NLP中的Adapters是什么?
NLP adapters主要想解决不同任务需要finetune整个模型的痛点,与Prompting一样,是一种轻量级的训练方法,也是Transfer Learning的应用。按出现时间来看,finetune早于adapters,adapters早于prompting。今天来重看这篇Adapters的文章,可以更好地理解lightweight finetune的发展过程。
Adapters在NLP中的应用源于这篇 ICML2019 文章: Parameter-Efficient Transfer Learning for NLP adapters 。
Adapter-based tuning requires training two orders of magnitude fewer parameters to fine-tuning, while attaining similar performance.
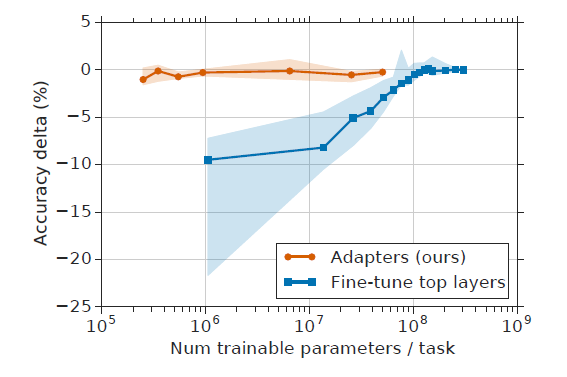
从上图来看,Adapters可以在训练小两个量级参数的情况下达到与finetune基本一致的性能,这也是Adapter出现的主要动机。
Adapter模块结构详解
Adapter的结构并不复杂,仅在Transformer的结构上增加了两个网络层:
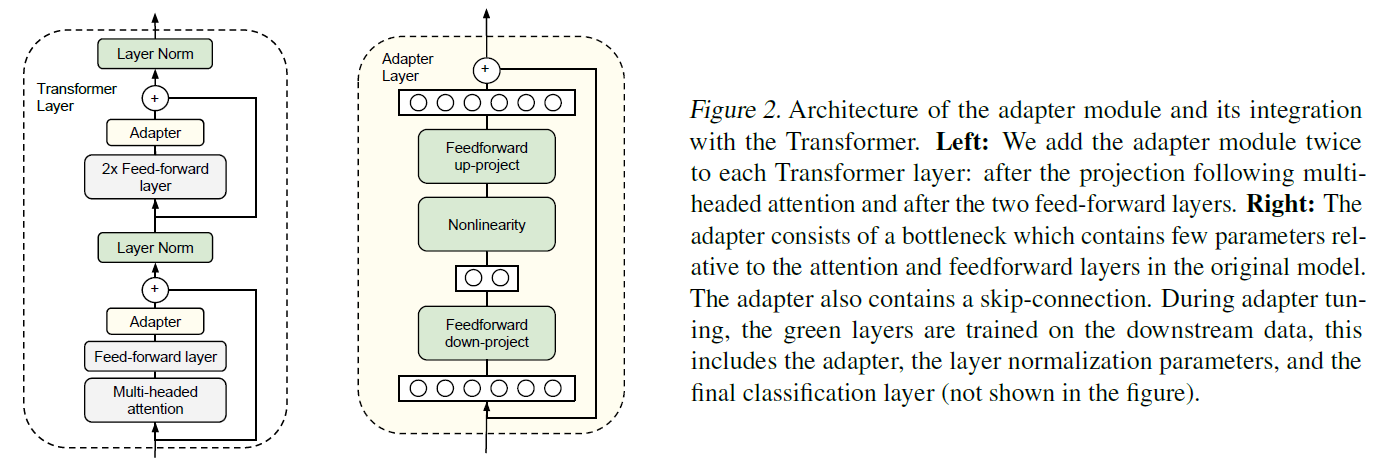
- 左图解释了如何将Adapter加入到Transformer结构中,即在Multi-headed Attention与Feed-forward模块之后,Layer Norm之前各加入一个Adapter层。
- 右图解释了加入的Adapter模块的内部结构:Feed-froward down-project + Nonlinearity + Feed-froward up-project,对进入Layer Norm之前的输入进行了先先降维再升维,保持输入输出相同。
- 图中绿色部分是待训练的参数,可以看到包括了Layer Norm,原因在于加入Adapter结构之后, Layer Norm的输入也发生了很大的变化,所以需要一并训练。
Adapter模块为什么也要引入残差连接?
这里给出了解释:为了保证在模型初始化时的输入输出与原始模型一致。
The adapter module itself has a skip-connection internally. With the skip-connection, if the parameters of the projection layers are initialized to near-zero, the module is initialized to an approximate identity function.
Adapter引入的参数量?
新引入的参数量可以很容易计算,原始输入维度为d,中间降维后的维度为m,则一个Adapter加上偏置后的总参数量:md + d + md + m = 2md + d + m。这里m « d,因此每个任务引入的新参数量很少。实践中,大概只引入原模型参数量的0.5 - 8%。
Adapter为什么设计成这样?
文章中没有给出详细的说明,从实验部分来看,作者做了大量实验来寻找parameter-efficient的模型架构。效果好就完了~
Adapter-Tuning与Prompt-Tuning的区别
Adapter是在Transformer中增加了额外的网络层。对于连续型的Prompt,以Prefix-Tuning为例,是在Transformer的每层增加了额外的prefix vector,利用attention机制来发挥作用。用不太严谨的话来说,Adapter-Tuning像是纵向的参数扩展,而Prefix-tuning像是横向的参数扩展。相对而言,Prompt-Tuning训练的参数量更小。
源引Prefix-Tuning中的一段话:
Recall that prefix-tuning keeps the LM intact and uses the prefix and the pretrained attention blocks to affect the subsequent activations; adapter-tuning inserts trainable modules between LM layers, which directly add residual vectors to the activations.