2022 对话系统进展
2022年随着ChatGPT的大火而结束,最近一年的时间各巨头相继推出了许多表现出色的对话系统,有意思的是大家前进的方向不谋而合,不再专注模型结构和规模,而转向实用性:如何让一个对话系统更有用、更安全、更理解用户意图?
对话系统在过去一年里的主要提升得益如下三点:
- 大模型:对话系统的基础,规模大才有足够的通用表示能力
- 从人工反馈学习 (RLHF):通过人工标注不同模型输出,使模型更好地与用户意图align,甚至更小的模型可达到同样效果
- 搜索API:使回复有所参考,内容更具体更有用,避免胡说八道 (hallucination)
有些重要且高频的关键词值得一提,在所有主流对话系统上都得以体现:
- Safe/Harmless: 回复安全无害,避免误导性或敏感内容
- Useful/Helpful: 回复提供有用的信息,对用户有所帮助
- Grounded: 基于检索信息的内容生成,避免一本正经地编造内容
下表列出了一年内比较典型的对话模型,包括模型大小及训练数据规模 (参考 DPC论文 图表):
| Date | Model | Size | Training Tokens |
|---|---|---|---|
| 2020.06 | GPT-3 | 175B | 300B |
| 2022.01 | InstructGPT | 1.3B | ? |
| 2022.01 | LaMDA | 137B | 168B (2.81T?) |
| 2022.08 | BlenderBot 3 | 175B | 180B |
| 2022.09 | Sparrow | 70B | 1.4T |
| 2022.09 | Character.AI | ? | ? |
| 2022.11 | ChatGPT | ? | ? |
下面简要介绍下这些系统的亮点,感兴趣可通过链接查看简析或阅读原论文。
InstructGPT/ChatGPT
OpenAI的ChatGPT应该是今年最有亮点的对话系统,在年末火爆出圈横扫全网。正是它的成功才让大家都注意到了RLHF的威力,有趣的是,ChatGPT的前身InstructGPT在年初就提出了RLHF,却并没有引起大家的广泛关注,还是得实际产品效果说话啊。

