小模型的惊人能力: Phi-2
过去半年,MSR发布了一套名为Phi的小模型(SLMs),取得了卓越的性能表现。其中第一个模型,1.3B
的Phi-1,实现了在现有SLMs中对Python编码的最佳性能(在HumanEval和MBPP数据集上)。随后,他们将注意力扩展到常识推理和语言理解,并创建了一个新的
1.3B
模型,命名为Phi-1.5,其性能相当于规模更大5倍的模型。
最近MSR发布了Phi-2,一个 2.7B
的语言模型,展示了卓越的推理和语言理解能力,表现出小于 13B
语言模型的最好效果。在各种测试中,Phi-2与规模大达25倍的模型差不多或获胜,主要归功于模型规模和训练数据方面的创新。MSR已经在Azure
AI Studio模型目录中提供了Phi-2,以促进语言模型的研究和开发。
Phi-2 未放出细节的技术报告,具体可参考原博客:
# Phi-2: The surprising power of small language models
第一代Phi-1解读:数据为王: Textbooks Are All
You Need
Phi-2的关键点
大模型的出现重新定义了自然语言处理的格局。那么问题来了:是否可以通过巧妙的训练,例如数据筛选,让小模型也拥有大模型的这些能力?
为回答此问题,MSR提出了一系列Phi模型。这些工作在打破传统语言模型扩展法则(scaling
law)方面的关键点主要有两点:
- 数据质量在模型性能中起着至关重要的作用。虽然这一观点几十年来一直存在,但通过专注于“教科书质量”的数据,深化了这一认识,延续了之前的工作“Textbooks Are All You Need”。混合的训练数据包含了专门用于教授模型常识推理和通识知识的合成数据集,包括科学、日常活动等方面。此外,还使用精心挑选的Web数据扩展了训练语料库,根据教育价值和内容质量进行了过滤。
- 采用创新技术扩展模型大小,从1.3B的模型开始,并将其知识嵌入到 2.7B
的
Phi-2中。这种扩展知识转移不仅加速了训练,还在基准测试中表现出明显的性能提升。

训练细节
Phi-2也基于Transformer,在人工合成和Web数据集上进行了多轮训练,共
1.4T token。训练共耗时14天,使用了96块A100
GPU。Phi-2是一个基座模型,没有经过RLHF和指令微调。尽管如此,我们观察到在毒性和偏见方面,Phi-2相较于现有开源的对齐模型表现更好。这与Phi-1.5之前的结论一致,主要得益于数据裁剪的方案。

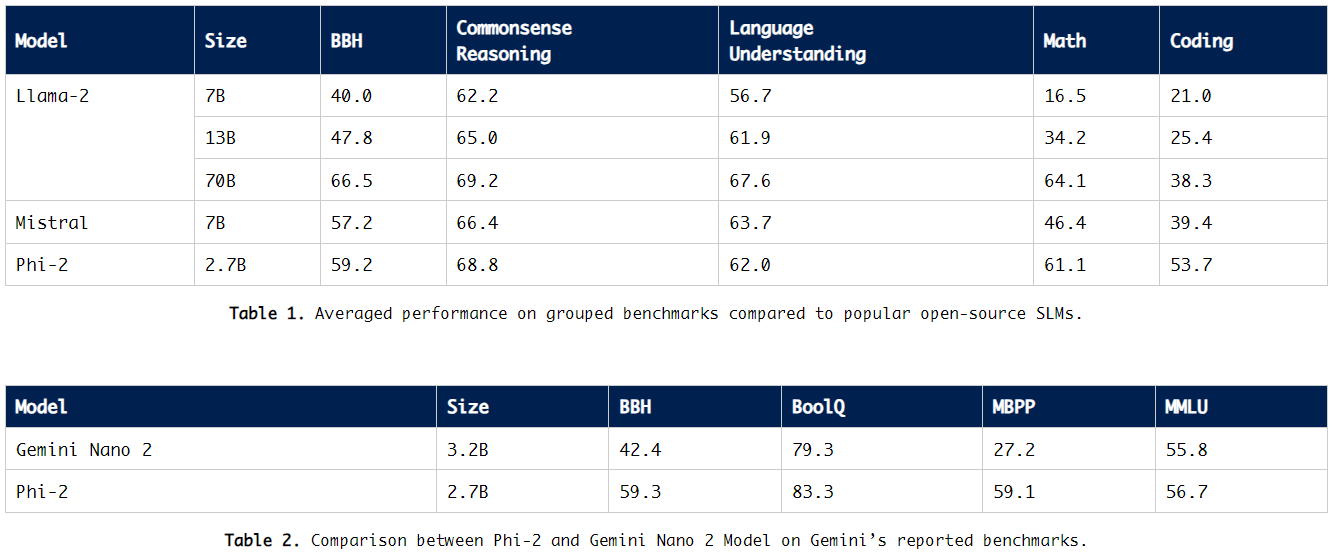
Phi-2评测
2.7B 的 Phi-2在各种综合基准上的性能均超越了 7B 和 13B
参数的Mistral和Llama-2模型。值得注意的是,在多步推理任务中,比如代码和数学能力,Phi-2甚至超过了25倍大的
Llama-2-70B
模型。此外,尽管规模较小,Phi-2在性能上也能与最近发布的Google Gemini Nano 2差不多或更胜一筹。
考虑到公开的测试基准数据可能会泄漏到训练数据中,为了排除此可能性,研究员在Phi-1上进行了详尽的反数据污染实验。最终,研究员认为评估语言模型的最佳方式是在具体用例上进行测试。所以,研究员还使用了几个内部数据集和任务来评估Phi-2,并再次将其与Mistral和Llama-2进行了比较,得出了同样的结论:
平均来看,Phi-2优于Mistral-7B,而Mistral-7B又优于Llama-2模型(7B、13B和70B)。
此外,作者还对学界常用的提示进行了测试,观察到的行为与预期一致。例如,一个用于探测模型解决物理问题能力的提示,最近被用于评估Gemini Ultra模型的性能:


总的来说,Phi-2模型进一步证实了小模型拥有大模型涌现能力的可能性,也说明了高质量数据对于模型能力有着至关重要的作用,对大模型技术的发展有不小的积极作用。