Chain-of-Thought Prompting 简读
语言模型越来越大,但更大的模型并没有显示出更强的计算和推理能力。去年Google提出了Chain-of-Thought (CoT) 的方案,通过chain-of-thought提示,让模型逐步推断,使大模型的推理能力显著提升。本文来看一下chain-of-thought的原理。
Chain-of-Thought Prompting Elicits Reasoning in Large Language Models
Language Models Perform Reasoning via Chain of Thought
chain-of-thought主要被前续工作的两个想法启发:
- 通过生成自然语言的中间推理过程,可以提升算术推理能力
- 大模型可以通过小样本提示示例学习
因此,chain-of-thought做的事情就是通过少量例子“提示”模型如何逐步完成推理任务,prompt的输入为三元组<input, chain of thought, output>,其中chain of thought是可得到最终结果的一系列自然语言中间步骤。示例如下:
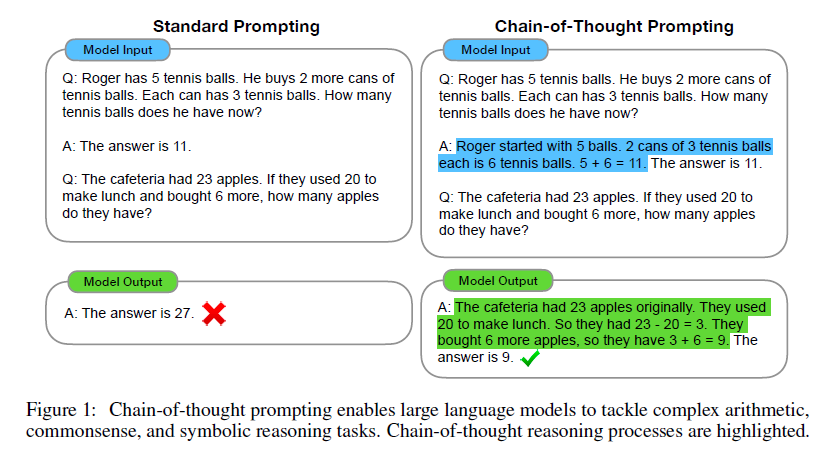
可见,通过向模型提供一些思维过程示例,模型也会试图像示例一样一步步进行推理并得到最终结果。作者们手动构建了一个示例集,共8个进行逐步推演计算的例子:

然后对GMS8K这个数字问题数据集进行测试,发现chain-of-thought显著提升了大模型解决算术问题的能力:
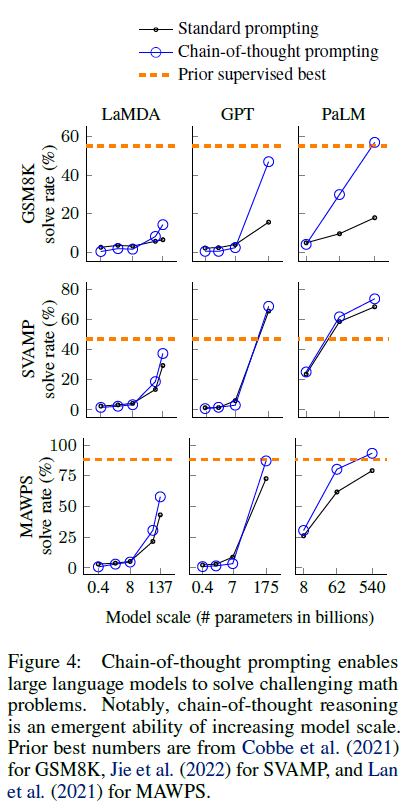
从上图可见一个有意思的现象:chain-of-thought对小模型无效甚至有负作用,而只对100B规模以上的模型有显著性能提升。
Chain-of-thought prompting does not positively impact performance for small models, and only yields performance gains when used with models of ~100B parameters.
此外,chain-of-thought对相对复杂的问题有更多的性能提升。对于更大的模型如 GPT-3 (175B) 和 PaLM (540B), 这种方式甚至达到了新的SOTA。
为验证chain-of-thought的普适性,作者们还做了常识推理和符号推理的实验,结果都证实了这种方式的有效性,不再赘述。下图展示了用于算术、常识推理和符号推理中使用的三元组示例:

为什么chain-of-thought有效?这是个很有趣的问题。虽然它模拟了人类思考的过程,但神经网络到底是不是真的会“推理”,作者们认为还是一个开放式问题。chain-of-thought的想法很简单也很符合直觉,笔者认为语言模型在达到一定规模和数据的训练后,出现所谓“涌现”现象并不意外,所谓量变引起质变,在大规模语言模型的情境下,很有可能出现弱智能的现象,比如拥有了简单的推理能力。
不过chain-of-thought还是有不少局限性,比如它只在100B以上的大模型中才有显著作用,考虑到成本和延迟问题,目前直接应用在业务中依然受限。