基于LLM评估搜索系统
搜索系统的评估和调优很大程度上依赖于相关性标签——这些标签标注了某个文档对特定搜索和搜索者是否有用。理想情况下,这些标签来自真实的搜索用户,但要大规模收集这些数据非常困难,所以典型的实验依赖于第三方标注人员,但他们也可能产生不准确的标注。标注质量一般通过持续的审核、培训和监控来管理。
微软(Bing搜索组)在SIGIR'24提出了一种“反其道而行之”的方法:从真实的用户获取反馈,并利用这些反馈来选择一个与之相符的LLM及其提示词,然后令该LLM大规模地产生标签。实验表明,LLM的准确性与人工标注者相当,并且在找到最佳系统和最难的查询方面同样有用。
[SIGIR2024] # Large Language Models can Accurately Predict Searcher Preferences
简介
相关性标签,也就是标注某个结果是否满足搜索用户需求,对于搜索排序模型至关重要。黄金标签可能源自一个相关性评估员,他们自己开发查询主题并对结果进行标注。更理想的情况是标签的来自真实的搜索用户,他们在实际场景中进行了查询,准确知道自己想要找到什么,并对什么是相关内容提供了准确反馈。
第三方评估员可能会因为误解搜索者的偏好而与黄金标签产生分歧。如果评估人员系统性地误解了搜索者的需求(即标签有偏差),那么增加数据量也无法解决这一问题。人工标注,尤其是与众包标注还可能导致其他众所周知的问题,包括错误、其他偏见、串通,以及恶意或“垃圾”工人。这些标签可能质量低下,如果将其用于训练或决策,将会导致检索系统学习到错误的方向。
获得更高质量标签的标准路径涉及多个步骤。首先是通过访谈、用户研究、直接反馈他们的偏好以及点击等隐性反馈来了解真实的搜索者。研究相关的相关性标签,并寻找系统性错误,可以发现标注员的偏差。最后一步是通过参考指南或示例来培训标注员,以尽量减少未来的错误。例如,Google使用超过170页的指南来培训标注人员,让他们了解什么是一个好的Google搜索结果。
