Rethinking the Role of Token Retrieval in Multi-Vector Retrieval简读
之前写过深度检索模型的介绍:# 深度文本检索模型:DPR, PolyEncoders, DCBERT, ColBERT,今天来看看DeepMind在NeurIPS 2024上的文章,对多向量检索模型(Multi-Vector Retrieval)ColBERT进行了改进:
Rethinking the Role of Token Retrieval in Multi-Vector Retrieval
多向量检索模型由于使Query与Doc进行词元级别的交互,因此在许多信息检索基准测试中达到了SOTA。然而,其非线性评分函数无法扩展到数百万个文档,这就需要一个三阶段的推理过程:通过词元检索检索初始候选,访问所有词元向量,并对初始候选文档进行评分。非线性评分函数应用于每个候选文档的所有词元向量,使得推理过程复杂且缓慢。XTR 引入了新的目标函数,鼓励模型首先检索最重要的文档词元,对词元检索的改进使得 XTR 可以仅使用检索到的词元来对候选文档排序,而不是文档中的所有词元,因此其成本比 ColBERT 低两到三个数量级。在流行的 BEIR 基准测试中,XTR 在没有任何蒸馏的情况下,将 NDCG@10 提升了 2.8。
主要改进点:
- 仅使用检索到的doc token而非全部doc token进行相似度计算
- 解决了检索训练和推理之间的gap
简介
密集检索模型的关键在于如何定义query和doc的表示,以及它是否能够利用它们进行高效检索和评分。例如,双编码器模型将查询和文档编码为单个向量,并使用点积计算query-doc相似度。虽然这些模型在检索方面非常高效,但由于缺乏基于标记级别的建模进行评分,其表达能力有限。相比之下,多向量模型则直接设计用于捕捉token级别的交互。通过非线性评分函数对所有查询和文档标记表示进行操作,多向量模型享有更好的模型表达能力,并且通常在各种基准测试中取得更好的结果。
然而,增强的模型表达能力却带来了巨大的推理复杂性。与双编码器不同,多向量检索模型中的非线性评分函数禁止使用高效的最大内积搜索(MIPS)来查找评分最高的文档。因此,诸如ColBERT之类的模型采用了复杂且资源密集的推理流程,通常包括三个阶段:
- Token retrieval:使用每个query token检索doc token,其对应的源文档成为候选文档(k'个)
- Gathering:收集每个候选文档的所有token embedding,包括第一阶段未检索到的标记(大多数token未被检索到)
- Scoring:使用基于每个文档所有token embedding的非线性函数对候选文档进行排名
这个过程导致两个主要问题。首先,与标记检索阶段相比,聚集所有文档token embedding并重新评分可能会使数据加载和浮点计算成本成数量级增加,使多向量模型的部署极其昂贵。其次,虽然候选文档是在Token retrieval阶段决定的,但之前的训练目标却是为评分阶段设计。这个设计的训练和推理之间存在差距,使多向量模型只能达到次优(且通常较差)的召回性能。
