段落和列表中间添加空行的脚本
升级Hexo到v8.5.0之后,发现mathjax不能正确显示公式。看了下文档,发现推荐的hexo
renderer是hexo-renderer-pandoc,而目前使用的是hexo-renderer-kramed,而且这个包已经不再更新也不推荐使用了。
那就换用hexo-renderer-pandoc,虽然公式能正常渲染,但又有新的问题,一是内嵌html不能正确识别,另一个是引用和列表展示不换行。
升级Hexo到v8.5.0之后,发现mathjax不能正确显示公式。看了下文档,发现推荐的hexo
renderer是hexo-renderer-pandoc,而目前使用的是hexo-renderer-kramed,而且这个包已经不再更新也不推荐使用了。
那就换用hexo-renderer-pandoc,虽然公式能正常渲染,但又有新的问题,一是内嵌html不能正确识别,另一个是引用和列表展示不换行。
卜算子自嘲 丁元英
本是后山人, 偶做前堂客。 醉舞经阁半卷书, 坐井说天阔。
大志戏功名, 海斗量福祸。 论到囊中羞涩时, 怒指乾坤错。
Recently I found that the Google auto ads significantly slows down the page loading speed. There are also many discussions about this. As a static website, fast loading speed is crutial. In this post, we will optimize the PageSpeed Insights score by delay loading auto ads.
# 提升Hexo NexT主题加载速度 中留了个尾巴,优化到最后发现最影响PageSpeed Insights得分的竟然是Google Auto Ads。 这里 有个有意思的讨论,说加上auto ads之后页面加载得分显著变低,采纳答案说“你啥也做不了,也不用care”,下面有人反对这个观点,加载速度评测认为网站慢就会导致搜索排序降低。我赞成后者的观点,风一样的加载速度即我所欲也,本来无一物,何处惹尘埃!
网站加载速度是影响搜索引擎排名的一个重要因素。# Google Page Speed Insight 是个很好的网页性能分析工具,可以根据它的分析结果有针对性地对网页进行优化。
用这个工具分析了自己的站吓一跳,原来它在Mobile的性能如此之差,只有27分!Desktop的性能尚可,86分。
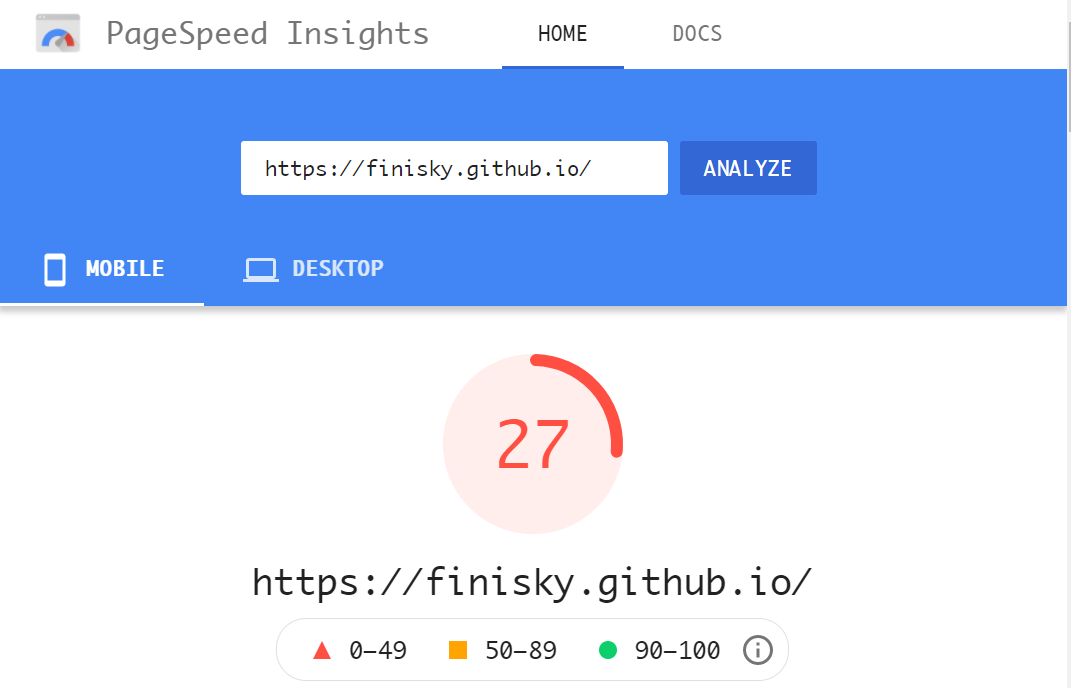
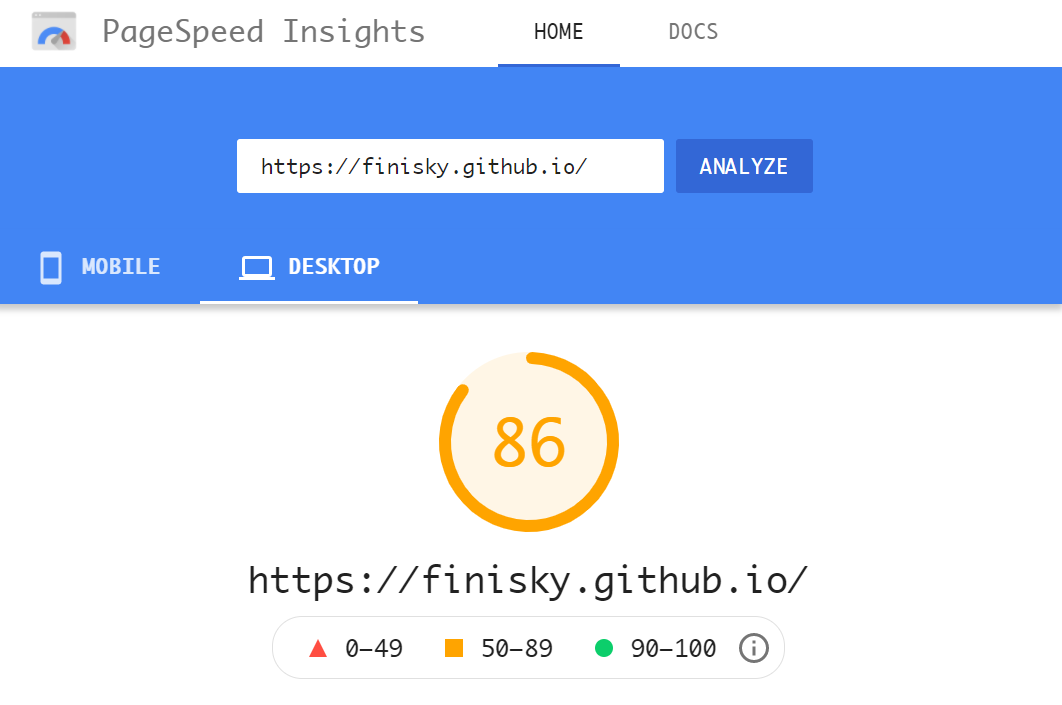
之前看一些博客发现,有些页面风格极为简约,虽然没有很fancy的动效,但看起来很舒服,欣赏这种低调的奢华。道理很简单,文章的内容才是根本,页面做得再炫,也不能提升SEO效果,最好的SEO是优质的内容。后面发现动效反倒会拖慢页面加载速度,对SEO起到负面作用。
考虑到这些,那就可以操刀了,其实一个简单的HTML加上评论系统足够。就风格而言,最喜欢的是类似电子书质感的主题,但暂时没找到对应的模板。
说起牛肉面,第一反应可能是“兰州拉面”。可兰州人民已经澄清了这个概念:兰州没有拉面,只有牛肉面。去甘肃旅游时也吃过正宗的兰州牛肉面,确实不错。帝都的兰州拉面馆不少,个人觉得马华的还原度就挺高。
