Brief Introduction to NLP Prompting
Prompting is one of the hottest NLP techniques. This is a brief introduction to prompting by three questions: what's prompting, why prompting and how to prompting. As a brief introduction, we do not cover too much details but try to summarize the main idea of prompting. For more details, please refer to the original papers.
What's Prompting
I don't find a rigorous defintion for prompting. Just quoting some pieces from papers.
Users prepend a natural language task instruction and a few examples to the task input; then generate the output from the LM. This approach is known as in-context learning or prompting.
By: # Prefix-Tuning: Optimizing Continuous Prompts for Generation
This description brought two concepts:
in-context learning and prompting.
Another explantion from probability perspective:
Prompting is the approach of adding extra information for the model to condition on during its generation of Y .
By: # The Power of Scale for Parameter-Efficient Prompt Tuning
For example, to analyze the sentiment of sentence
Best pizza ever!, we construct a template like this:
Best pizza ever! It was ___.Then the sentiment analysis task is reduced to a cloze task. The
prediction probability of great would be much higher than
bad. Therefore, through constructing proper templates, we
are able to extract the potential of pretrained language models.
Pattern-Exploiting Training PET explains why prompting works:
This illustrates that solving a task from only a few examples becomes much easier when we also have a task description, i.e., a textual explanation that helps us understand what the task is about.
The main difference between pretrain-finetuning and prompt-tuning is that the former makes the model fits the downstream task, while the latter elicits the knowledge from the model by prompting.
Why Prompting
Recently language models are typically of large volumes of parameters. Given kinds of downstream tasks, fintuning produces a model copy for each of them. A straightforward approach is light-weight finetuning, aka freeze most of the parameters while only a small number of parameters are finetuned.
On the extreme end, GPT-3 can be deployed without any task-specific tuning. By prompting, we can easily accomplish few-shot learning or even zero-shot learning.
Moreover, by designing good templates, the model can achieve comparable or even better performance on many benchmarks.
Besides, for the sake of negligible modification to the model, enabling personalization is more viable. Because we can only store small number of parameters for each user to accomplish user-specific customizations.
How to Prompting
The next question, how to find a proper prompt template?
In this section, we list the main idea of the papers with different prompt templates. For simplicity, we keep the same notation as the original paper.
Discrete Prompt Templates
Design prompts is non-trivial and a little bit tricky. Good understanding of language model and tasks are required. Many efforts should be paid to find suitable pattern which leads to better performance.
Such discrete prompt is named hard prompt.
PET
# Exploiting Cloze Questions for Few Shot Text Classification and Natural Language Inference
PET reformulates the text input as cloze-style phrases to help
language models understand a task. PET proposed different templates for
different tasks. The templates look like this (a and
b are text inputs):
It was ___. a
a. All in all, it was ___.
a ( ___ ) b
[ Category: ___ ] a bAutoPrompt
# AutoPrompt: Eliciting Knowledge from Language Models with Automatically Generated Prompts
Essentially, AutoPrompt is a sort of discrete natural language template. The template has three parts: sentence, trigger tokens and prediction token.
{sentence} [T][T] . . [T] [P].AutoPrompt generates trigger tokens by maximizing the label liklihood over the labeled examples. These trigger tokens are regarded as the related knowledge of the task. Based on this generated template, the model generalizes to each specific task.
Continuous Prompt Templates
Generating natural language templates requires manual efforts and guesswork. Actually, the prompt is not necessarily to be natural language, it can be of differnet styles such as a continuous vector. As a result, another line of work try to develop continuous prompt templates which is obtained via training.
Such continuous prompt is named soft prompt.
Prefix-Tuning
# Prefix-Tuning: Optimizing Continuous Prompts for Generation
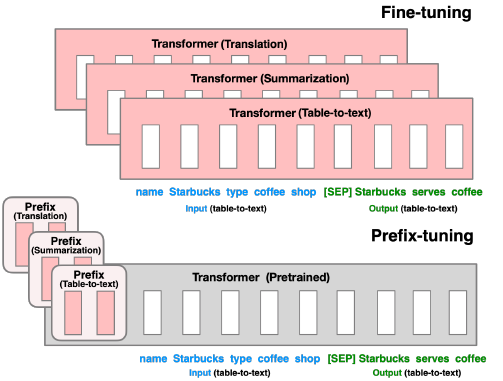
Prefix-Tuning freezes the language model parameter while add a prefix
vector to each layer of the model. These prefix vectors work like
virtual tokens and are regarded as continuous prompts. By
only tuning these vectors, Prefix-Tuning outperforms finetuning in
low-data settings of NLG task.
Prefix-Tuning templates:
Autoregressive Model: [T] x y
Encoder-Decoder Model: [T] x [T'] ywhere x is the source table, y is the target utterance.