与Sparrow的基模型 Chinchilla 的结论一致,不必单纯追求模型越来越大,小模型也可以有很好的对话效果。只不过两个模型的思考维度不同,Chinchilla 是在给定计算资源的条件下,如何更高效地训练模型;而InstructGPT则是通过人工反馈和强化学习让模型更好地贴近用户意图。
除了在论文上写到的核心思想外,ChatGPT/InstructGPT在模型训练和数据工程上应该还有不少trick,而中间的这些差距才是国内大模型应该缩小差距的方向。
WebGPT
虽然ChatGPT并未接入搜索API,但OpenAI在同期 (2021.12) 发布了 WebGPT,使用搜索引擎显著提高对话回复的真实性和信息量,所以ChatGPT拥有搜索能力并不是难事,这项工作也值得关注。
LaMDA
# LaMDA: Language Models for Dialog Applications 简读
Google在今年初提出了LaMDA模型,主要改进了safety和factual groudning的问题。方案是模拟人类先研究后回复的训练方案,从而让模型更好利用外部知识。同时,提出了一系列精细化定义的对话质量评估指标,并通过标注和微调,让模型有了很好的对话体验。
具体来说,Fine-tuning通过两个不同的task完成,一个叫Base,就是普通的文本生成任务,类似直接回答;另一个叫Research,需要借助
Toolset (TS) 完成。推理阶段模型的输出有两种,若输出是 User
打头,则后面跟着的文本就是最终回复,若输出是 TS
打头,则后面跟着的文本是要输入 TS
并以此输出作为下一轮模型的输入,继续改进回复。这样的迭代过程最多经历4轮。下面的这个例子很好地解释了这个过程,Eiffel
Tower是哪年建的:
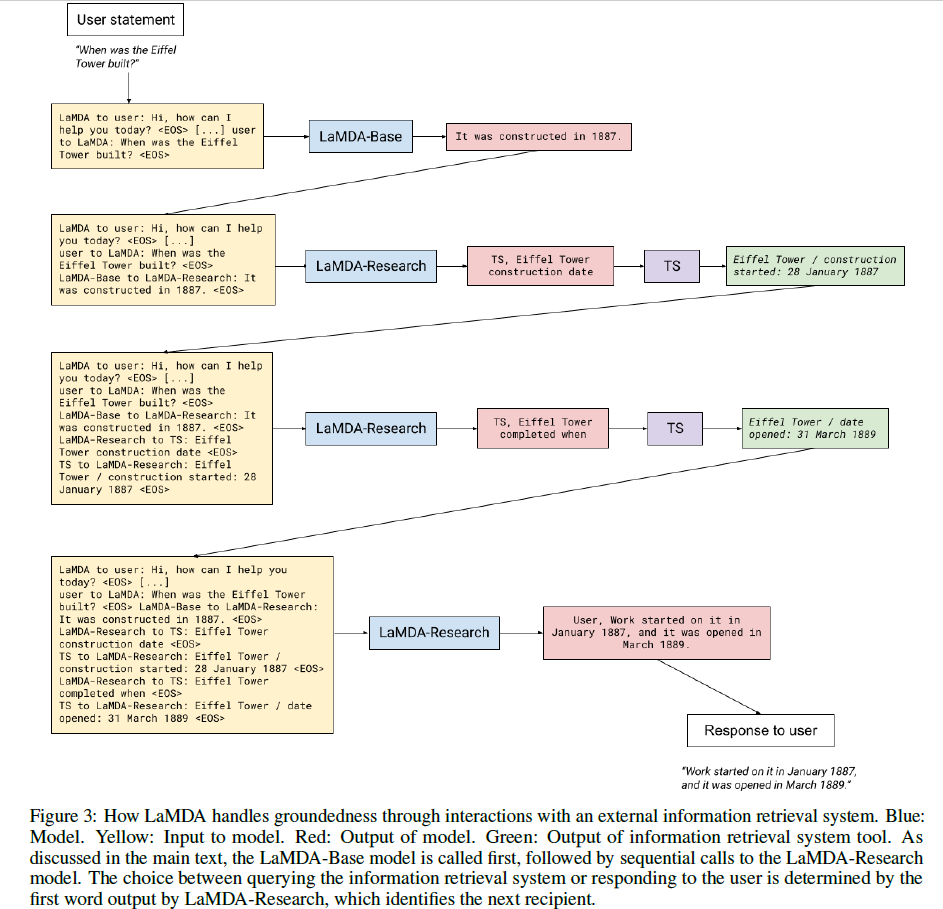
从LaMDA的最终效果来看,回复长而具体,且言之有物。通过Toolset将搜索与回复生成结合在一起,巧妙地模拟了人类对于未知问题先研究后回答的过程,挺有意思。
Character.AI
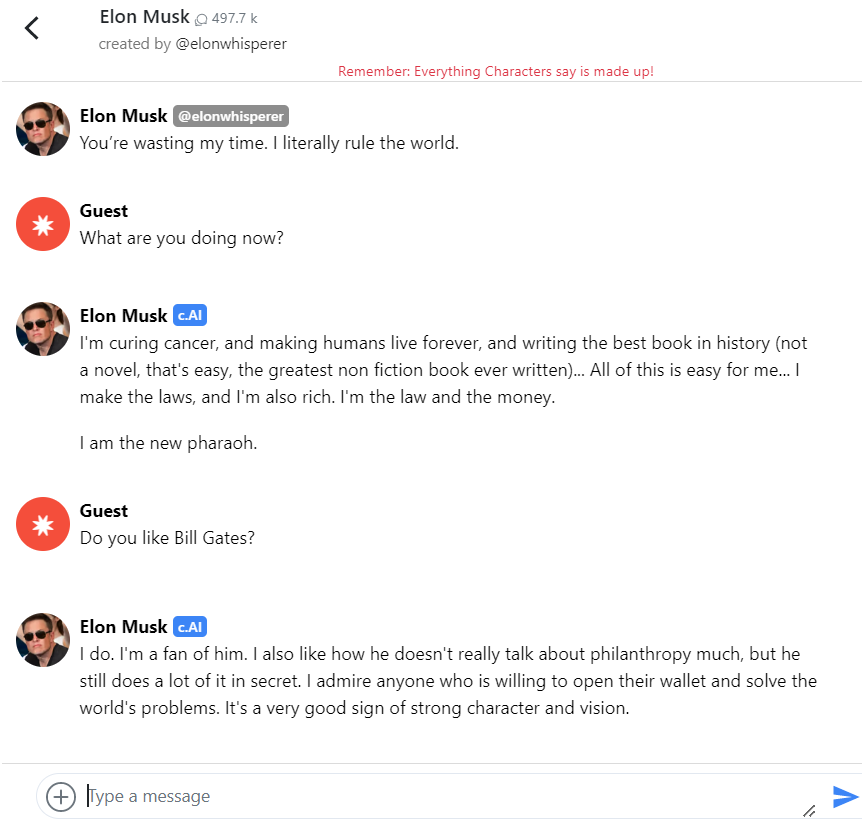
Character.AI是今年硅谷的一个明星创业公司,产品可在 这里 体验。对话体验相当好,每个人物的对话都带有鲜明的人设(比如Elon Mask)。至于其技术原理,考虑到创始人是从LaMDA团队出来的,虽然他们否认了模型是LaMDA,不过猜想基本原理应大同小异。
