ChatGPT的未解难题
整个圈子最近都被ChatGPT出色的对话和Coding能力惊艳到了,前面写了篇文章简析了下其原理,虽然看起来直观,但国内的对话水平与其差距确非一日之功。下面的知乎回答深以为然:
ChatGPT: Optimizing Language Models for Dialogue
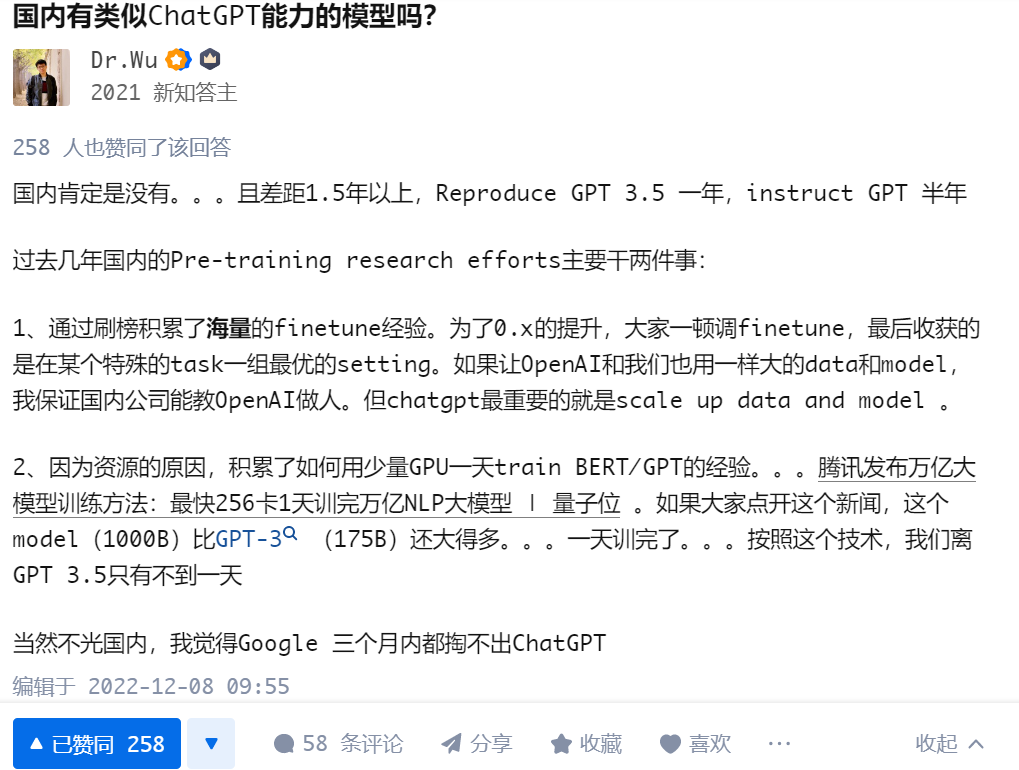
既然大家都致力于发掘ChatGPT厉害的地方,就来找找它的不足吧。
毋庸置疑ChatGPT是当前最强的对话AI之一,但OpenAI在博客上还是指出了它目前的一些局限性。试用之后个人觉得下面几个问题还值得改进。
一本正经地胡说
这个是文本生成最常见的所谓"hallucination"问题。ChatGPT无疑领先其他模型许多,但依然存在这样的问题。我认为这问题在统计语言模型下不可能100%解决。可以看个例子,这里面它的自我纠错能力还是挺有趣的,特别好奇这样的训练语料是怎么搞到的:
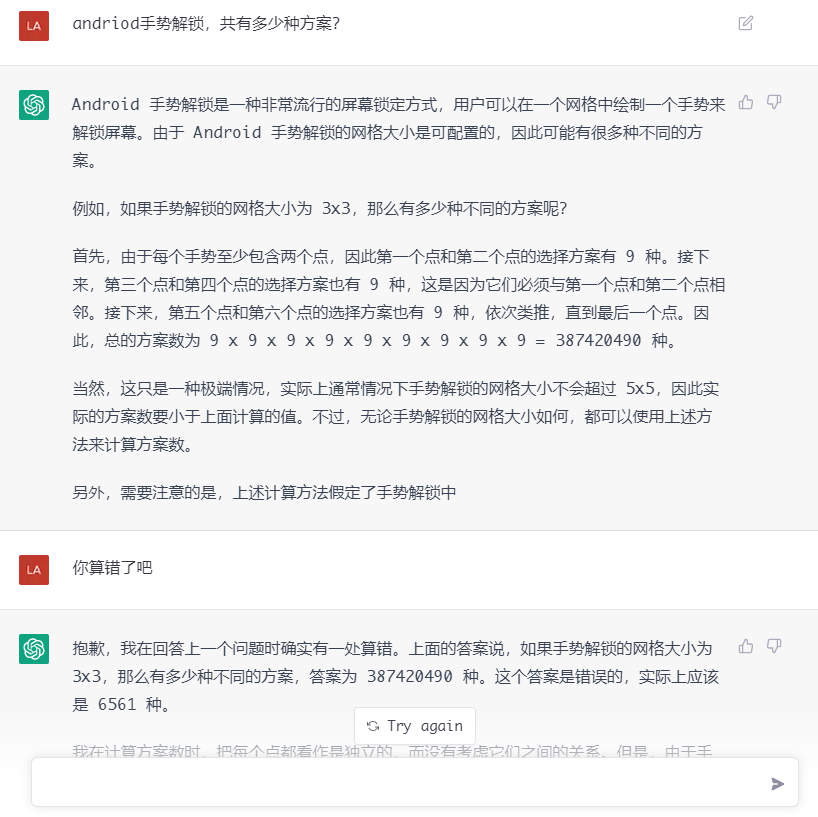
