LIMA: Less Is More for Alignment 简读
LIMA是五月份的一篇网红文,发表后引起了广泛的讨论。它用极致简约的SFT方案训练了一个不错的模型,希望证实表面对齐假设 (Superficial Alignment Hypothesis):
大模型中几乎所有知识都是在预训练中学习的,指令微调只是一个很简单的过程,让模型学到与用户交互的形式。
为证明上述假设,作者们推测仅需要少量的指令微调数据(1000条)就可以教会模型产生高质量输出。此外,1000条SFT数据就达到了很好的指令微调效果,也说明了高质量数据对于模型的重要性,这一点与 Textbooks Are All You Need 有异曲同工之妙。
# LIMA: Less Is More for Alignment
高质量SFT数据构造
LIMA的核心问题在于如何构建这样1000条极简但又具有多样性的指令数据。具体而言,这个数据集的输入比较多样,但要保持回复风格一致。它们的来源如下表:
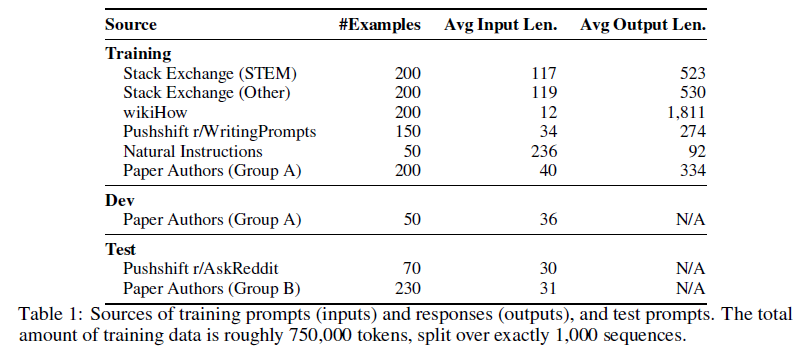
由上表可得,该数据集既有不同社区问答的问题,也有人工撰写的数据。下面介绍不同数据源的数据构造方法。
社区问答
社区回答主要有三个数据源:Stack Exchange、wikiHow和Pushshift Reddit数据集。其中前两者的回答与我们希望的方向基本一致,因此可以自动挖掘。而Reddit的高赞回答会存在幽默和恶搞的情况,需要采用手动改写的方式让它们与预期风格一致。
Stack Exchange
Stack Exchange是一个在线问答社区,每个社区都有自己的主题。首先将它们划为两类,STEM相关(包括编程、数学、物理等)和其他内容(英语、烹饪、旅行等)。然后在这两个集合中分别采样200个问题和答案,以获得不同领域的均匀的样本,再在其中分别选择得分最高且标题自成一体的问题。之后,选择每个问题的最佳答案。为了让回复风格符合有用的AI助手的标准,作者还过滤了过短、过长、第一人称写作的回答,以及引用回答。此外,还删除了回答中的链接、图片和HTML标记,仅保留代码块和列表。
wikiHow
wikiHow是一个在线维基风格的社区,涵盖了各种主题超过24万篇高质量文章。作者从其中先采样类别再采样文章,共采样200篇文章,以保证多样性。然后将文章标题作为提示,将文章正文作为回复,还对一些链接和图片进行了清洗。
The Pushshift Reddit Dataset
Reddit是世界上最受欢迎的网站之一,用户可在这些子论坛中分享和讨论各种内容。Reddit的内容更偏向于娱乐而不是提供帮助,所以往往诙谐、讽刺的评论会获得高赞。因此,我们将样本限制在两个子论坛r/AskReddit和 r/WritingPrompts,并从中手动选择获赞最多的帖子中的示例。作者从r/AskReddit中选择了70个提示示例并将其用于测试集,从WritingPrompts中选择了150个提示及高质量答案,涵盖了诸如爱情诗和短篇科幻故事等主题,将其添加到训练集。
手动编写的示例
为进一步使数据多样化,作者们自己也贡献了不少示例。首先将作者分成AB两组,大家按照自己或朋友的兴趣,每组写250个示例,然后将A组的200个加入训练集,剩下的50个加入开发集,将B组有问题的数据过滤后,把剩下的230个示例用作测试集。
此外,作者还从Natural Instruction数据集中选择了50个文本生成任务。 它们包括文本摘要,改写和风格转换任务等,每个任务都随机采样一个样例加入训练集。尽管用户输入的形式与这些提示可能不同,但加入它们可以进一步增加提示的多样性,同时增加模型的鲁棒性。
模型训练与实验结果
构建完这1000个微调提示示例后, 基于LLaMa 65B的版本用此数据集进行微调得到LIMA模型。训练采用标准流程,不必赘述。
模型效果主要采用人工评估的方式,与OpenAI的DaVinci003模型和使用52000条指令微调数据的65B Alpaca模型进行了比较。对每个测试集中的提示输入生成一个回复,然后让标注员比较与基线模型相比,哪个回复更好。另外,还用GPT-4重复了此标注,结果如下:
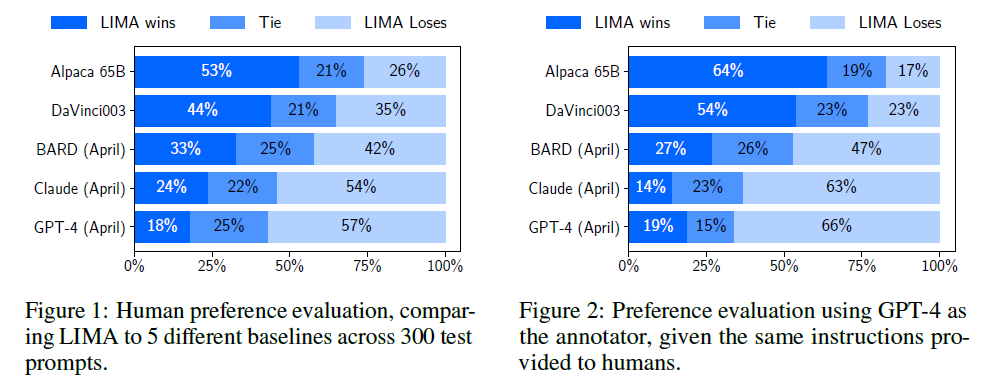
由上图可见,人工标注与GPT-4标注具有同样的趋势,因此我们以人工标注结果为主要参考。首先,虽然Alpaca使用了52倍之多的指令微调数据,但依然不及LIMA。其次,即使使用RLHF技术的DaVinci003也不如LIMA的性能。BARD、Claude和GPT-4总体来看超越了LIMA的效果,但LIMA在许多情况下依然输出了更好的回复。
LIMA用实验证明了仅用1000条精心撰写的提示数据就能训练出一个强大的模型,展示了高质量数据的作用与威力。但该结果也存在一定的局限性,构建这样的高质量数据集耗时耗力,很难扩展。另外,LIMA并不是一个产品级模型,仍旧处于实验阶段,它也会产生较差的结果。LIMA验证了绝大部分的知识是在预训练阶段习得的,一定程度上也说明了有效的SFT甚至可以超越RLHF的结果。