Towards Boosting the Open-Domain Chatbot with Human Feedback 简读
百度最近放出来的一篇文章,发布了一个高质量中文多轮chitchat数据集Diamonte:
Towards Boosting the Open-Domain Chatbot with Human Feedback
Diamonte数据集 下载地址
现有的对话模型都使用社交网络数据进行预训练,虽然生成的语句通顺,但想生成引人入胜的回复比较困难。主要原因有两点:首先,社交网络数据是公开场合的讨论,与私下聊天场景不同;其次,模型总是输出最大概率出现的句子,而与人本身聊天的风格并不一致(之前Nucleus Sampling的文章显式指出了这一点,人人聊天输出的词汇往往出人意料)。
Firstly, there exists a considerable gap in the data distribution between the proxy human-like conversations (public group discussion) and the real human-human conversations (private two-way messaging)
Secondly, the dialogue model usually outputs the response with the highest generation probability, which could reflect the probability mass over all the training data but might not align well with human preference
解决方案很简单,那就用真人对话的数据进行微调呗,造个数据集即可,本文的主要贡献也就在此。数据生成的接口如图:
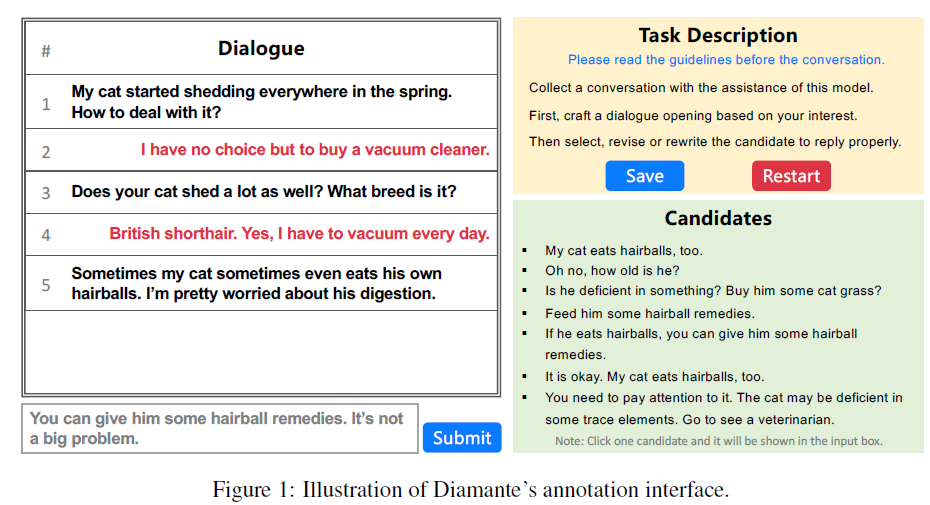
数据构造过程如下:
- annotator先写一个有趣和吸引人的开场白
- 使用PLATO-XL生成多个候选回复,用top-k sampling的解码策略保证回复多样性
- 人工筛选得到最终回复
人工生成回复有三种方式:
- Select: 直接在候选集中选出最优
- Revise: 如果候选集中的回复的一致性不好,或不吸引人,annotator可以针对某个回复进行润色,生成最终回复
- Rewrite: 候选集中的句子都不合适,人工写一个引人入胜的回复
重复上面的第2、3步,直到完成整个对话,对话至少包括7轮。
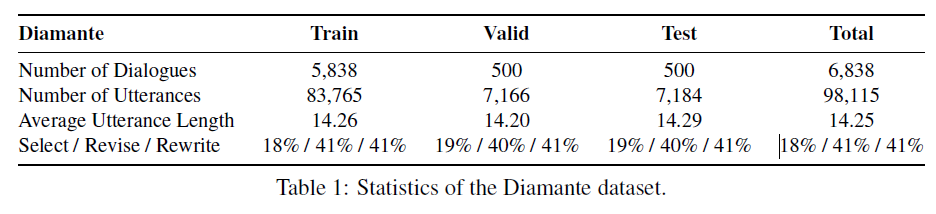
这样生成的Diamante数据集的统计数据如下,包括6838轮对话,98115个句子,平均句子长度14.25。
文章还提出了一种新的训练方式 Generation-Evaluation Joint Training,即在传统语言模型训练使用NLL loss的基础上引入了 Preference Estimation (PE) loss。公式可看原文,主要思想是让模型更好地区别回复的质量。训练时,除了dialogue context,模型还会接收三个输入:
- H: 人工筛选后的最优回复
- M: PLATO-XL生成的回复之一(不清楚是否与H有对应关系,还是只要在候选集中即可,应该是后者)
- R:随机选择的一个回复 (不清楚是从候选集里随机还是从哪随机)
显然,这三个输入会有一个优劣:H > M > R。然后PE loss就刻画了此偏好的顺序,可以更好地利用人工标注的数据集。
实验结果就不提了,自然效果不错。同时,该数据集也可以应用到别的语言模型上:
The Diamante dataset and joint training paradigm are indeed universal and not limited to one particular dialogue model.
本文思路直观,人工构建高质量对话数据集,感叹一句有钱真好。同时,地主人不错,数据集开源,推动了中文对话系统的发展。
附数据集示例,json格式:
| |