使LLM善假于物: Toolformer
大模型可以仅凭指令或几个示例就能解决各种新任务,但在一些看似简单的算术或搜索任务上却表现欠佳。俗话说得好,人和动物的区别就是人可以更好地使用工具。于是,Meta
AI提出了Toolformer,让LLM善假于物,通过自学使用外部工具。
Toolformer可以决定调用什么API、何时调用它们、传递什么参数及如何将API返回值融合。Toolformer以自监督方式训练,每个API仅需要几个示例。它在各种下游任务中显著提升了零样本性能,而不牺牲其核心语言模型能力。
# Toolformer: Language Models Can Teach Themselves to Use Tools
简介
众所周知,大模型存在一些天然缺陷:无法获取最新事件信息,虚构事实,低资源语言理解能力弱,缺乏精确计算能力,不知道系统时间等。虽然通过扩大模型规模可以一定程度上减少这些问题,但却不能根除。解决这些问题的简单方案就是让LLM可以自行使用工具,之前的方案要么依赖大量的人工标注,要么仅适用于某些特定任务,不够通用。
Toolformer基于in-context learning的方法从零开始生成整个数据集。通过少量人工编写的示例,让语言模型对可能需要API调用的大数据集进行标注。然后,使用自监督损失函数来确定哪些API调用有用。最后,用这些有用的数据对模型微调,下图是Toolformer使用问答系统、计算器、翻译系统和wiki搜索的示例:

方法
为了让LLM可以使用不同的API,需要将每个API的输入输出表示为文本序列。这样可以无缝地将API调用插入任意文本,用特殊标记符来标记调用的开始和结束。
每个API调用表示为一个tuple: \(c=(a_c, i_c)\),其中\(a_c\)是API名字,\(i_c\)是输入。API调用\(c\)的返回值记为\(r\),那么带有返回值和不带返回值的API调用可分别表示为:
\[e(c) = <API> a_c(i_c) </API>\]
\[e(c,r) = <API> a_c(i_c) \rightarrow r</API>\]
其中<API>,</API>,\(\rightarrow\) 为特殊标记符。
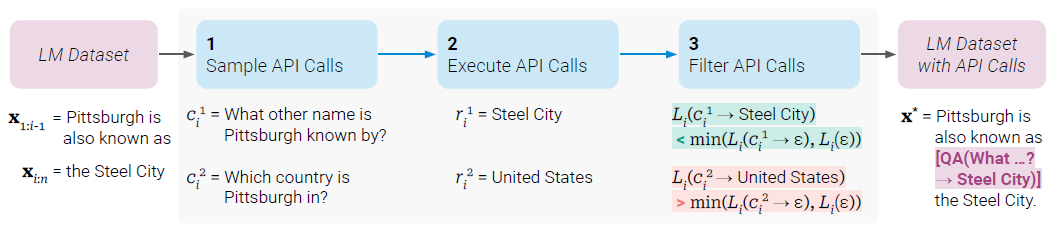
Toolformer构建训练数据集的方式如上图,给定输入文本x,先采样一个位置i和k个API调用的候选\(c_i^1,c_i^2 \ldots
c_i^k\),然后执行这些API调用并过滤,留下加上API调用结果后让语言模型损失更小(生成更好结果)的样本,构成新数据集。下面具体看下这三步操作如何实现。
采样API调用
给定已有语言模型\(M\),对每个API,写一个prompt \(P(x)\) 扩展数据样例\(x=x_1,x_2 \ldots
x_n\),对所有可能的采样位置\(i \in
\{1,2 \ldots n \}\),计算其生成特殊字符 <API>
的语言模型概率(可参考这里):
\[p_i=p_M(<API>|P(x), x_{1:i-1})\]
保留的采样位置集合,语言模型概率需要大于采样阈值\(\tau_s\):\(I=\{ i|p_i > \tau_s \}\),仅保留概率最大的前\(k\)个。此采样方法的目的是筛选出最需要使用API调用的位置。使用的prompt样例:

对每个采样后的位置,用\(P(x), x_1, \ldots
x_n, <API>\) 作为输入前缀,以</API>
作为输出结束符,获取最多\(m\)个API调用结果:\(c_i^1, c_i^2 \ldots
c_i^m\)。若模型未输出结束符</API>则丢弃该样本。
所以经过本步后,会得到不多于\(m\)个API调用。
执行API
没什么好说的,执行上步得到的\(m\)个API调用并得到返回文本序列\(r\)。
过滤API调用
扩展数据集的关键问题:扩展而得的API调用是否必要? 因此,进一步过滤这些生成的API调用就非常关键。这里的过滤标准:与不用API或用了API但不包含其结果相比,是否更有利于语言模型生成之后的文本了?
