WeLM: A Well-Read Pre-trained Language Model for Chinese 简读
微信最近有篇新闻刷屏: # 微信推出自研NLP大规模语言模型WeLM:零/少样本即可完成多种NLP任务
来看看这背后的技术原理又是什么:
WeLM: A Well-Read Pre-trained Language Model for Chinese
WeLM简介
WeLM是什么?是一个多任务零样本或小样本学习的中文预训练语言模型:
A well-read pre-trained language model for Chinese that is able to seamlessly perform different types of tasks with zero or few-shot demonstrations.
WeLM 有 10B 的参数(与GPT3 的 175B,和 Ernie 3.0 260B 的参数相比并不算很大),经过仔细的数据清洗、平衡数据源及增大训练数据规模,它的性能可以显著超过同样大小的其他模型。
We show that by carefully cleaning the data, balancing out data sources and scaling up the training data size, WeLM is able to significantly outperform existing models with similar sizes. On zeroshot evaluations, it can match the performance of Ernie 3.0 Titan that is 25x larger.
WeLM的几个特点:
- 多语言理解,在机器翻译、QA和摘要任务上都超过了有30种语言进行预训练的 XGLM 。在中日英三国语言混写的情况下(code-switching translation),WeLM也能正确地翻译。
- 通过人工手写的prompts,WeLM可以在未见过的任务上有更好的泛化能力。
- WeLM还能解释和调整自己做的一些决定。

训练数据
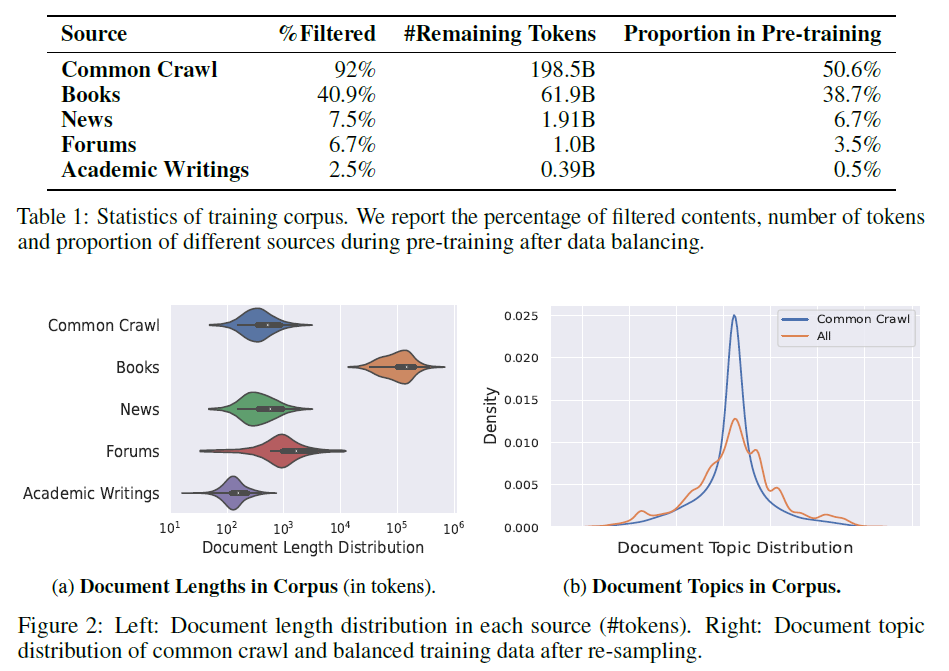
同时使用了中英文数据,总数据的原始文本大小超过了 10T。清洗数据的过程非常细,只保留正面数据,通过规则和一个二分类器过滤掉87.5%的数据。用MD5和SimHash的方式去掉40.02%的重复数据。用 17-gram 匹配的方式,去掉了剩下数据中的0.15%。
经过以上几步清洗,还剩下 262B tokens的数据。对这些数据进行重采样,以保证数据的多样性。
重采样后训练数据的统计信息:
模型
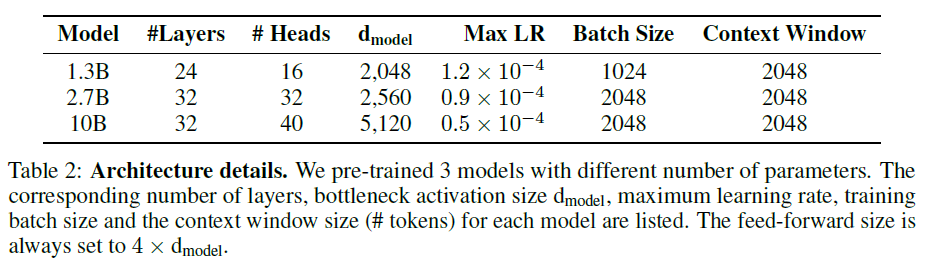
基于 Megatron-LM 和 DeepSpeed 进行训练。模型结构与 GPT3的 自回归 Transformer 相同,主要区别:
- Relative encodings: 对长文本语义更友好,本文的任务会涉及完整文章或书籍的处理。
- Vocabulary: SentencePiece tokenizer,62K tokens。其中中文token有 30K ,其余的是英文、日文和韩文。
共训练了3个(原文有typo)不同大小的模型,采用 AdamW optimizer,FP16 混合精度训练:
训练成本很可观,最大的模型用128块 A100 训练了24天:
The largest model is trained on 128 A100-SXM4-40GB GPUs in about 24 days.