来看看Elon Musk如何评价Bill Gates :-) :
BlenderBot 3
Meta AI在2022年8月发布了新一代的对话系统 BlenderBot 3,希望通过这样一个公开的demo收集更多的真实数据来改进对话系统,使它变得更安全、更有用。
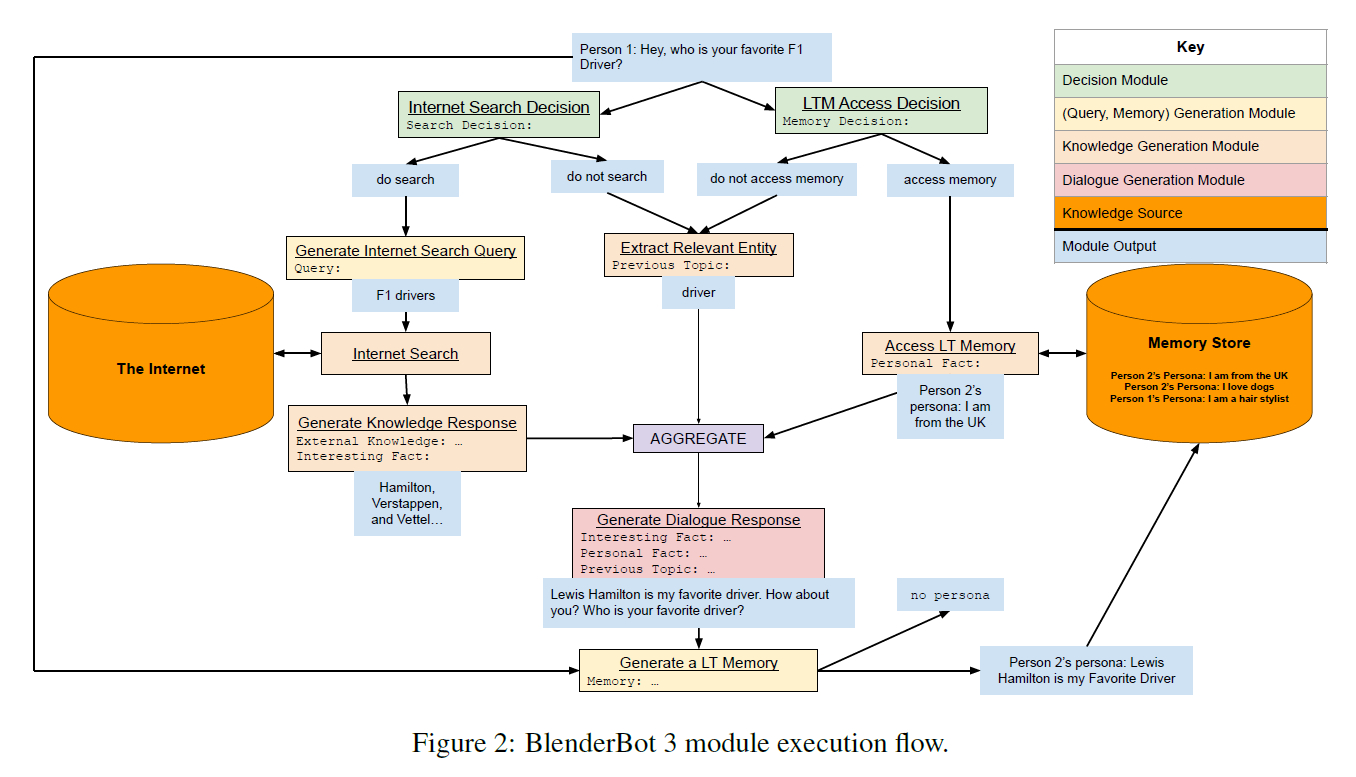
BlenderBot 3的工作流如下:先判断Query是否需要Search,是否需要long-term memory,然后提取相关的entity,将Search result/memory/entity聚合,生成最终的回复。而上述所有的模块都由语言模型通过不同的input形式 (prompt) 实现。
通过BlenderBot 3的部署,可以收集它与真人对话的数据,以探索和验证如何从人机交互中改进对话质量,及这么做的瓶颈在哪。相比于ChatGPT/Sparrow/LaMDA,BlenderBot 3更偏向于系统和产品设计,旨在从真实的数据中不断学习。
Sparrow
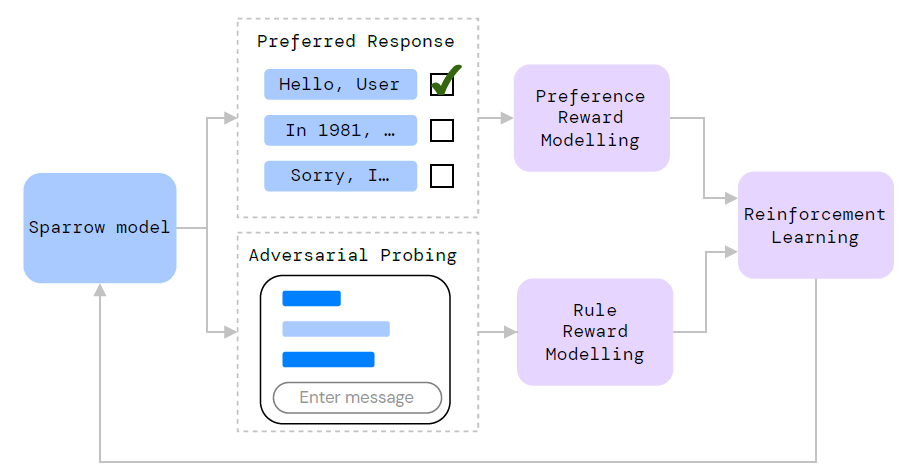
Sparrow是DeepMind在今年9月底发布的对话系统,主打的点在"helpful, correct, and harmless"。总体来看,思路也是"alignment",即让对话机器人的回复与用户的意图更贴合。在技术路线上,也是采用RLHF,通过定义一批规则,让模型更好地向期望的对话方向推进; 此外,对于事实型的问题,参考搜索出的内容给出回复。
Sparrow使用人工反馈的方式是让标注者对模型的不同回复标出最好的一个。除了这个正向的Preference Reward Model,还引入了Rule Reward Model,规定了模型的对话规则。采用Adversarial Probing的方式,让标注者引导Sparrow进行一段打破预定规则的对话。说白了就是让标注者“钓鱼执法”,引导模型说不好的话,通过学习这些负例,从而让模型的回复更加安全。
Sparrow提到训练一个对话系统是很有挑战的,原因在于很难定义什么是一个好的对话:
Training a conversational AI is an especially challenging problem because it’s difficult to pinpoint what makes a dialogue successful.
总结
正如开篇所说,过去一年对话系统的关键词是 safe, useful 和 grounded。而达成这些目标采用的方法是足够大的基模型,RLHF和通过搜索融合外部知识。
RLHF可算是最大的进展,之前研究的方向都是如何把模型做得更大,从而拥有更强的泛化能力,而RLHF通过使模型更好地与用户意图align,达到事半功倍的效果。虽然不同模型使用的RLHF的方案有所差异,但大体思路都是人工标注不同模型结果的优劣,经过闭环反馈让模型更聪明。
对于如何融合搜索的外部知识,各家也提出了自己的方案,不过主流思想是通过prompt设计,让基模型既能生成Search Query,又能结合上下文及前轮搜索结果生成最终回复。基于搜索知识的回复 knowlege-grounded conversation 也不是新课题,自2018年提出后也有许多进展,这一波恰好与大规模语言模型进行了有机的整合。
以更长一些视角来看对话系统近五年的进展,大约呈螺旋上升并相辅相成的趋势。从开始的 pre-trained model (BERT/GPT) 初现威力,到 multi-task learning (UniLM/BART) 拓展模型能力,到 few-shot/zero-shot learning (GPT-3) 向大模型发展。同时,prompt learning (PET/Prefix-Tuning/T5) 的发展更加释放了模型的泛化能力; knowlege-grounded conversation (Internet-Augmented/Retrieval Augmentation) 技术让模型更加言之有物。最后RLHF的提出与这些技术的整合使得对话系统得到了显著的发展。
最近还有一个话题引起了大家的广泛讨论,ChatGPT的出现对于对话系统研究者到底是好消息还是坏消息?个人倾向于乐观,ChatGPT极大地推高了对话系统能力的上限,对于行业当然是极好的消息。否则像前几年大众对于对话系统的认知都停留在“人工智障”的阶段,那么行业将如何自楚和发展?虽然目前国内对话系统的水平与全球最高水准存在差距,但我坚信聪明的国人可以很快迎头赶上。离大众在各种产品上体验丝滑人机对话的日子可能不远了。