引入对token \(x_i, \ldots x_n\)按位置计算的加权交叉熵损失,\(z\)是模型输入前缀:
\[L_i(z)=-\sum_{j=i}^n{w_{j-i}} \cdot \log p_M(x_j|z, x_{1:j-1})\]
定义两种情况:
- 不用API: \[L_i^+=L_i(e(c_i,r_i)\]
- 用了API但不包含其结果: \[L_i^-=\min(L_i(\epsilon),L_i(e(c_i,\epsilon))\]
其中\(\epsilon\)表示空序列。过滤条件为:
\[L_i^- - L_i^+ \geq \tau_f\]
即加上API调用与结果后,语言模型的损失至少降低了 \(\tau_f\),留下这样的样本。
微调模型
数据集中的样本由\(x=x_1, \ldots x_n\)变为了\(x=x_{1:i-1},e(c_i,r_i),x_{i:n}\)。使用新数据集微调模型M。重要的一点:新构造的数据集必须包含原始数据集。
推理
微调模型后,在推理阶段,当解码时遇到\(\rightarrow\)时,就中断解码过程,调用API得到结果,加入</API>结束符后再继续解码过程。
工具
限制工具使用的条件:1. 它的输入和输出都可以表示为文本序列 2. 可以写出一些示例。Toolformer使用了以下五个工具:问答系统,维基百科搜索引擎,计算器,日历和机器翻译系统。
结果
实验思路是在多个下游任务上查看Toolformer在零样本条件下是否有性能提升,同时也要确保语言模型本身的能力没有损失。
论文用GPT-J模型进行实验,数据集选择了CCNet的子集。
使用贪心解码策略进行解码,但加入了些许改动(来增加工具使用的召回率):不仅在<API>是最可能出现的token时执行API,只要它的出现概率是top-k的情况即执行API。同时,每个输入最多调用一次API,避免模型死锁在调用API而不产生输出。