仅通过Token retrieval是否就足以实现出色的检索效果?
答案当然是肯定的,XTR(ContXextualized Token Retriever)的出现一举攻克了这个难题。XTR的核心思想在于:多向量模型中的token retrieval应该被训练成检索最有用的token,从而可以仅使用检索到的内容计算query-doc之间的分数,就像单向量检索模型一样。通过这种方式,可以完全去掉Gathering步骤,并且由于只需考虑一部分标记且可以重用标记检索的点积,使得评分成本大大降低。为了提高token retrieval的质量,XTR提出了一种简单的训练目标,大幅提高了检索准确性,使golden token在前k个结果中被检索到的概率增加了一倍。此外,尽管标记检索质量得到了提升,一些相关token仍可能被遗漏。为了解决这个问题,XTR提出了一种缺失相似度补全的方法,考虑了missing token对整体分数的贡献。
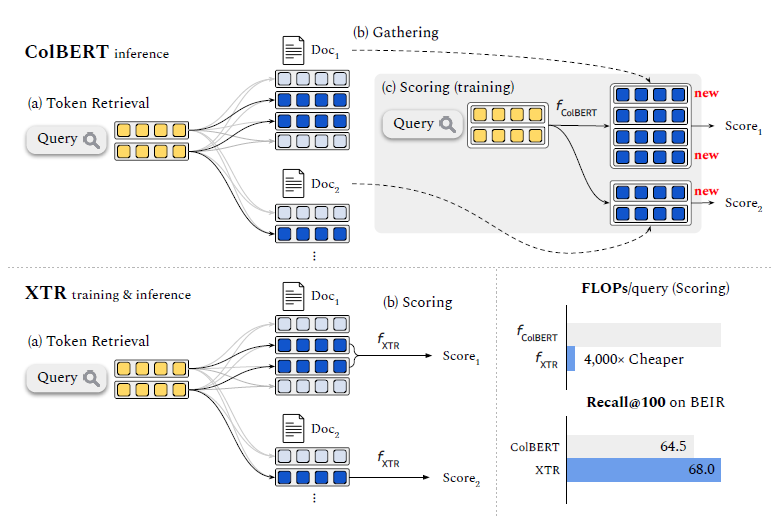
图中列出了XTR和ColBERT的主要区别:ColBERT先通过检索得到两个相关文档Doc1和Doc2,其中只有深蓝色的token embedding与query embedding匹配,然后通过Gathering得到Doc1和Doc2的所有token embedding (最右侧所有深蓝色的token),并与query embedding进行计算。XTR则去掉了第二步的Gathering环节,仅计算query与检索到的token embedding之间的得分,从而提高了检索效率,同时避免了训练与推理之间的gap。
考虑一个query \(Q = \{q_i\}_{i=1}^{n}\) 和一个doc \(D = \{d_j\}_{j=1}^{m}\),其中 \(q_i\) 和 \(d_j\) 分别表示 \(d\) 维的查询标记向量和文档标记向量。
ColBERT为什么会失效?
简而言之,是由于sum-of-max算符所致。
首先给出一些定义,多向量检索模型计算query-doc相似度的公式:
\[f(Q,D) = \sum_{i=1}^{n} \sum_{j=1}^{m} A_{ij} P_{ij}\]
其中,
\[P_{ij} = q_i^\top d_j\]
并且 \(A \in \{0, 1\}^{n \times m}\) 表示对齐矩阵,\(A_{ij}\) 是查询标记向量 \(q_i\) 和文档标记向量 \(d_j\) 之间对齐值。ColBERT 的 sum-of-max 算符设置 \(A_{ij} = 1_{[j=\arg\max_{j'} (P_{ij'})]}\),其中 argmax 操作符在 \(1 \le j' \le m\) 范围内(即来自单个文档 \(D\) 的标记)。然后,\(f_{\text{ColBERT}}(Q,D)\) 定义如下:
\[f_{\text{ColBERT}}(Q, D) = \frac{1}{n} \sum_{i=1}^{n} \sum_{j=1}^{m} A_{ij} P_{ij} = \frac{1}{n} \sum_{i=1}^{n} \max_{1 \leq j \leq m} \mathbf{q}_i^\top \mathbf{d}_j\]
论文举了一个ColBERT失效(比较极端的)例子:
假设Q是Query,D+是正文档,D-为负文档,q和d分别代表Q和D中的某个token。假如f(Q,D+)=0.8,其中所有\(A_{ij}=1\)的\(q_{i}^{T}d_{j}^{+} = 0.8\)。而对于所有负文档f(Q,D-)=0.2,但这些负文档中都存在一个 \(q_{i}^Td_{j}^{-} > 0.8\) 的峰值相似度(highly peaked token similarity),同时其他 \(q_{i}^Td_{j}^{-} \rightarrow 0\) 。在这种情况下,由于sum-of-max算符仅在乎文档级别的分数,将导致训练时的交叉熵损失趋近于0。但在推理时,考虑到实际情况中token retrieval的k'=1,此时正文档却不能被检索出来。
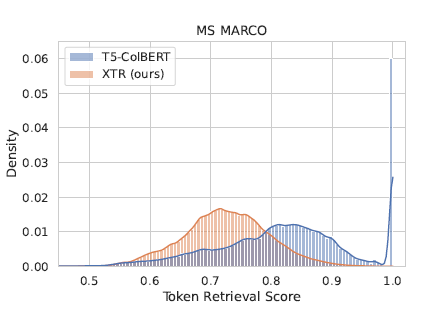
上图显示了 sum-of-max 训练导致许多doc token具有不合理的高分,无论它们与query token的实际相关性如何。ColBERT的sum-of-max训练不能降低某些高分negative tokens的分数。
In-Batch Token Retrieval
为让多向量检索模型可以直接检索相关文档的token,训练过程模拟了token检索的过程,仅需要对对齐矩阵\(\hat{A}\)稍做修改:
\[f_{\text{XTR}}(Q, D) = \frac{1}{Z} \sum_{i=1}^{n} \max_{1 \leq j \leq m} \hat{A}_{ij} \mathbf{q}_i^\top \mathbf{d}_j\]
具体来说,ColBERT中的argmax是对于单个文档的所有token(\(1 \le j' \le m\)),而XTR中的argmax是对于一个mini-batch中所有文档的token(\(1 \le j' \le mB\))。此处思想是:仅考虑在一个文档中相似度能排到mini-batch中前k名的token。Z是归一化指数,指可检索到至少一个doc token的query token的总数,若为0,则设为一个较小的数。
XTR不会给负文档分配高相似度,因为正文档的token并不能被检索出来参与计算。在之前的失败案例中,尽管正文档 D+不能被检索出来,ColBERT 仍然给它打了高分。而在XTR训练过程中,由于正文档 D+ 的token未被检索到, f(Q,D+)=0,该相似函数可以引发高损失,给模型以负反馈。因此,虽然训练数据是文档级别的标注,但XTR的训练目标则鼓励正文档中重要的token被检索出来。
