Nucleus Sampling与文本生成中的不同解码策略比较
# The Curious Case of Neural Text Degeneration
这篇ICLR 2020年的文章我很喜欢,因为它简洁直观。文章首先提出一个有意思的发现:人说的自然语言常常出人意料,即说出的并不总是语言模型中概率最大的词,而Beam Search会总会选择最符合语言模型的词汇,因此生成的文本没有新意(less surprising)。之后提出了一种top-k sampling的改进方案来解决问题:nucleus sampling (top-p sampling)。
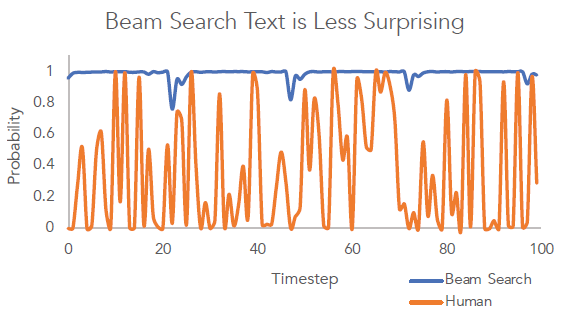
这张图很好地说明了Beam Search与真人说话之间的区别,Beam Search生成的句子虽然可以令其的概率最大,但用词总是比较普通,可人的语言往往不是令语言模型概率最大化的那个词,每个词出现的概率更有节奏。
Top-k Sampling
解决这个问题最简单的方案就是引入Sampling,既然Beam Search每次会选择在Beam中最大概率的词汇,那我们是否可以有一定机率不选最大概率的词就能达到用词出人意料的效果呢?这就是top-k sampling:在解码的每个时间步从前k个概率最大的词中按它们的概率进行采样。
但top-k sampling中k的选择是个难题,选大了可能会采样出长尾词,导致语句不通顺,选小了又退化成了Beam Search。
Nucleus Sampling (Top-p Sampling)
为解决这个问题,Nucleus sampling应运而生:
The key intuition of Nucleus Sampling is that the vast majority of probability mass at each time step is concentrated in the nucleus, a small subset of the vocabulary that tends to range between one and a thousand candidates.
在每个时间步,解码词的概率分布满足80/20原则或者说长尾分布(个人解读),头部的几个词的出现概率已经占据了绝大部分概率空间,把这部分核心词叫做nucleus。
其实Nucleus Sampling这个名字起得有点唬人,叫Core Sampling可能更直观些 (但不fancy) :-)。
基于这样的观察,提出nucleus sampling:给定一个概率阈值p,从解码词候选集中选择一个最小集$V_p$,使得它们出现的概率和大于等于p。然后再对$Vp$做一次re-scaling,本时间步仅从Vp集合中解码。
$$\sum_{x \in V_p}P(x|x_{1:i-1}) \ge p$$
这样的好处在于在不同时间步,随着解码词的概率分布不同,候选词集合的大小会动态变化,不像top-k sampling是一个固定的窗口大小。由于解码词还是从头部候选集中筛选,这样的动态调整可以使生成的句子在满足多样性的同时又保持通顺。
Temperature Sampling
Temperature Sampling看名字就更摸不着头脑,实际上思路非常简单,就是直接re-scale原有的解码词分布:
$$p(x=u_l|x_{1:i-1})=\frac{exp(u_l/t)}{\sum_{i \in V_l}exp(u_i/t)}$$
其中t是一个超参数,取值范围[0,1),t的取值不同,解码词的概率分布也就更平缓或更两极分化。一定程度上也能通过设置不同的t达到与top-k sampling一样的效果。
Summary
论文先指出Beam Search在做文本生成解码时退化问题,然后提出nucleus sampling的方案来让生成的文本更多样化。
本质上,无论top-k/top-p还是temprature sampling都是在优化解码词概率分布,通过re-scaling,尽量让生成的句子多样性更好,同时不损失通顺度。但无论哪种方式,都引入了一个新的超参数 (k/p/t),还需要进一步的启发式选择。