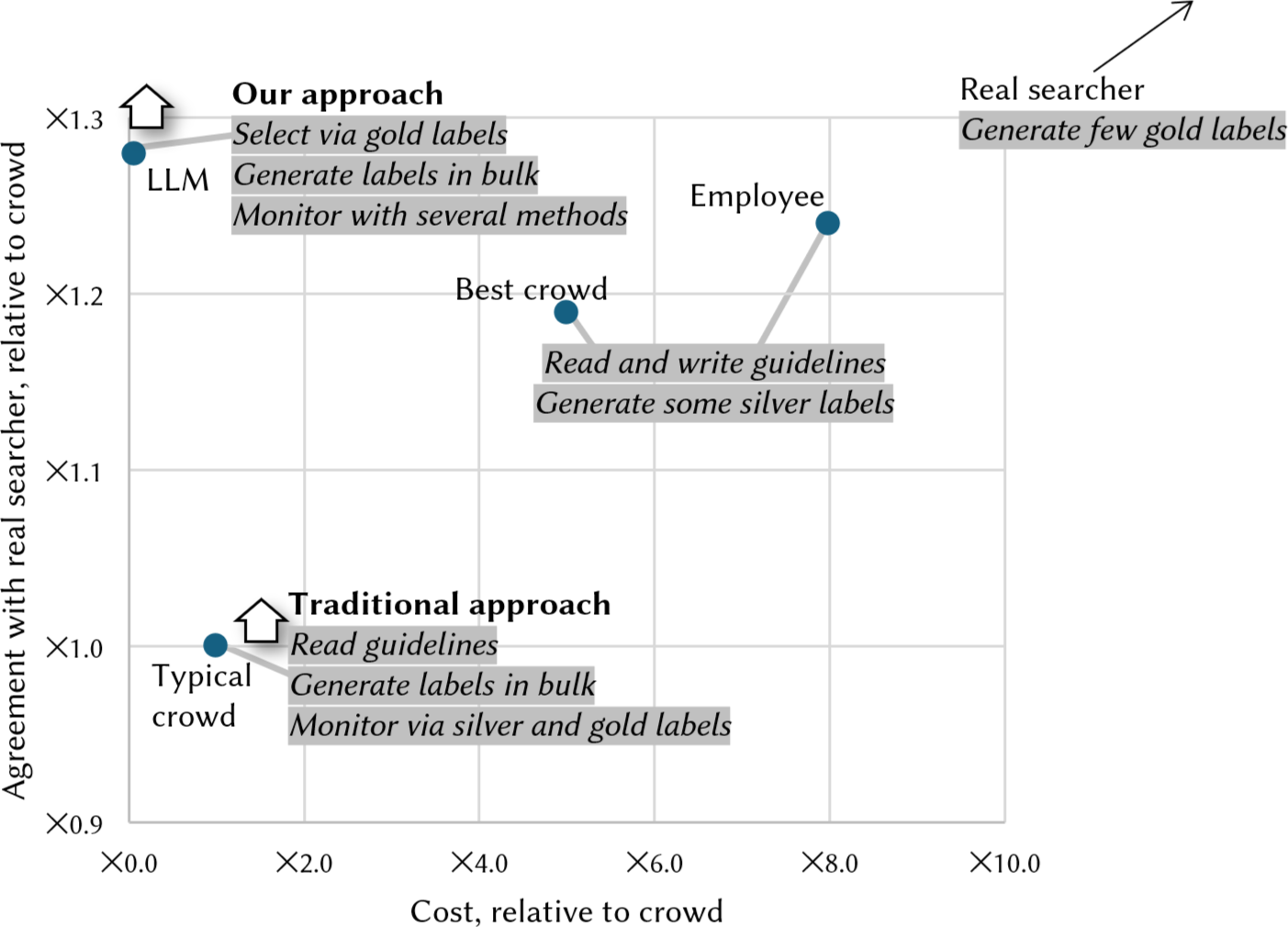
上图是几种方案开销和效果的对比:真实用户生成的黄金标签最好,但开销也最大;传统方案开销一般,但效果也一般;本文提出的方案效果很好,且开销很低。优化目标就是往左上方来:高准确率低开销。
本文提出的方案是先取少量样本的反馈,让它们先反映真实搜索者的偏好。然后选择一个LLM提示词来生成标签,以使这些标签与真实数据最为匹配。
用LLM生成标注
论文首先使用TREC-Robust 2004数据集验证了想法,看LLM 是否能够复现由专家标注员生成的原始 TREC 标签,然后主要问题就在于Prompt Tuning。

上图展示了Prompt的整体结构。斜体字是占位符,每个主题和文档的内容会有所不同,或根据提示的其余部分进行调整,阴影部分的文字是可选内容。
Instrctions, role:提示词分为四个部分。第一部分给出任务指令。这些指令基于给 TREC 评估员的指令进行了调整,主要有两处变化:首先,TREC 指令中包含的关于标签一致性的内容与 LLM 场景无关,因此在此省略。其次,短语“you are a search engine quality rater.……”替换了 TREC 文本中一些讨论评估员过去开发 TREC 轨道经验的内容。网页质量是一个复杂的概念,但搜索提供商经常发布他们在寻找什么的提示。特别是,Google 的标注指南使用了“搜索质量评估员”这个短语。因此,提示中有一半包含了“你是一名搜索质量评估员,负责评估网页的相关性”这个短语,作为参考指南和相关讨论的缩写。
Context, description, narrative:提示的第二部分提供了要标注的查询/文档对。始终包含查询,在某些配置中,也包含了来自 TREC 描述和叙述字段的更详细版本,并提供了文档本身的文本。