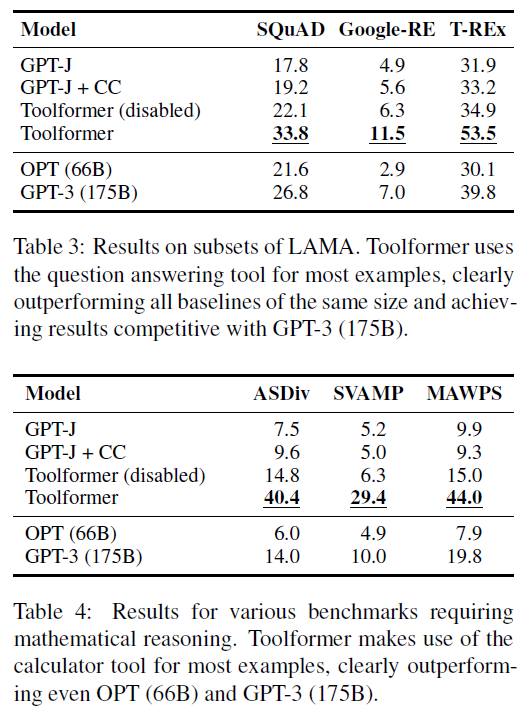
在LAMA数据集上的结果见上图第一表格,所有未使用工具的GPT-J模型性能都相似。Toolformer明显优于这些基准模型,分别比最佳基准模型提高了11.7、5.2和18.6个点。尽管OPT
(66B)和GPT-3
(175B)这两个模型更大,Toolformer也超过了它们。原因在于几乎所有情况下(98.1%),模型都使用了问答工具获取所需信息,只有极少数情况下(0.7%)使用其他工具,或者根本不使用工具(1.2%)。
数学推理数据集上的结果在上图第二表格,GPT-J和GPT-J + CC的表现差不多,但即使禁用API调用,Toolformer的结果也明显更好。作者推测这是因为模型在许多API调用及其结果的示例上进行了微调,提高了其自身的数学能力。尽管如此,允许模型进行API调用可以使所有任务的性能提高一倍以上,并且明显优于更大的OPT和GPT-3模型。这是因为在所有基准测试中,对于97.9%的所有示例,模型都使用了计算器工具。
作者验证了在WikiText数据集和1000个随机采样的CCNet样本上,PPL没有明显下降,说明Toolformer没有损失语言模型的能力。
此外,作者验证了同样的方案在4个更小的GPT-2模型上的效果。发现使用工具的能力只有在模型规模在775M参数以上才涌现。
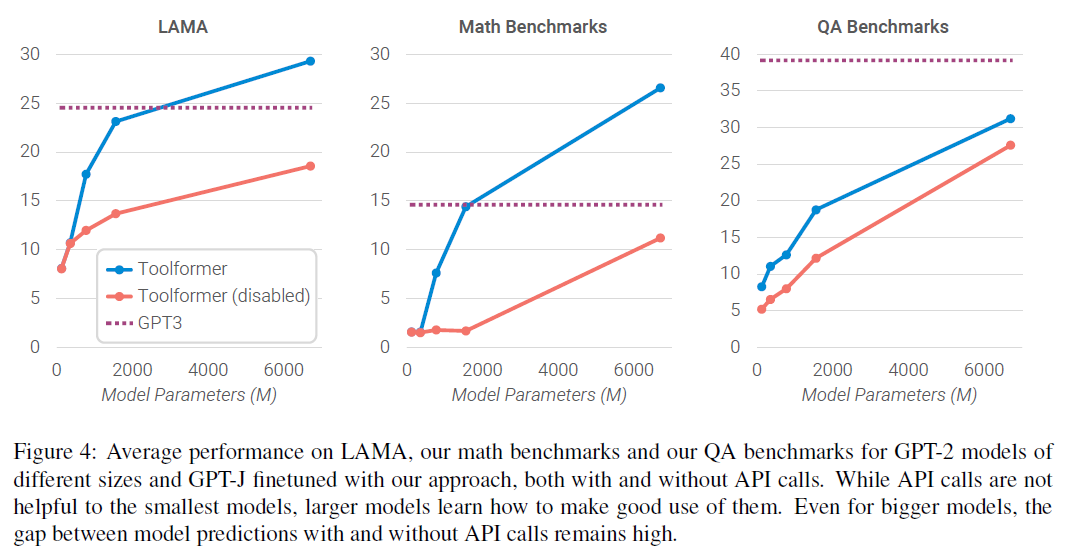
更多实验结果可见原文,不再赘述。
结论
Toolformer的想法符合直觉,尤其是从有利语言模型继续生成的角度出发,进行API调用过滤的思路不错。这种思路本质上有后验指导先验的作用:如果使用工具得到的结果与后续生成的内容一致,则使用工具有效,应该调用API。
Toolformer也还存在一些缺陷,比如:
- 不能使用工具链,因为API调用都是独立生成的
- 不可迭代使用,尤其是像搜索引擎这样返回大量不同结果的工具
- 模型决定是否调用API时,对输入词敏感