ColBERT对query和doc的计算是共享同一个BERT,但引入了前缀符[Q]与[D]来标识不同的输入:
We share a single BERT model among our query and document encoders but distinguish input sequences that correspond to queries and documents by prepending a special token [Q] to queries and another token [D] to documents.
ColBERT的主要思想是对query与doc在token-level的编码进行匹配计算,并通过MaxSim算符取出最大值并求和作为最终的分数。 读起来比较拗口,看图和公式更容易理解。
$$E_q = Normalize(CNN(BERT("[Q]q_0q_1 \ldots q_l [mask][mask]…[mask]")))$$
$$E_d = Filter(Normalize(CNN(BERT("[Q]d_0d_1 \ldots d_n))))$$
注意这里$E_q$与$E_d$不是一个向量,而是对每个token编码的向量组。其中CNN的含义应该是linear层的降维:
Given BERT’s representation of each token, our encoder passes the contextualized output representations through a linear layer with no activations. This layer serves to control the dimension of ColBERT’s embeddings, producingm-dimensional embeddings for the layer’s output size m.
Filter的含义是去掉标点符号的token表示:
After passing this input sequence through BERT and the subsequent linear layer, the document encoder filters out the embeddings corresponding to punctuation symbols, determined via a pre-defined list.
相关性分数计算:
$$S_{q,d}=\sum_{i \in [|E_q|]} \max_{j \in [|E_d|]} E_{q_i} \cdot E_{d_j}^T$$
即对query中的每个token与doc中的所有token计算Sim值并取出最大值,再将其求和作为最终分数。直观上感觉这种算法与BM25等文本匹配算法类似,但计算粒度更为精细。
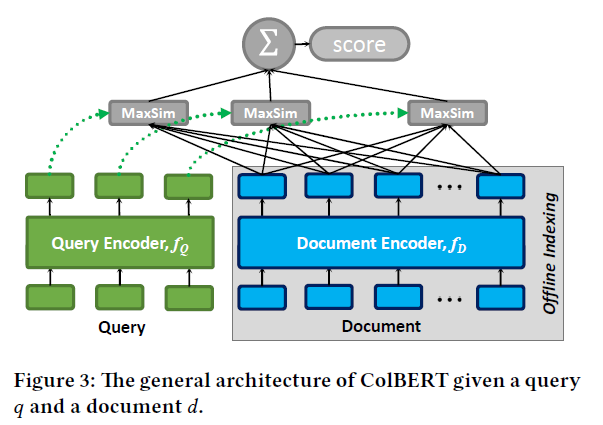
上图可见,doc可以被离线计算和索引。值得一提的是,这里的交互部分是不可训练的:
We fine-tune the BERT encoders and train from scratch the additional parameters (i.e., the linear layer and the [Q] and [D] markers’ embeddings) Notice that our interaction mechanism has no trainable parameters.
对query和doc的编码器除了使用预训练模型,也可以使用CNN/RNN等不同模型,也就引出了不同的检索器变种,但本质上都类似。从效果和直觉上来看,使用预训练模型作为编码器应该是一种比较自然的思路。
Even though ColBERT’s late-interaction framework can be applied to a wide variety of architectures (e.g., CNNs, RNNs, transformers, etc.), we choose to focus thiswork on bi-directional transformer-based encoders (i.e., BERT) owing to their state-of-the-art effectiveness yet very high computational cost.
本文对几篇典型的深度文本检索模型进行了总结与对比,希望对大家有所帮助和启发。