Leveraging Similar Users for Personalized Language Modeling with Limited Data 简读
今天来看看这篇 ACL2022 的文章:
[ACL2022] Leveraging Similar Users for Personalized Language Modeling with Limited Data
解决的问题很容易理解,个性化语言模型在用户刚加入时缺少数据的冷启动问题:
Personalized language models are designed and trained to capture language patterns specific to individual users.
However, when a new user joins a platform and not enough text is available, it is harder to build effective personalized language models.
思路也比较直接,使用新用户的少量数据在已有用户中找到相似的用户,然后用相似用户的数据进行语言模型的训练,从而解决数据稀疏的问题。
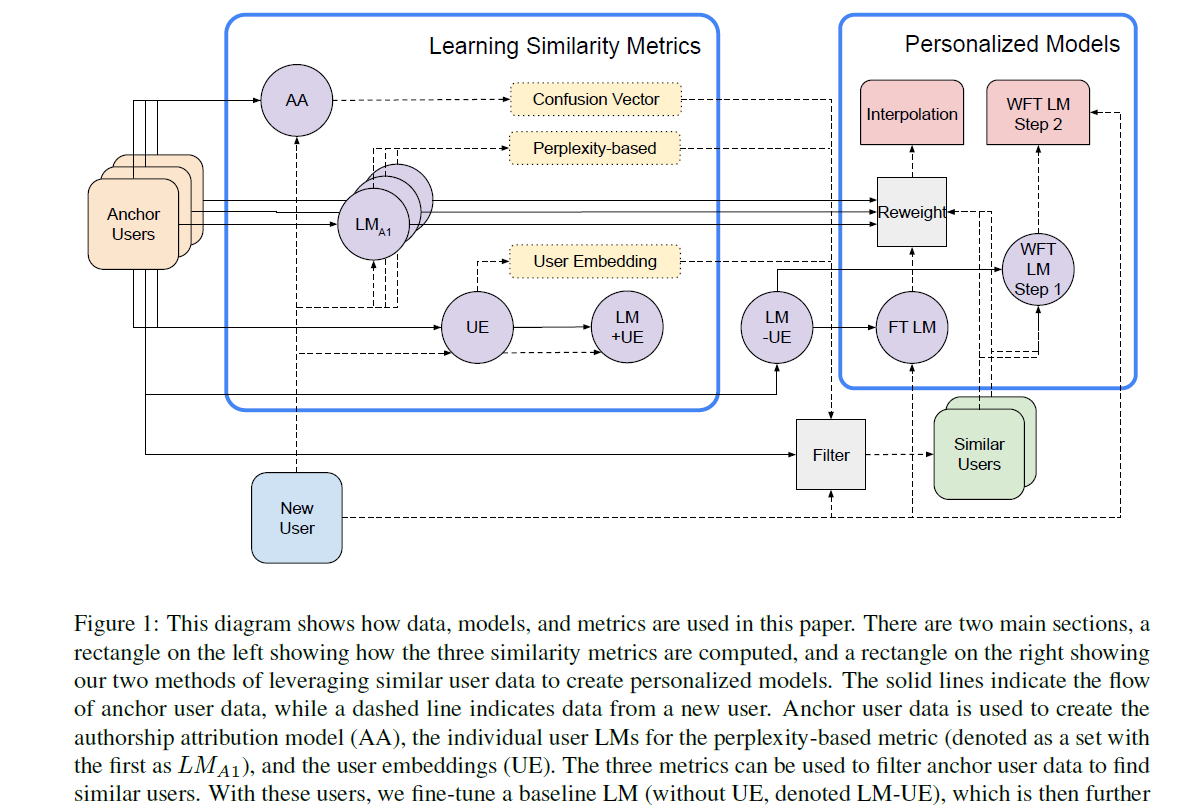
实验论文,提出了三种不同的指标来进行用户相似度计算,实验证明 user embedding + interpolate model效果最好。
数据集
使用Reddit评论数据集,并选择在2007-2015年至少有60K token文字的用户。
- anchor users: 至少有250K token文字的用户,作为已有用户的锚点,新用户进来后与这些锚点用户匹配。
清洗数据
匹配上任意一条规则的post都会被过滤掉:

相似度指标
这张图看着很绕,没太看懂想表达的意思:
Authorship Attribution Confusion
此指标主要用于衡量句子集和anchor user之间的相似度。
给定一个用户的句子集合U,A(U) 给出该句子集和所有anchor user的一个confusion vector。
不过看起来这个指标的test accuracy并不高:
For K = 100 anchors the test accuracy is 42.88% and K = 10, 000 the test accuracy is 2.42%. These accuracies are reasonably high given the difficulty of the task.
User Embedding
使用了一个已有模型,在训练语言模型时加入了user embedding:
The embeddings of anchor users can be obtained from the user embedding layer in the trained model. To learn the embeddings of new users, we freeze all parameters of the trained model except the user embedding layer.
Perplexity-Based
给定N个用户的个性化语言模型,我们可以用任意一个语言模型配上另一个用户的数据,通过PPL来评估相似度。论文先用所有anchor user的数据训练了一个大模型,再用每个用户的数据finetune成N个不同的用户语言模型。
We then measure the perplexity of each model on the data of each new user.
This step is expensive, taking close to 24 hours for K = 100 and intractable given our hardware constraints in the K = 10, 000 setting.
如何使用相似用户的数据
两种方案:
Weighted Sample Fine-tuning
先用所有anchor user的数据finetune一遍,再用新用户的少量数据finetune一遍:
Our method of weighted sample fine-tuning has two steps. The first step is to fine-tune the model trained on all anchor users on a new set of similar users, as determined by our chosen similarity metric. Then we fine-tune as in the standard case, by tuning on the new user’s data.
Interpolation Model
预测时,对每个anchor user的语言模型预测结果根据新用户与该用户的相似度进行加权。公式就不列了,看起来计算量不小,每次推断都要经过N个相似用户的语言模型。
Our interpolation model is built from individual LMs constructed for each anchor user. It takes the predictions of each anchor user model and weights their predictions by that anchor’s similarity to the new user.
结论
We found that the most easily scalable and highest performing method was to use user embedding similarity and to interpolate similar user fine-tuned models.
总体来看,本文想法不复杂,但实现并不简单。特别是在每个用户数据上finetune语言模型和计算相似度,计算量过大,影响实用性。文章写得也比较散,建议借鉴本文的思想解决相关的问题。