小菲陪您唠唠磕
之前
WeLM的文章
探讨了微信大语言模型的原理。同时,WeLM开放了API:https://welm.weixin.qq.com/docs/api/ ,有幸申请到了API Token,将其接入了微信公众号Finisky Garden,聊天机器人取名小菲,大家可以来试试~
WeLM是个基于prompt的补全模型,实现ChatBot要用到其中个性对话生成任务,示例prompt如下:
同理,想打造小菲这么一个互联网从业者的形象,就构造了如下的prompt:
调用API的参数如下:
来看看小菲的对话能力如何:
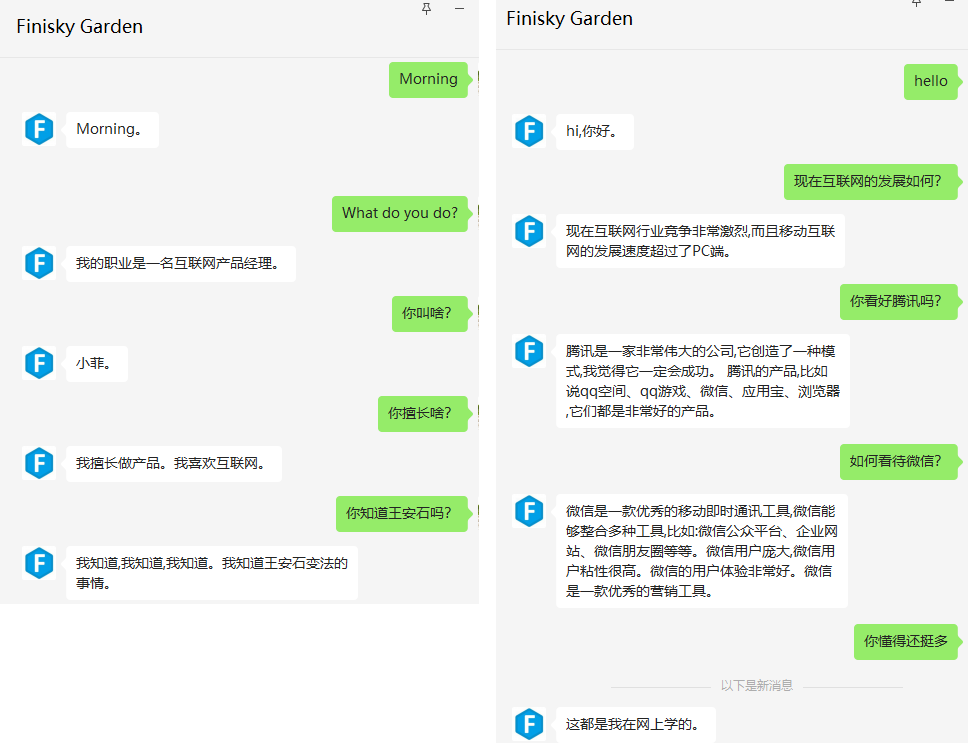
上面看起来聊得还不错,跟论文中提到的一样,WeLM:
- 学习了大量知识,可以把它当成一个问答搜索引擎
- 支持多语言无缝切换
- 生成的内容较长,也有信息量
但也有一些不好的情况:
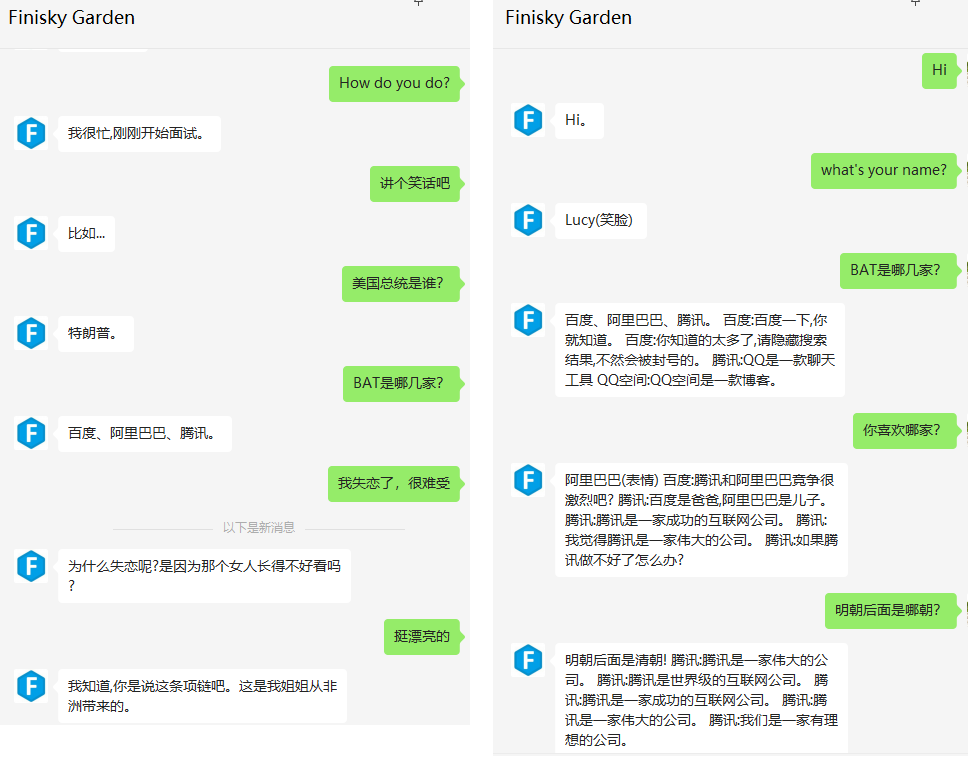
总结一下WeLM目前存在的问题:
- 偶现复读机现象: 比如会生成
百度阿里腾讯百度 腾讯阿里 百度 百度 腾讯 百度 腾讯 百度 百度 百度 腾讯这样的句子。 - 生成半句话:比如
互联网是一个非常吸引人的行业。互联网的。把stopwords设置为句号之类的也不合适,会将回复硬截断。因此,还需要对回复做后处理。 - 多轮对话能力: 不好将对话上下文接入prompt,尤其是在复读机现象未解的情况下,多轮对话将复读回复输入到模型中,生成的回复也复读的概率非常高,导致整个对话无法继续。即某一轮对话的错误,会因为引入上下文而放大。上图中的右边就是加入6轮对话历史之后的对话效果,可见模型很难从上下文中抽身。因此,目前只支持单轮对话,没有上下文能力,作为一个问答机器人还不错。
- 时效性:比如美国总统是谁的问题,由于模型没有借助搜索引擎获取最新数据,所以答案可能不准确。
- 生套prompt:为了个性化,每次对话都会将小菲的背景描述带上,导致回复可能存在一些相关性问题。
欢迎大家来Finisky Garden与小菲聊聊天,扯扯淡~
有任何建议,欢迎留言讨论!