ChatGPT一周年:开源大模型迎头赶上?
一篇有趣的综述文章,写于ChatGPT问世一周年之时,总结了开源大型语言模型(LLM)在过去一年中的发展情况。首先介绍了开源LLM的兴起,以及它们如何在各种自然语言处理任务中取得了显著的进展。然后讨论了开源LLM与闭源LLM之间的竞争,以及它们在性能和应用方面的差异。文中提到了一些具体的研究成果和进展,包括知识获取、情感分析、代码生成等。最后,论文探讨了开源LLM的未来发展方向,以及在伦理和安全方面的挑战和应对措施。
# ChatGPT’s One-year Anniversary: Are Open-Source Large Language Models Catching up?
简介
2022年11月,OpenAI发布了ChatGPT,这一事件在AI社区甚至全世界引起了轰动。首次,一个基于应用的AI聊天机器人能够提供有帮助、安全和有用的答案,遵循人类指令,甚至承认并纠正之前的错误。作为第一个这样的应用,ChatGPT在其推出仅两个月内,用户数量就达到了1亿,远远快于其他流行应用如TikTok或YouTube。因此,它也吸引了巨额的商业投资,因为它有望降低劳动成本,自动化工作流程,甚至为客户带来新的体验。
但ChatGPT的闭源特性可能引发诸多问题。首先,由于不了解内部细节,比如预训练和微调过程,很难正确评估其潜在风险,尤其是考虑到大模型可能生成有害、不道德和虚假的内容。其次,有报道称ChatGPT的性能随时间变化,妨碍了可重复的结果。第三,ChatGPT经历了多次故障,仅在2023年11月就发生了两次重大故障,期间无法访问ChatGPT网站及其API。