单独的查询是信息需求的不完整表示,但 TREC 主题还包含描述查询含义的额外文本描述(description)以及哪些文档应被视为回复(narrative)的说明。例如,对于查询“哈勃望远镜的成就”,描述重申该查询是关于自 1991 年发射以来的空间望远镜的成就,叙述澄清这指的是科学成就,因此仅谈论缺陷和维修的结果将被视为不相关。在某些提示中,论文将这些文本写在“description””和“narrative”字段。
Further instructions, aspects, multiple judges:提示的第三部分重述了任务,包括指令“将这个问题分解为多步”,使用了“思维链”的方法明确考虑搜索者的意图以及文档。在某些变体中,除了总体评分外,还可以明确要求对主题性和可信度进行评分。此外,还可以要求模型模拟几个人工评审员,并给出每个评审员的评分。
一种直接的方法是对每对(查询,文档)请求一个总体标签。根据经验,作者发现将几个方面详细列出,并对这些方面进行评分,再要求总体标签效果更好,这种思路与思维链方法不谋而合。受到这些想法的启发,在一些提示变体中,可以要求对“相关性”的多个方面进行标注,最终给出一个总体标签。
为了降低不同标注员的标注差异,可以要求模型模拟多个评审员,从一个 LLM 调用中模拟生成五个评审员的输出。虽然它们实际上并不是独立的标注者,但作者们发现这种方法有效。
Output:提示的最后指定了输出格式,并包括一个 JSON 片段以鼓励生成正确的格式。
标签评估与结果
标签评估的逻辑简单来说,就是要与人类的打标一致。可以通过混淆矩阵来总结机器和人工标签之间的差异。如果为两个级别分配 0 和 1 的分数,则可以进一步计算人工和机器标签之间的平均差异。论文用平均绝对误差 (MAE) 来报告准确性,其中 0 表示两个来源的标签始终一致,1 表示它们最大程度上不同。
之前的研究中,使用 TREC 评估员与 GPT-3.5 和 YouChat LLM 之间的 Cohen’s 𝜅 系数,这里也用同样的指标。𝜅 的范围从 1(完全一致)到 0(仅偶然一致)再到 -1(完全不一致)。