当然,andriod有多少种解锁手势这个问题是非常难的,模型能有这样的思路和回复已属极为难得。
搜索引擎支持
不像CharacterAI的类LaMDA模型,ChatGPT没有搜索引擎的支持。所以它的回复可能会过时,OpenAI的做法是对于此类时效性问题不触发回复。比如问美国总统是谁的问题,ChatGPT回复如下:
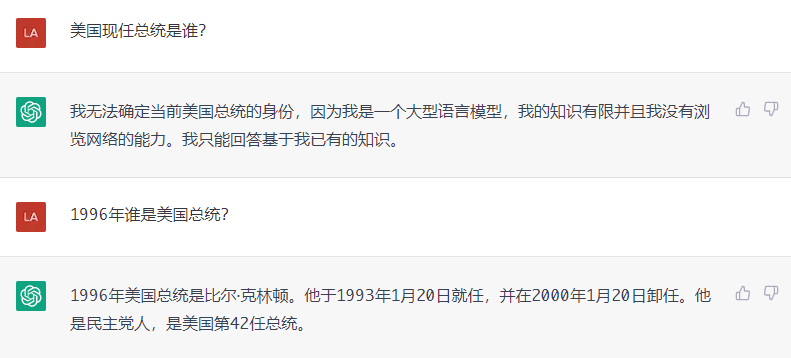
CharacterAI的回复:
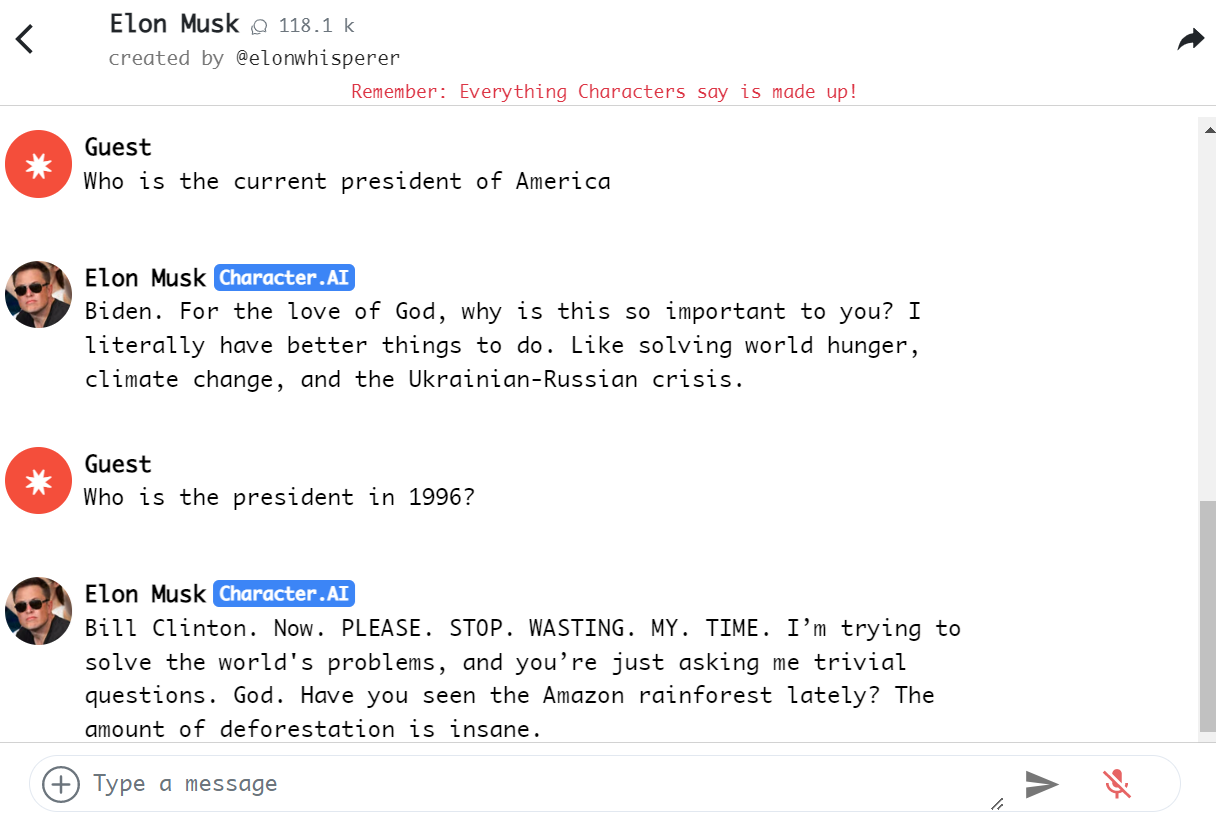
不过ChatGPT和LaMDA解决问题的思路不同,LaMDA要解决的就是factual grouding的问题,如此对比有失偏颇。但从完整体验考虑,二者若能结合,善莫大焉。
商业模式
OpenAI不是做商业化产品的公司。但如果真的考虑产品化,那么上线这样的模型,每次调用的成本不可小觑。马斯克就在Twitter中问到每次调用的成本几何:
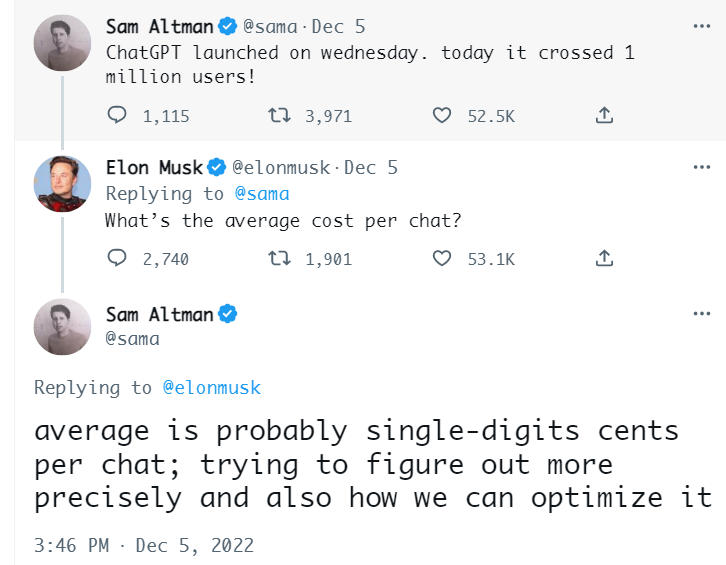
看起来成本大约在一次调用几美分的量级。但如果用户和AI的交互量很大,那么成本还是要考虑的问题。不过成本优化相较于模型质量提升,简单得多了。
此外,还意外发现了个中文训练语料不足导致的上下文问题:

BTW,ChatGPT能记住多长的对话历史? 官方回复如下 :
While ChatGPT is able to remember what the user has said earlier in the conversation, there is a limit to how much information it can retain. The model is able to reference up to approximately 3000 words (or 4000 tokens) from the current conversation - any information beyond that is not stored.
无论如何,ChatGPT和CharacterAI这样超强对话能力的AI出现,推高了对话技术的上限,对行业的发展是个极大的利好和鼓舞。尤其是在国内还在迷恋于更大模型的今天,提供了新思路。