Long Time No See! Open-Domain Conversation with Long-Term Persona Memory 简读
对话系统中的个性化,或者说带有人设的AI对话机器人是个挺热的研究问题。随着虚拟人的爆火,如何能打造千人千面与用户沟通的AI,也就自然登上了舞台。今天就来看一篇ACL2022findings的文章:
[ACL2022findings] Long Time No See! Open-Domain Conversation with Long-Term Persona Memory
很多对话系统不能很好地利用用户对话的长程记忆,从而影响对话效果。百度的这篇文章提出了一个新任务 Long-term Memory Conversation (LeMon) 并发布了对应的数据集 DuLeMon。该系统可以在用户和AI对话的过程中动态提取有用的Persona Memory,并在之后的对话中同时考虑双方的Persona Memory进行更好的对话。
Demo
本文主要贡献在于构建了一个考虑用户和AI双方人设的对话系统,并发布了对应的数据集,模型并没有太多创新点。话不多说,直接看例子:
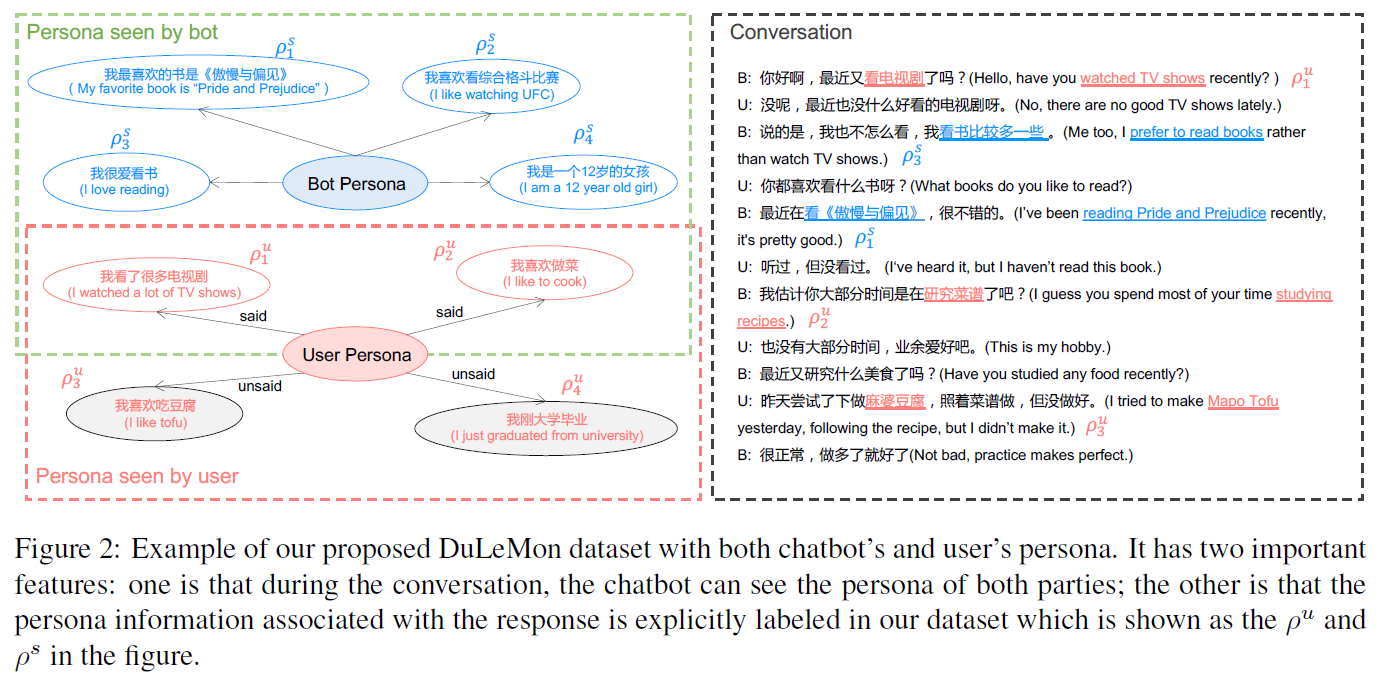
首先,Persona的定义是一个自然句描述,这也是大部分人设相关文章的通用做法。在此例中,Bot有四个Persona,用户也有四个Persona,对话开始,Bot会首先根据User Persona冷启动,开启对话:“最近看电视剧了吗?”。当用户不感兴趣时,Bot又会主动展示自己的Persona:“我看书比较多一些”。当用户愿意继续当前话题时,就接着聊;当用户切换话题或不再主动跟进时,Bot会考虑User Persona主动发问或切换话题,如此这般不停地进行下去。
PLATO-LTM工作流
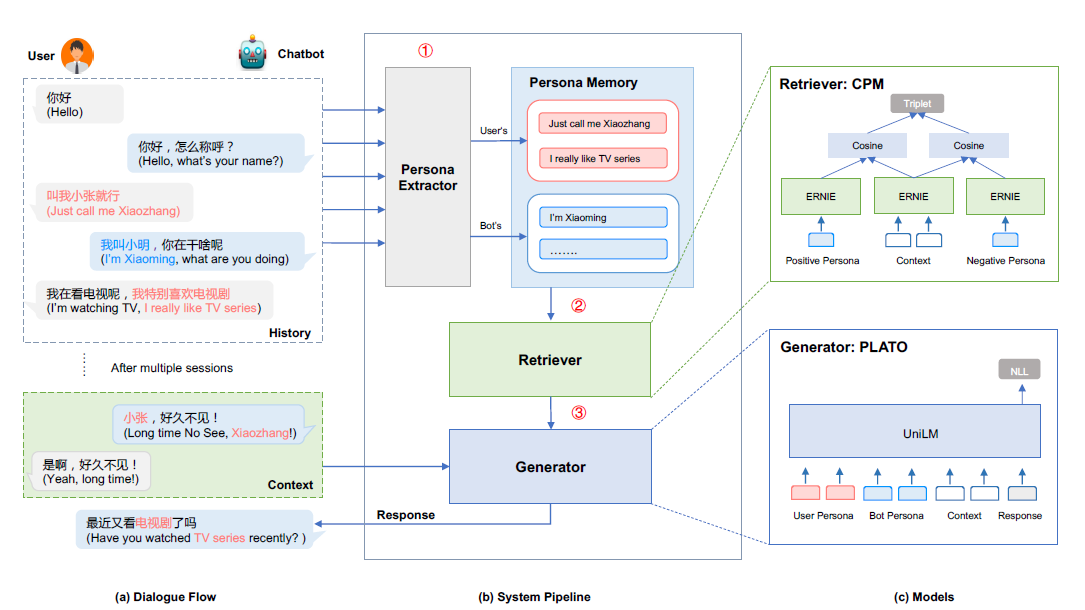
PLATO-LTM包括几个部分,也是它的工作流:
- Persona Extractor: 在对话过程中动态提取User Persona,并存储到Persona Memory
- Retriever: 在生成回复之前,先从Persona Memory中检索是否有相关的Persona为Generator所用
- Generator: 使用上下文,User Persona和Bot Persona生成回复
Persona Extractor
Persona Extractor采用ERNIE-CNN的架构,利用初始版本的DuLeMon数据集训练分类器。
Persona Memory
类似DPR的双塔结构,进行Persona的存储与检索,没什么特别的。
Generator
使用PLATO-2,一个Transformer语言模型进行回复生成。值得一提的是如何让模型学到双方的不同角色:
We added two strategies to distinguish different roles in the dialogue and prevent the confusing use of persona information.
- Role Embedding: different role embedding is used to distinguish the persona of different chat parties, abbreviated role_embed.
- Role Token: splicing “system persona” before the chatbot persona and “user persona” before the user persona, abbreviated role_token.
数据集DuLeMon
百度的文章有一大好处是大部分实验场景都在中文落地,数据集也是中文的。
During the conversation, the chatbot can see the persona of both parties; the other is that the persona associated with the response is explicitly annotated in our dataset. Unlike the PersonaChat dataset, the setting in DuLeMon is that one speaker plays the role of a chatbot, and the other plays the user’s role.
数据集的构造方式如下:
- Persona collection: 使用PersonaChat数据集进行翻译和改写所得。
- Dialogue collection: crowd-sourcing,随机分配persona给两个worker,他们按照这些persona进行一次对话。
The chatbot should think more about chatting to make it go on. It should utilize the known user’s persona to conduct the in-depth chat. The user will act as an ordinary user to cooperate with the conversation.
- Persona Grounding Labeling: 用来训练Persona Extractor,对每个response进行标注,是否使用了bot或user persona。
DuLeMon数据集的一些统计:
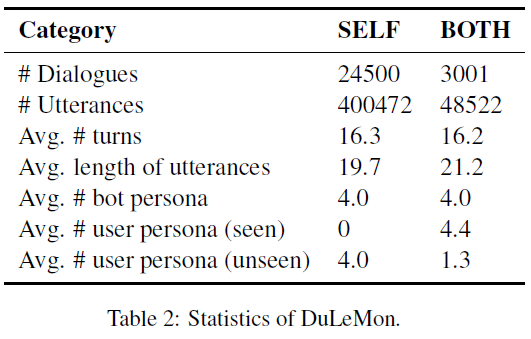
BOTH是同时考虑双方Persona的对话数,SELF是仅考虑Bot Persona的对话数,从数量级差距可见构建双方Persona的数据集成本还是挺高的。