Prompt Feature的效果
用上节的Prompt对数据集进行打分并取平均,如果结果不可解析(占比90/96000),则直接丢弃。
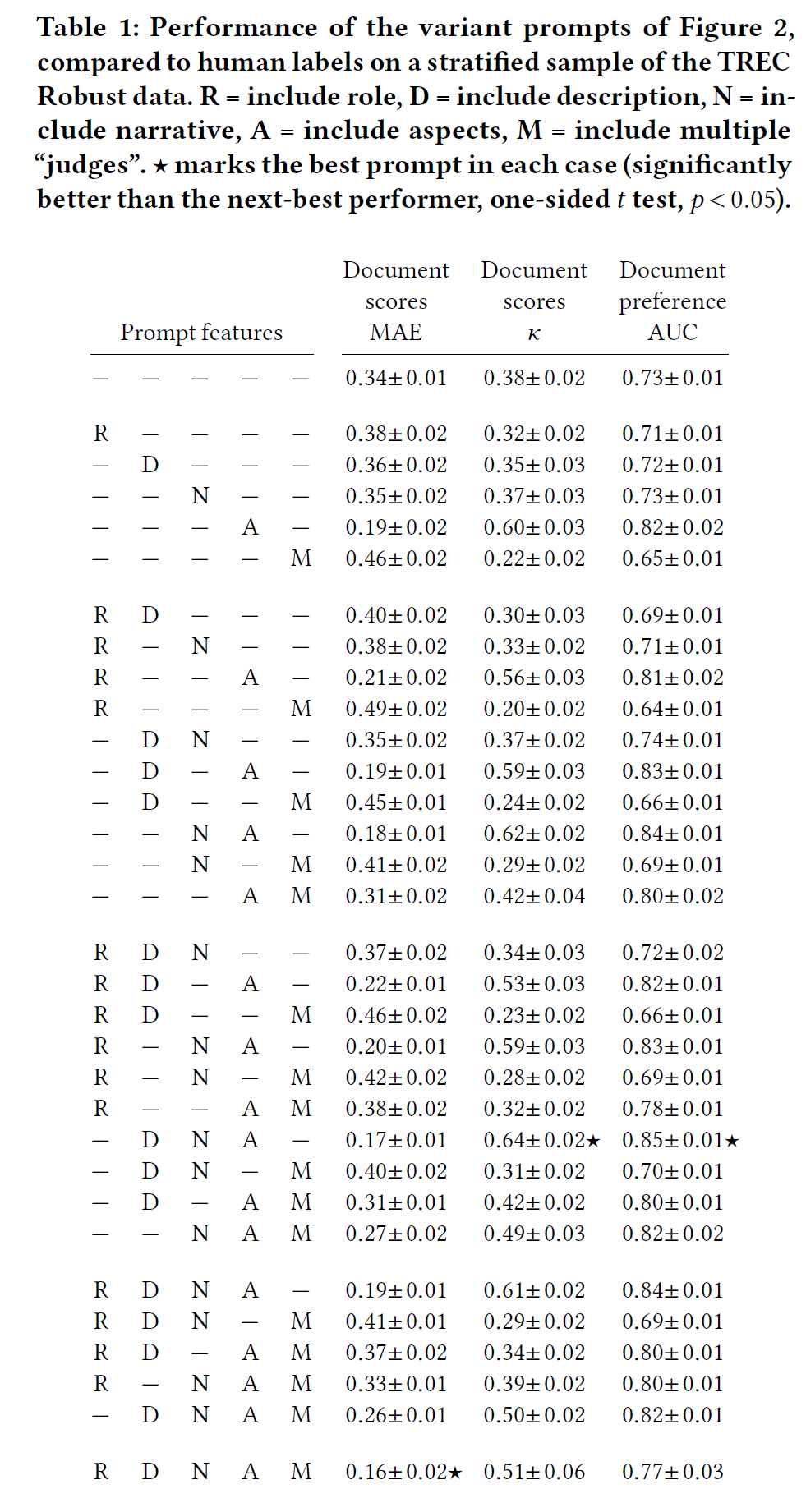
上图显示了实验结果,其中R = include role, D = include description, N = include narrative, A = include aspects, M = include multiple “judges”。共有32种prompt的排列组合,例如,--N-M代表使用narrative和multiple judges的方案,最优结果用星号标了出来。可见,最优prompt包括description, narrative和aspects三个部分。
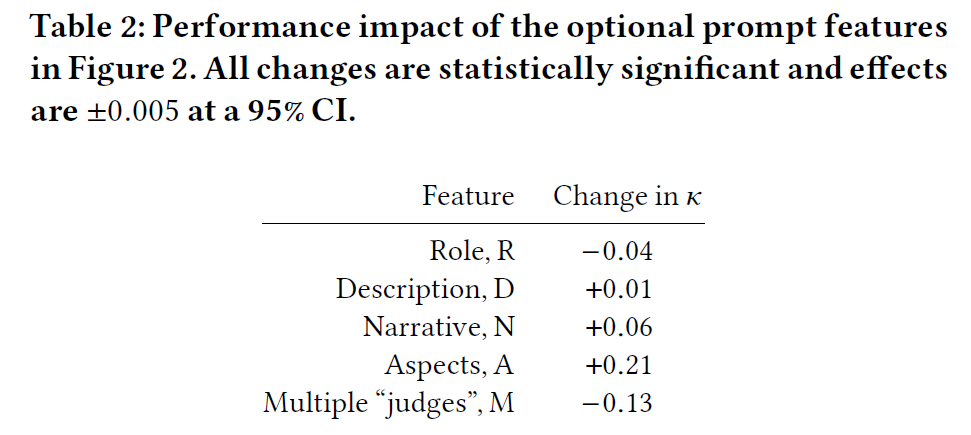
这些prompt feature的效果如上图所示。与预期相反,由于R和M因素的影响,导致了显著的负面效果:𝜅 分别平均下降了 0.04 和 0.13。添加D仅微幅提升(仅增加 0.01 𝜅 分值)。添加N带来了 0.06 的提升;虽然提升不大,但可能是因为 LLM 的背景知识(尤其是在公共数据上)足够丰富,因此叙述内容除了查询词之外并没有带来太多额外帮助。上面这些分析都是孤立的,但实际上某些组合也可能带来效果提升,如上面的最优方案-DNA-。
Prompt改写的影响
Prompt本身对效果也会有影响,比如对其措辞稍加改动:assume that you are writing a report -> pretend you are collecting information for a report,或 you are collecting reading material before writing a report,打标效果是否会变化?
