ETA 2824-2 机芯保养手册
ETA 2824-2 是经典的瑞士机芯之一,稳定、准确度高。网上也有一个很好的拆解点油视频:
不过关于2824机芯的手册百度很难搜到免费下载,在此与表友共享。
ETA 2824-2 是经典的瑞士机芯之一,稳定、准确度高。网上也有一个很好的拆解点油视频:
不过关于2824机芯的手册百度很难搜到免费下载,在此与表友共享。
DeepMind去年在 NeurIPS 2022 发表了一篇如何在给定计算资源条件下,用多少tokens训练最优大小的 Large Language Models (LLM)。之前的许多工作都仅专注于扩大模型规模,而并不增加训练数据规模,导致这些模型显著地训练不到位 (undertrained)。DeepMind训练用不同规模的数据 (从5B到500B tokens) 训练超过400个不同大小的模型 (从70M到超过16B),发现 模型和训练数据规模需要同比增大。根据这个假设,使用与 Gopher (280B) 同样的计算量且4倍的数据,训练了70B的最优模型 Chinchilla。它在许多下游任务上的性能显著超过了 Gopher (280B), GPT-3 (175B) Jurassic-1 (178B) 和 Megatron-Turing NLG (530B)。
[NeurIPS 2022] Training Compute-Optimal Large Language Models Training Compute-Optimal Large Language Models
本文的 Chinchilla 也是后续对话系统 Sparrow 的基模型。
最近微软投资ChatGPT的消息甚嚣尘上,二者的联手会给产业和用户带来什么?
# Microsoft in talks to invest $10 bln in ChatGPT-owner OpenAI
从新闻上来看,微软会将ChatGPT集成到Office和Bing Search。但实际情况可能不止于此,微软擅长做平台,CVP已经在Azure Blog称ChatGPT将不久在Azure OpenAI Service上可用:
Customers will also be able to access ChatGPT—a fine-tuned version of GPT-3.5 that has been trained and runs inference on Azure AI infrastructure—through Azure OpenAI Service soon.
好消息是这个服务可以直接让中小企业基于API研发产品而无须自行研发模型。坏消息是它的效果太好以至于自己训练的模型不能达到同水平的效果,形成对此底层服务的强依赖。
How to make your local repository always sync with GitHub repository? The answer is webhook.
When the repo received a push event, GitHub will send a
POST request to the webhook URL with details of any
subscribed events. What we need to do is to implement a webhook (on
local side) which performs git pull to keep sync with
remote.
2022年随着ChatGPT的大火而结束,最近一年的时间各巨头相继推出了许多表现出色的对话系统,有意思的是大家前进的方向不谋而合,不再专注模型结构和规模,而转向实用性:如何让一个对话系统更有用、更安全、更理解用户意图?
对话系统在过去一年里的主要提升得益如下三点:
Meta AI在2022年8月发布了新一代的对话系统 BlenderBot 3,希望通过这样一个公开的demo收集更多的真实数据来改进对话系统,使它变得更安全、更有用。
BlenderBot 3: a deployed conversational agent that continually learns to responsibly engage
BlenderBot 3 (BB3) 只对在美国的成人开放,只用英文对话:
We present BlenderBot 3 (BB3), an open-domain dialogue model that we have deployed as an English speaking conversational agent on a public website accessible by adults in the United States.
此研究的主要目的与Sparrow最接近,使对话更responsible & useful:
The goal of this research program is then to explore how to construct models that continue to improve from such interactions both in terms of becoming more responsible and more useful.
这个tech report包括了BB3部署的细节,包括UI设计,本文主要关注模型部分。
Sparrow是DeepMind在今年9月底发布的对话系统,主打的点在"helpful, correct, and harmless"。总体来看,思路也是"alignment",即让对话机器人的回复与用户的意图更贴合。在技术路线上,也是采用reinforcement learning from human feedback,通过定义一批规则,让模型更好地向期望的对话方向推进; 此外,对于事实型的问题,参考搜索出的内容给出回复。
Building safer dialogue agents
Improving alignment of dialogue agents via targeted human judgements
ChatGPT火爆全网,要是能接到自己的微信公众号后台,岂不美哉?
