WebGPT 简读
WebGPT是OpenAI在2021年底发布的解决long-form quesion-answering (LFQA) 的方案。比InstructGPT的提出稍早一些。
WebGPT: Improving the Factual Accuracy of Language Models through Web Browsing
WebGPT: Browser-assisted question-answering with human feedback
WebGPT想解决什么问题?让开放域QA回复更长更可靠。
A rising challenge in NLP is long-form question-answering (LFQA), in which a paragraph-length answer is generated in response to an open-ended question. LFQA systems have the potential to become one of the main ways people learn about the world, but currently lag behind human performance.
WebGPT的思路类似 Knowledge-Grounded Conversation ,利用搜索引擎做相关文档检索,从而生成更长的答案。主要的两个贡献:
- 微调的语言模型可以与一个基于文本的Web浏览环境交互,从而可以端到端地使用模仿和强化学习优化检索和聚合效果。
- 参考Web检索出来的信息生成回复。labeler可以根据检索出来的信息判断factual准确率,降低了独立调研问题正确性的难度。
这个想法并非WebGPT首次提出,在2021年初Facebook (FAIR) 就提出使用搜索引擎来提升对话回复的质量:
[ACL2022] Internet-Augmented Dialogue Generation
We propose an approach that learns to generate an internet search query based on the context, and then conditions on the search results to finally generate a response, a method that can employ up-to-the-minute relevant information.
虽然发表在ACL2022,但这篇paper是在2021年初就提出了。WebGPT比它的思路更进一步,完全模拟了人使用搜索引擎的方法(有更多action: 搜索、点击、翻页、回退等等),而非仅生成search query并使用其结果。
Web交互设计及工作流程
之前的工作如REALM和RAG都聚焦在提升文档检索性能,而WebGPT直接使用Bing Search API来解决这个问题,有两个优势:
First, modern search engines are already very powerful, and index a large number of up-to-date documents.
Second, it allows us to focus on the higher-level task of using a search engine to answer questions, something that humans can do well, and that a language model can mimic.
所谓text-based web-browsing environment长这样,也就是模型与Web交互的界面:
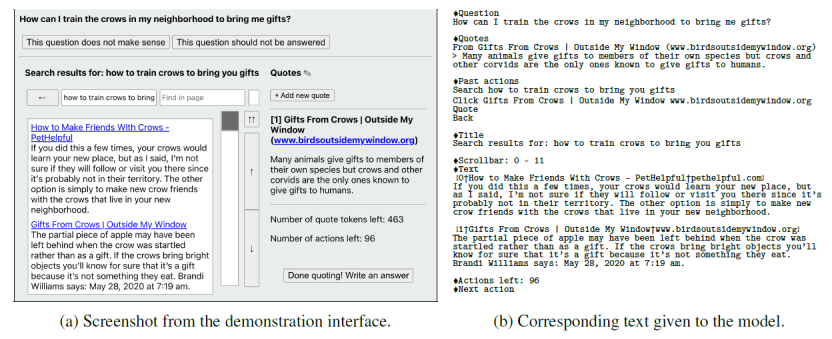
如上图右边所示,模型输入是一段prompt,包含问题、当前位置的文本、过去的actions、标题等等信息。作为响应,模型必须输出下列action之一:

重复上述过程,并且上下文信息只在summary中出现。这些action中有一个是Quote,它会将标题、领域等等信息记录下来作为将来模型输入使用。这个过程继续直到end browsing出现,或超过最大action数,或达到reference最大长度,模型就进入生成阶段,生成最终回复。
训练方法
数据收集
Guidance from humans is central to our approach.
训练数据分为两部分,demonstrations和comparisons:
- demonstrations: 预训练语言模型不会使用Web浏览,所以需要收集真人使用搜索引擎回答问题的数据。
- comparisons: 训练后发现,只用demonstrations并不能直接提升回复质量。所以收集了对同一问题模型生成的多个回复,并标注哪个更好,这种数据就是comparisons。
所谓comparisons数据与InstructGPT的RLHF思想一致,主要动机是让模型判别哪个答案更优。
为了更容易地收集这两种数据,还设计了两个对应的GUI,细节可以看原文。
For both demonstrations and comparisons, we emphasized that answers should be relevant, coherent, and supported by trustworthy references.
训练
训练主要基于之前GPT-3预训练模型的三个版本:760M, 13B 和 175B。训练方法如下:
- Behavior cloning (BC): 用demonstrations数据,以真人输出的command为目标finetune模型。
- Reward modeling (RM): 基于BC,将最后的非嵌入层去掉,以question/answer/reference为输入,scalar为输出,训练一个RM。
- Reinforcement learning (RL): 使用PPO算法,finetune BC模型。
- Rejection sampling (best-of-n): 从BC或RL模型采样固定数目的答案,取RM打分最高的一个作为优化RM的替代方案。
可见,训练的前三步与InstructGPT完全一致,唯一区别就是第一步的BC模型与SFT模型所用训练数据不同。
效果评估
ELI5是个开放域LFQA数据集。评估效果如下:
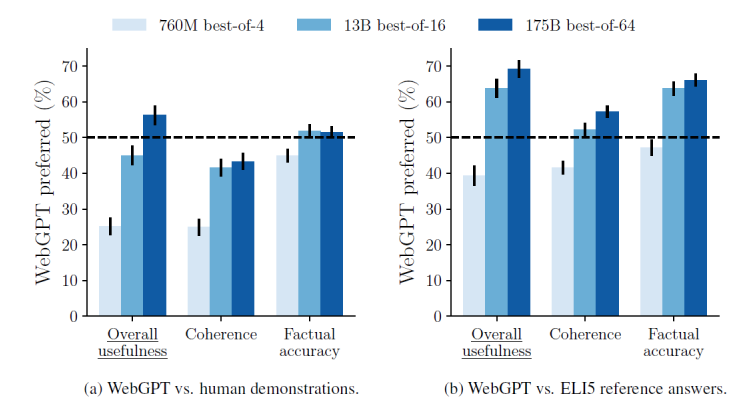
最好的175B best-of-64模型在usefullness和factual accuracy上都超过了真人。
Our results are shown in Figure 2. Our best model, the 175B best-of-64 model, produces answers that are preferred to those written by our human demonstrators 56% of the time.
结论(划重点)
- 使用搜索引擎可以显著提高对话回复的真实性和信息量。这一点在LaMDA/CharacterAI/WebGPT和上文提到的ACL2022论文中都得以验证。
- Human-feedback,或者说comparison对模型效果提升至关重要。这一点在InstructGPT/ChatGPT/WebGPT和百度的Diamonte上都得以验证。
个人以为,最近对话系统的进展主要得益于上述三点:大模型,搜索加持与人工偏好标注。目前SOTA的模型基本是在某一点做得很突出或多个技术的整合。
最后,说句题外话,OpenAI做的工作都很落地和实用,动机和想法明确,不是拍一堆难懂的公式,做一些cherry-pick的实验,而实际效果不佳。这一点可能也是国内研究与顶级研究之间真正的差距所在。