在上面最优的-DNA-提示上生成了42种关于Given a query and a web page . . . Otherwise, mark it 0的不同改写,结果如下:
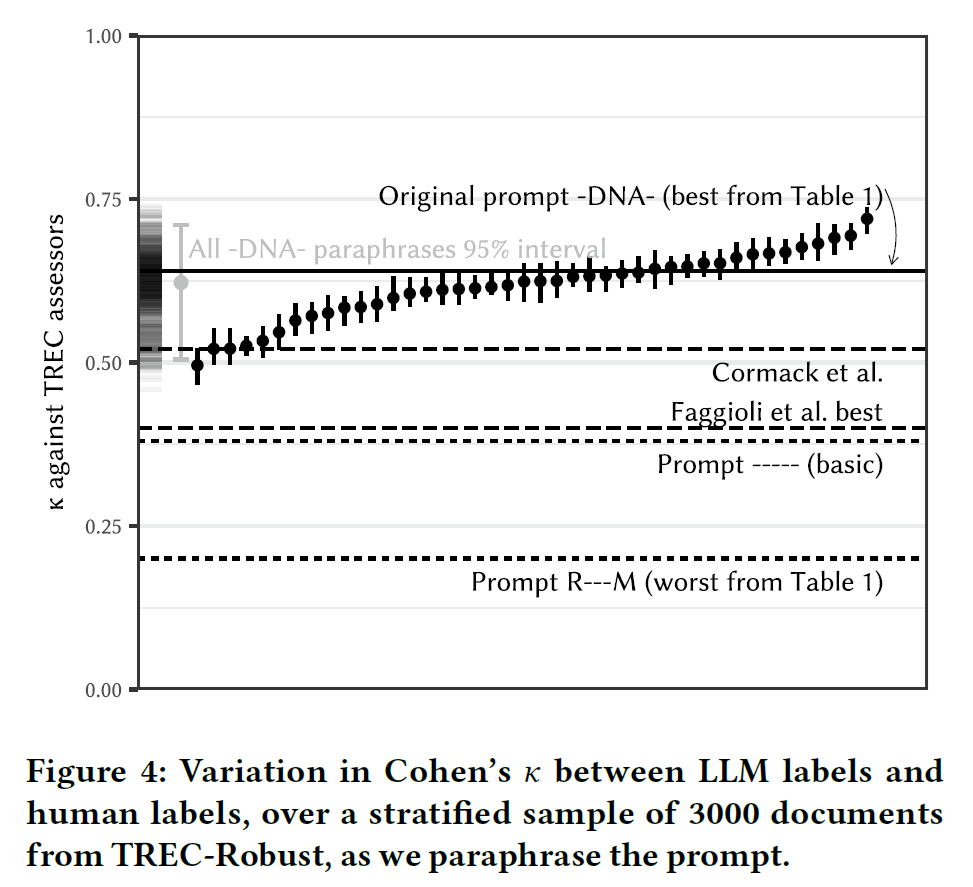
可以看出,即使没有改变提示的总体设计,仅对措辞进行小幅调整也可能导致明显不同的性能。其次,明智的做法是先固定总体设计,然后再探索重构措辞和其他选项。
Bing的实践
Bing多年来大量使用众包工人,以应对所需的标签数量、语言和市场的规模。尽管有系统来检测低质量的标签和工人,但这种规模带来了偏见、错误以及对抗性工人的成本。

上图可见,LLM 表现得非常出色。它们比任何第三方标注者(包括员工)都更准确;与任何人类评审员(包括众包工人)相比,它们的端到端速度更快;它们的吞吐量更高;而且当然成本要低得多。端到端速度的显著提升也帮助 Bing 的工程师们能够尝试更多方案,完成更多工作。自 2022 年底以来,Bing一直在将 LLM 与专家人类标注者结合使用,用于大部分的离线指标评估。
作为额外的安全检查,Bing每周都会从模型中抽取近期标签的分层样本。由训练有素的评估人员重新标注这些样本,并监控分歧率或分歧模式的变化;任何变化都由熟悉众包和 LLM 过程的指标团队进行调查。实际上,出现重大变化的情况很少,而且支持 LLM 的解决方案和支持人类的解决方案比例相当。
除了对基于 LLM 的标签进行人工监督外,还定期重新标注一大批查询,旨在监控标注系统的健康状况。
因此,Bing的系统介于 Clarke 等人提出的“人工验证”和“完全自动化”选项之间,既具有自动化的规模,也通过人工验证进行了一些控制和质量保证。分歧及其分析为未来的指标开发、黄金集以及 LLM 标注器的发展提供了信息。
结论:使用 LLM 来标注文档的相关性,并因此评估搜索系统是可行的。其性能可以与 TREC 评委相媲美,明显优于众包评委。这种方法在 Bing 中被证明有效,并且已经用于提高速度、降低成本,显著改进了系统。