最后,采用ChatGPT的企业可能会关注API调用的高成本、服务中断、数据所有权和隐私问题,以及其他不可预测的事件,比如最近有关CEO Sam Altman被解雇并最终回归的董事会闹剧。
此时,开源大模型应运而生,社区一直在积极推动将高性能的大模型保持开源。然而,截至2023年末,大家还普遍认为类似Llama-2或Falcon这样的开源大模型在性能上落后于它们的闭源模型,如OpenAI的GPT3.5(ChatGPT)和GPT-4,Anthropic的Claude2或Google的Bard3,其中GPT-4通常被认为是最出色的。然而,令人鼓舞的是差距正在变得越来越小,开源大模型正在迅速赶上。
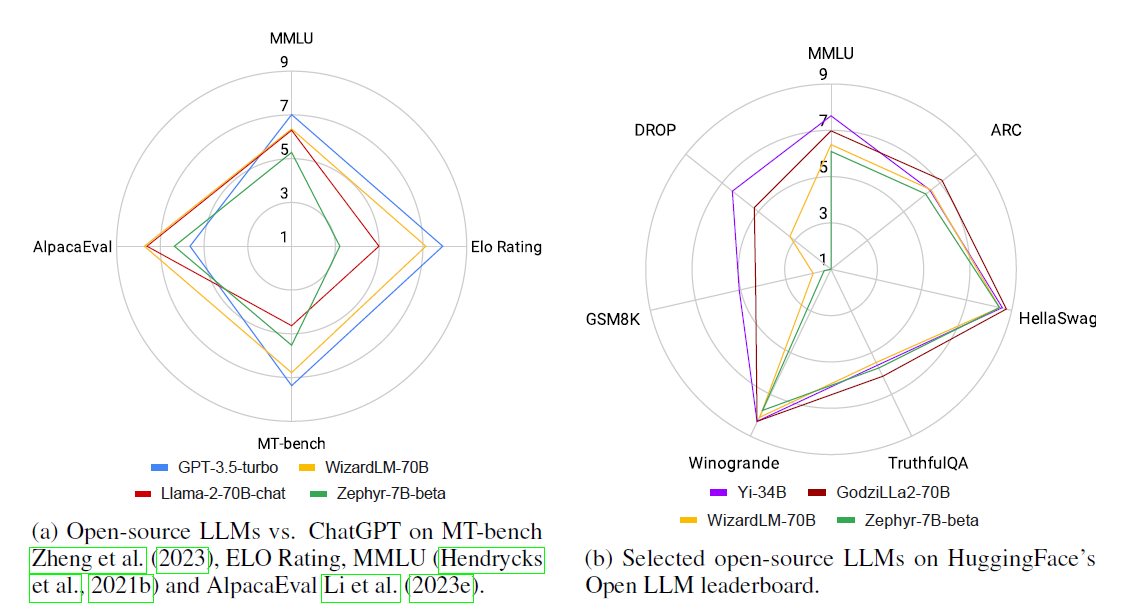
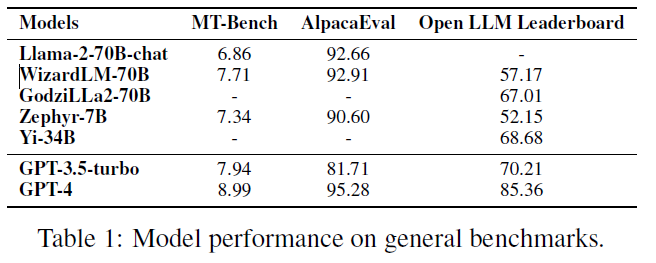
实际上,如图所示,最好的开源大模型在一些标准基准测试上已经优于GPT-3.5-turbo。然而,对于开源大模型来说,并不是一劳永逸的:闭源模型定期通过对新数据进行重新训练而进行更新,开源大模型也在不断发布新版本,同时有大量的评估数据集和基准用于评估大模型性能,找出最佳大模型是件有挑战的事情。
开源大模型 vs ChatGPT
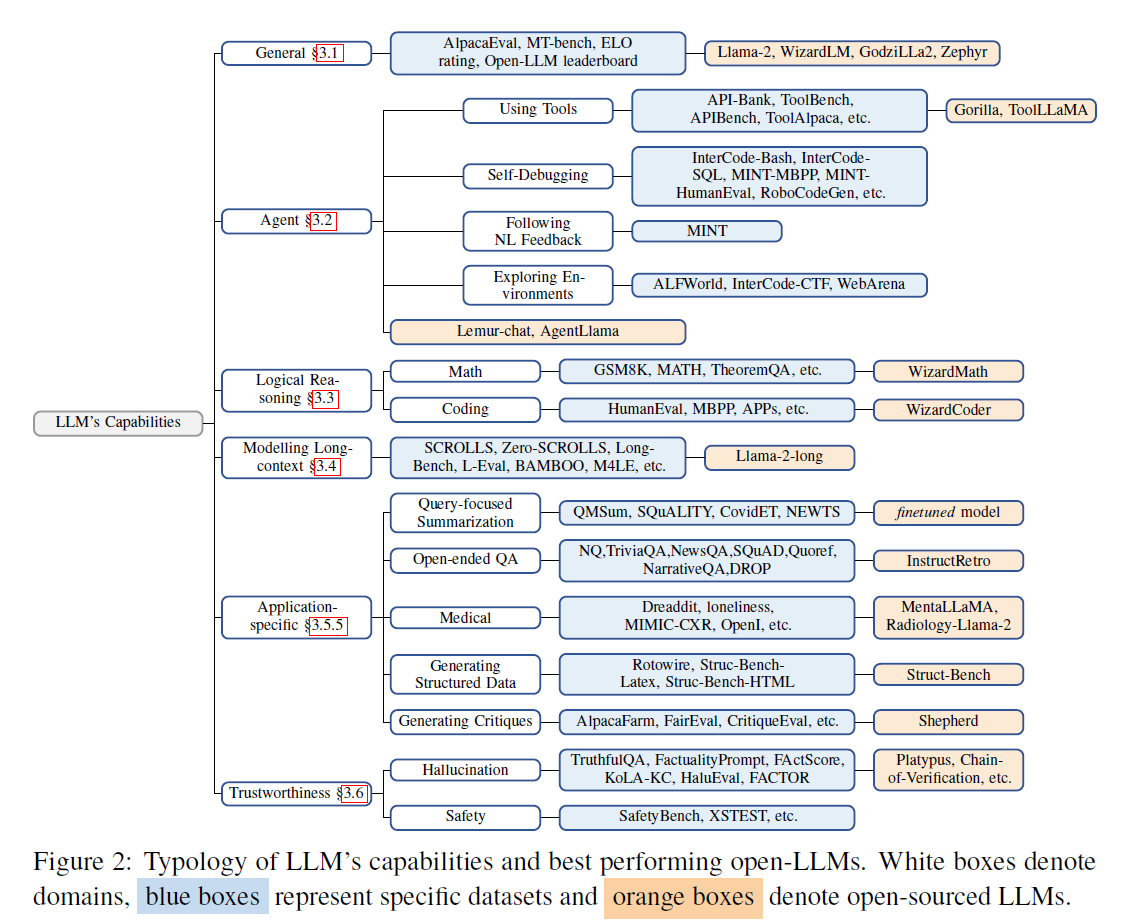
通用能力
随着无数大模型每周发布,都声称在某些任务上表现更优越,要识别真正领先的模型变得愈发具有挑战性。因此,全面评估这些模型的性能至关重要。
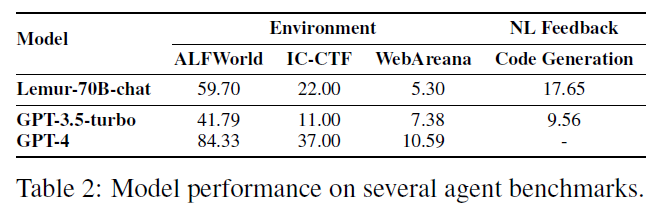