Notice that there is a comparison of prompting expressive power, it seems that continuous vector is more expressive than discrete templates:
discrete prompting < embedding-only ablation < prefix-tuning
P-Tuning
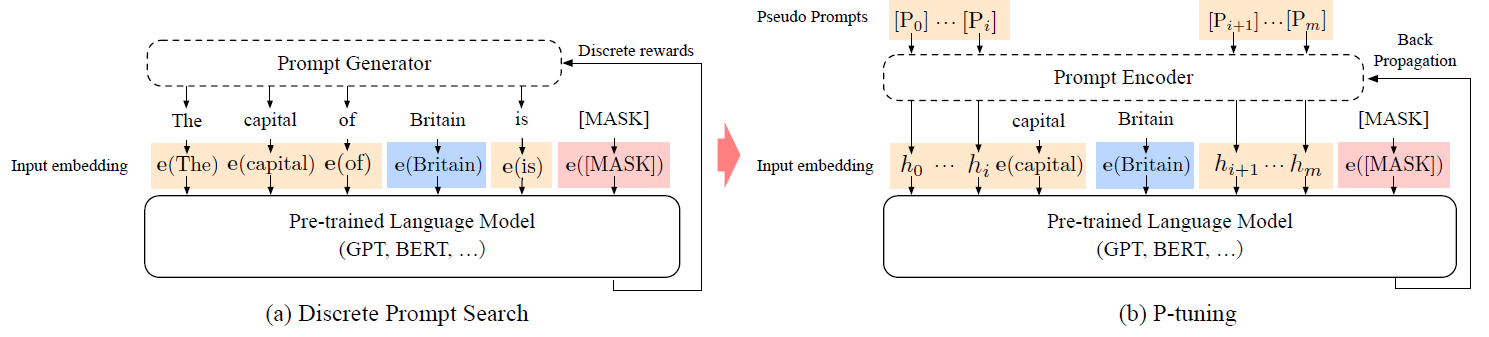
The idea of P-Tuning is quite similar to Prefix-Tuning, both of them try to training continuous prompts by labeled data. The difference is that P-Tuning is mainly focusing on NLU tasks.
To automatically search prompts in the continuous space to bridge the gap between GPTs and NLU applications.
The template of P-Tuning:
[h(0)]...[h(i)]; e(x); [h(i+1)]...[h(m)]; e(y)where h(i) is the prompt, e() is the embedding function, x is input tokens and y is the target.
In practice, both Prefix-Tuning and P-Tuning use reparameterize techniques to solve the unstable optimization problem:
Empirically, directly updating the P parameters leads to unstable optimization and a slight drop in performance.
By: Prefix-Tuning
In the P-tuning we propose to also model the h(i) as a sequence using a prompt encoder consists of a very lite neural network that can solve the discreteness and association problems.
By: P-Tuning
By the way, there were many explanations on why BERT is more suitable for NLU and GPT is more suitable for NLG. Does this paper proves the previous explanations are wrong? :-)
Prompt Tuning
# The Power of Scale for Parameter-Efficient Prompt Tuning
This paper was published at EMNLP 2021. Compared with prefix-tuning which inserts prefix vector to every Transformer layer, Prompt Tuning uses a single prompt representation which is prepended to the embedding input. Therefore, Prompt Tuning is more parameter-efficient. Some interesting observations:
How to Init Prompt?
Conceptually, our soft-prompt modulates the frozen network’s behavior in the same way as text preceding the input, so it follows that a word-like representation might serve as a good initialization spot.
How to Choose Prompt Length?
The short answer: as short as possible. Experiments show that more than 20 tokens only yield marginal gains.
The parameter cost of our method is EP, where E is the token embedding dimension and P is the prompt length. The shorter the prompt, the fewer new parameters must be tuned, so we aim to find a minimal length
that still performs well.
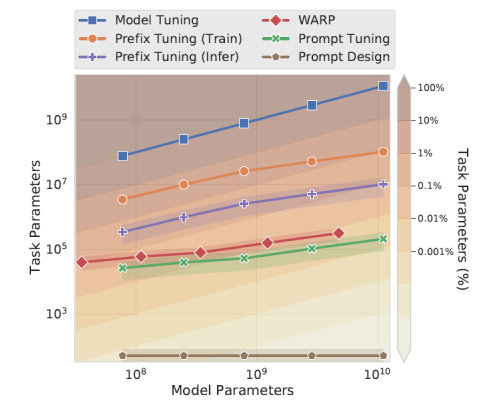
From the above comparison, Prompt Tuning uses less than 0.01% parameters for most model sizes. The most interesting point of this paper is that preprending limited number of parameters to the input layer would be enough.
Summary
Prompting is undoubtedly one of the most popular NLP directions. Through constructing or searching proper templates, prompt learning has created new SOTA for many NLP tasks.
However, prompting still faces many challenges:
Most of the work takes manually-designed prompts—prompt engineering is non-trivial since a small perturbation can significantly affect the model’s performance, and creating a perfect prompt requires both understanding of LMs' inner workings and trial-and-error.
By: # Prompting: Better Ways of Using Language Models for NLP Tasks
In conclusion, prompting is a promising technique to release the power of pretrained language models. Nice to see more excellent work in this area.