此外,在推理阶段,每个query token检索 k' 个doc token,假设每个doc token属于一个唯一的文档,那么共有C=nk' 个候选文档。在没有Gathering的情况下,我们只能用一个token相似度来评分每个文档。然而,在训练阶段每个正文档最多有 n 个标记相似度进行平均计算。因此,在推理阶段,通过补全每个query token的缺失相似度,达到与训练时相同的效果。
对每个候选文档\(\hat{D}\),定义推理时的打分函数:
\[f_{\text{XTR}'}(Q, \hat{D}) = \frac{1}{n} \sum_{i=1}^{n} \max_{1 \leq j \leq m} \left[ \hat{A}_{ij} \mathbf{q}_i^\top \mathbf{d}_j + (1 - \hat{A}_{ij}) m_i \right]\]
其中\(m_i\)为\(q_i\)的缺失相似度。当\(\hat{A}_{ij}=1\)时,可复用检索阶段的\(\mathbf{q}_i^\top \mathbf{d}_j\)值,而当\(\hat{A}_{ij}=0\)时,用\(m_i\)近似sum-of-max的结果。论文采用了一个简单的策略确定缺失相似度的值:\(m_i=\mathbf{q}_i^\top \mathbf{d}_{k'}\)。
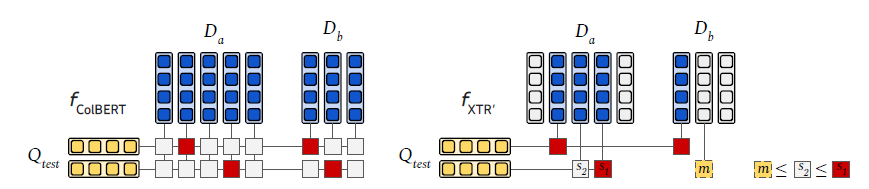
上图中,假设\(D_a\)和\(D_b\)被选为token retrieval的初始候选文档,此时\(k'=2\)。ColBERT 加载了\(D_a\)和\(D_b\)的所有token向量,并计算相似度的最大值(红框)。而XTR不加载doc token向量,并重用第一阶段token retrieval的分数。假设在top-2标记检索结果中,第一行的query token检索到了\(D_a\)和 \(D_b\)的最大值,但第二行的query token只从\(D_a\)检索到了两个token。我们通过使用第二行query token的top-2得分 s2作为上界来补全\(D_b\)的缺失相似度 m(黄框),其中 m <= s2 <= s1。
实验结果
在 MS MARCO数据集上用 RocketQA 的固定负样本微调 XTR。XTR在域内、零样本和多语言情况下(mXTR),都展示了较好的效果。
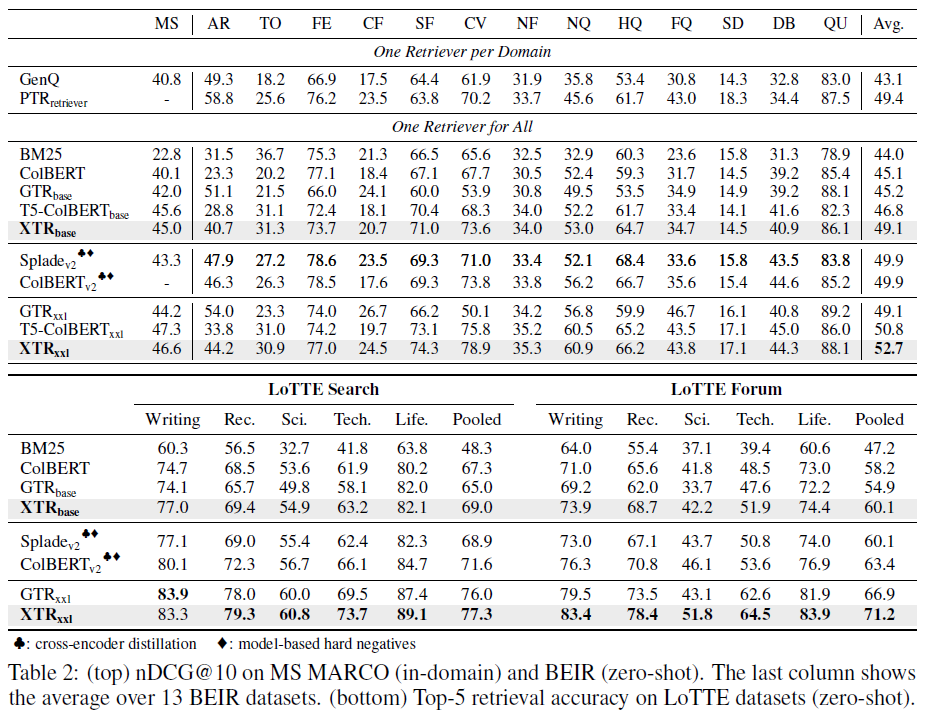
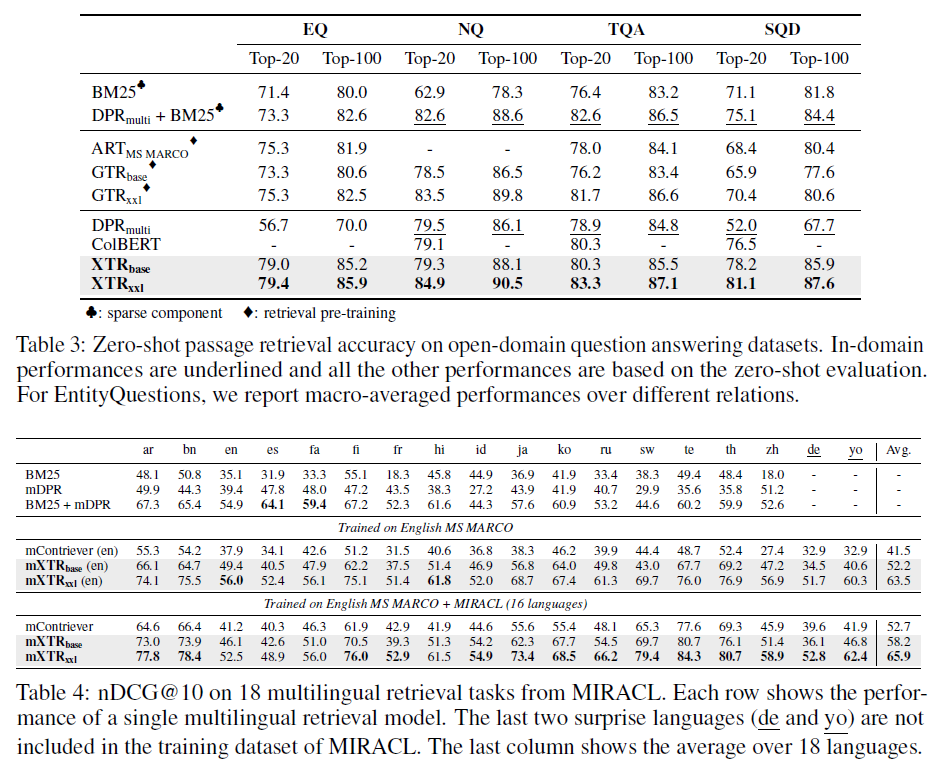
XTR简化了推理,使其更接近于双编码器的简洁流程,同时保持并增强了多向量检索模型的表达评分功能。在BEIR 和LoTTE基准测试中,XTR达到了最先进的性能,既不需要蒸馏也不需要硬负采样。值得注意的是,XTR在没有任何额外训练数据的情况下,超过了最先进的双编码器GTR在BEIR上的nDCG@10得分3.6。在EntityQuestions基准测试中,XTR在前20个检索准确性上比之前的最先进水平高出4.1分。XTR也不需要二次预训练就能进行检索,并且在MIRACL上大大超过了mContriever,该基准测试包含18种语言的多语言检索任务。实验证明XTR确实得益于检索更多上下文相关的标记,同时使评分阶段的成本降低了两个到三个数量级。