想必有此想法的同志不止我一人,上周末就研究了一下,有几个问题需要解决。
首先就是ChatGPT API,最关键的问题没有之一,OpenAI并没有官方API支持。不过github上早有人反向工程破解了此API,Python实现:
WebGPT是OpenAI在2021年底发布的解决long-form quesion-answering (LFQA) 的方案。比InstructGPT的提出稍早一些。
WebGPT: Improving the Factual Accuracy of Language Models through Web Browsing
WebGPT: Browser-assisted question-answering with human feedback
WebGPT想解决什么问题?让开放域QA回复更长更可靠。
A rising challenge in NLP is long-form question-answering (LFQA), in which a paragraph-length answer is generated in response to an open-ended question. LFQA systems have the potential to become one of the main ways people learn about the world, but currently lag behind human performance.
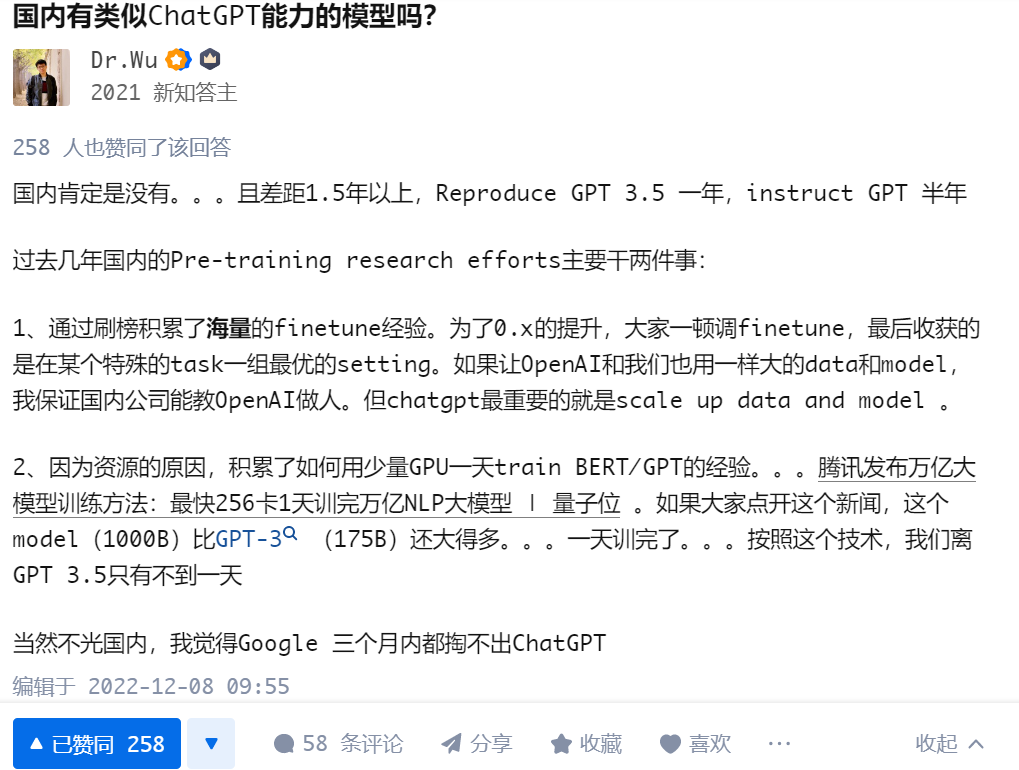
整个圈子最近都被ChatGPT出色的对话和Coding能力惊艳到了,前面写了篇文章简析了下其原理,虽然看起来直观,但国内的对话水平与其差距确非一日之功。下面的知乎回答深以为然:
ChatGPT: Optimizing Language Models for Dialogue
既然大家都致力于发掘ChatGPT厉害的地方,就来找找它的不足吧。