Agent能力
随着模型规模不断扩大,Agent能力成为大模型的重要能力之一。目前,根据所需的技能,现有的基准测试主要可分为四类:
- 使用工具:一些基准测试旨在评估LLMs的工具使用能力。
- 自我调试:用于评估大模型进行自我调试的能力。
- 自然语言反馈:用于测量大模型利用自然语言反馈的能力,通过GPT-4模拟人类用户。
- 探索环境:评估基于大模型的代理是否能够从环境中收集信息并做出决策。
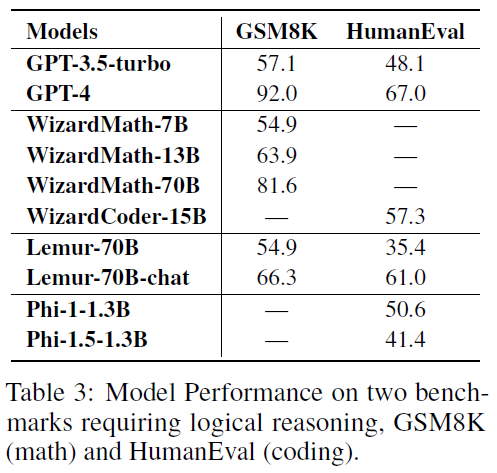
逻辑推理能力
问题解决和逻辑推理是高层次能力的体现,如编程、定理证明以及算术推理。
长上下文能力
长序列处理仍是大模型的关键技术瓶颈之一,因为所有模型都受到有限的最大上下文窗口的限制,通常长度为2k到8k个词元。
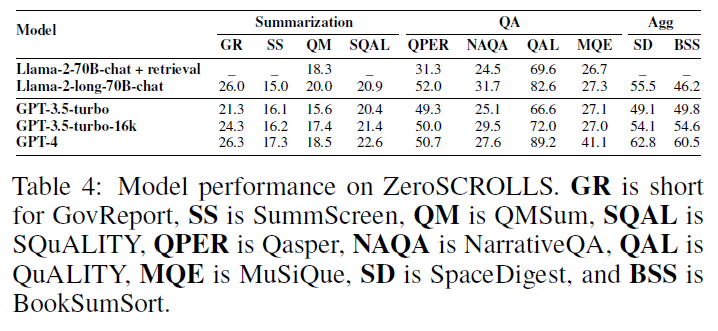
可信能力
模型生成回复的可信性直接影响它们的可用性,需要评估模型hallucination的程度。

大模型的发展趋势
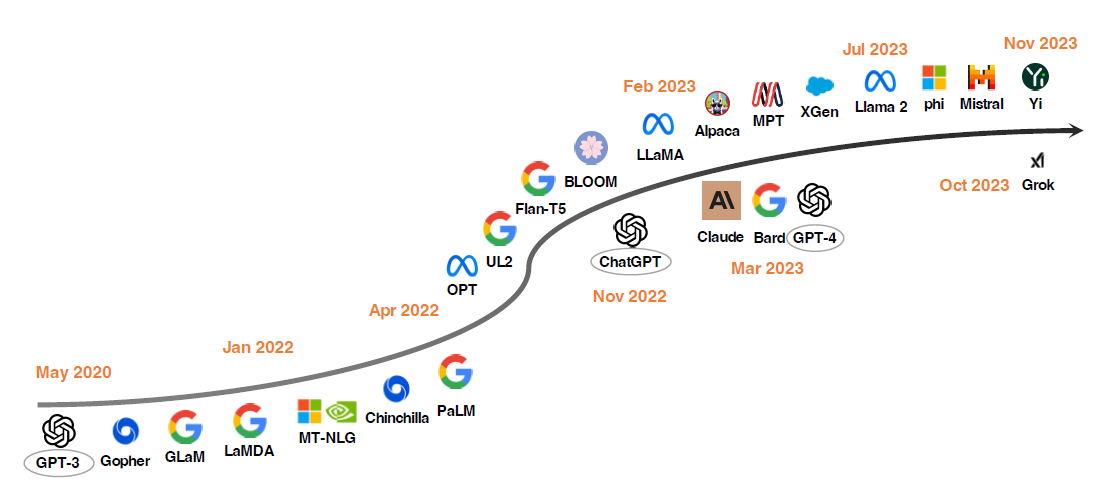
自2020年GPT-3展示了它的零样本能力之后,大模型研究取得显著的进展。一个方向集中在扩大模型参数,包括Gopher,GLaM,LaMDA,MT-NLG和PaLM,最终参数达到了540B。尽管它们能力突出,但由于其闭源性质,限制了它们的广泛应用,因此引起了对开源大模型发展的日益关注。另一个研究方向通过探索更好的策略,预训练较小的模型,如Chinchilla和UL2。