最近刷抖音看到北京两家很火的牛肉面馆,宇飞牛肉面和柴氏风味斋,便想找机会一试。这两家牛肉面与兰州牛肉面不同,简而言之,兰州牛肉面是清汤牛肉片面,北京牛肉面则是红汤牛肉块面。(这种清汤红汤的分类方法让我想起了苏州同德兴的白汤面和红汤面)
偶然发现宇飞在家附近就有家分店,只是从未注意到这家小馆。柴氏没有分号,只能去甘家口品尝了。
最近折腾博客比较多,也看了不少使用Hexo博主所用的评论系统,觉得Valine不错,NexT也天然支持(配置也就简单)。正想切换时发现它存在安全性问题,于是就调研了一下可用的评论系统,简单总结:
我对评论系统的需求:
这几条限制加上之后,可选项也就不多了,最终选择了Waline。本文所用版本:Hexo v5.4.0,NexT v8.5.0。
希望在Hexo的NexT主题中增加自定义分类的菜单,即一个指向特定分类的链接,且页面显示的是类似主页的标题+摘要风格。
之前有一个比较粗暴的实现:# Hexo添加自定义分类菜单项并定制页面布局。由于直接修改了源码,属于侵入式实现,导致以后升级Hexo和主题时需要手动再改代码,不推荐。
本文采用Hexo扩展简洁地定制新的分类页面布局,并解决了之前实现在升级插件或主题后需要修改源码的问题。所用版本:Hexo v5.4.0,NexT v8.5.0。
Blogroll is natively supported in NexT theme. All links will be shown in the sidebar. However, as your links increases, the sidebar length increases as well. It makes the page lengthy and distracting. Therefore, we consider creating a dedicated blogroll page.
After searching, most of the existing approaches need to modify NexT source code (theme swig template files). The implementation is a little bit complicated while breaks the theme's integrity. When you update the theme later, you will need to manually merge or rebase the master to your code.
Actually, there is a straightforward solution. Consider that we can embed html to markdown, creating a new post with customized css/html would be enough. :-)
Hexo的NexT主题可以天然支持友链,即在NexT主题的配置文件_config.yml中有一个# Blog rolls块,可以添加友链,然后在左边栏的底端会显示它们。但这样的问题在于边栏的空间有限,友链比较多的话会影响布局,而且分散主题。于是考虑单独创建一个友链页面,搜索发现已经有成型的方案,大体思路与
#
Hexo添加自定义分类菜单项并定制页面布局
一样,增加菜单项和友链模版,再修改主页模板。这样做可以解决问题,但是不够优雅,属于侵入式的定制(直接修改了主题文件模板),但绝大多数人都采用了这种方案
:-)。
有没有更简单的方案呢?有!考虑到markdown天然支持内嵌html,我们要做的只是用html写一篇新博客。