一年前OpenAI的ChatGPT的出现极大改变了NLP社区的研究方向。为了迎头赶上OpenAI,Google和Anthropic分别推出了Bard和Claude。虽然它们在许多任务上显示出与ChatGPT差不多的性能,但它们与最新的OpenAI模型GPT-4之间仍存在性能差距。由于这些模型的成功主要归因于从人类反馈中进行的强化学习(RLHF),研究者已经探索了各种改进RLHF的方法。
为了推动开源大模型研究,Meta发布了Llama系列模型。从那时起,基于Llama的开源模型开始大量涌现。一个代表性的研究方向是使用指令数据对Llama进行微调。例如,Alpaca是从LLaMA微调而来,使用OpenAI的text-davinci-003生成的52K个指令进行微调。Vicuna是一个从LLaMA微调而来的开源聊天机器人,使用从ShareGPT收集的70K用户共享的对话进行微调。Lima演示了仅使用少量精心注释的指令样本就足以充分展示LLMs的潜在能力。通过利用Evol-Instruct使用LLMs生成大量具有多样性的指令数据,WizardLM达到了与ChatGPT相当的性能。
还有一些研究探索了改进基于Llama的开源大模型Agent、逻辑推理和长文本建模能力。此外,还有许多致力于从头开始训练强大的大模型,包括通用大模型(例如MPT,Falcon,XGen,Phi,Baichuan,Mistral,Grok和Yi)和领域特定的大模型(例如,Bloomberggpt,FinGPT和InstructRetro)。因此,研发更强大和高效的开源大模型以使闭源大模型的能力普及应是一个有前途的方向。