由于训练不稳定,有一些训练的tricks,在大模型训练中比较要命,一旦train废了,大把钱就白花了,文中的处理方案:
We observe some instability issues when training the 10B-sized model. The training loss could suddenly increase in one batch then falls down. This loss spike, when happening frequently, would deteriorate the model weights and slows down the convergence. We mitigate this issue by re-starting the training from a checkpoint roughly 100 steps before the spike happened, then skipping the following 200 data batches. We also find it helps to reduce the learning rate and reset the dynamic loss scale.
实验
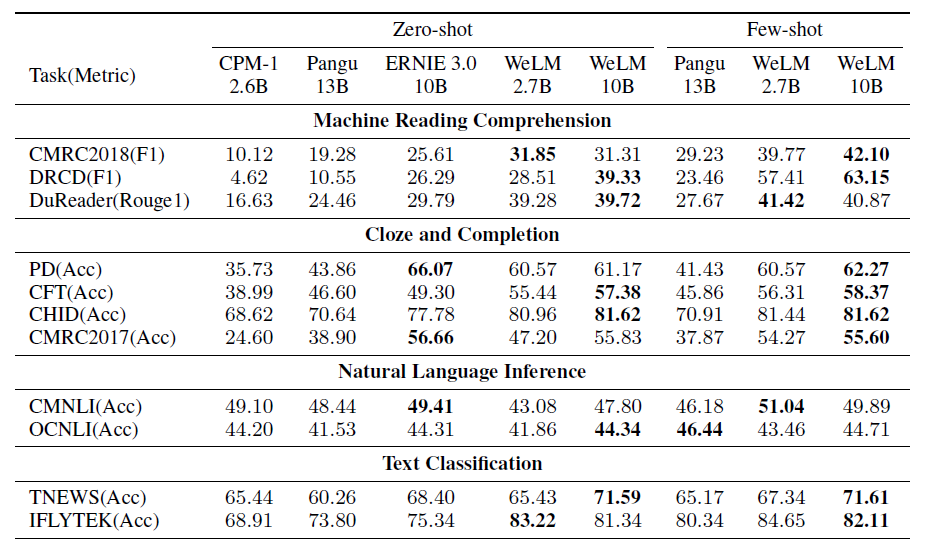
在18个中文NLP任务上,与CPM/Pangu/Ernie 3.0(10B)相比,多数情况下WeLM的性能最优:
看下我们关注的文本生成任务,WeLM作文本生成主要靠prompt。看它如何扮演李白的角色,注意,在这段对话中还有中英夹杂的情况:
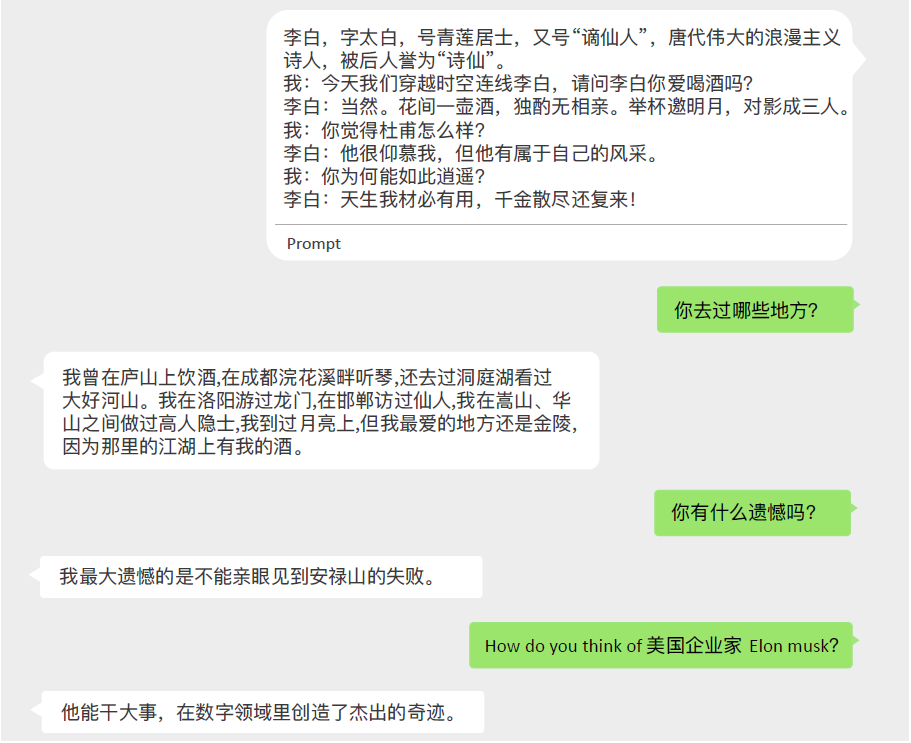
这里的对话还是挺有意思的,生成的回复也不局限于前面的prompt,还有一些额外的知识引入,不过与 Google 的 LaMDA相比,此处并没有搜索引擎的加持,而只是大模型本身的记忆。
Multitask Prompted Training
此外,作者还探索了是否可以通过显式的多任务学习来加强模型的泛化能力。方法是用人工写的不同任务的prompts训练模型,称做WePrompt。为属于14个类别的76个任务手写了 1227 个 prompts 模板:
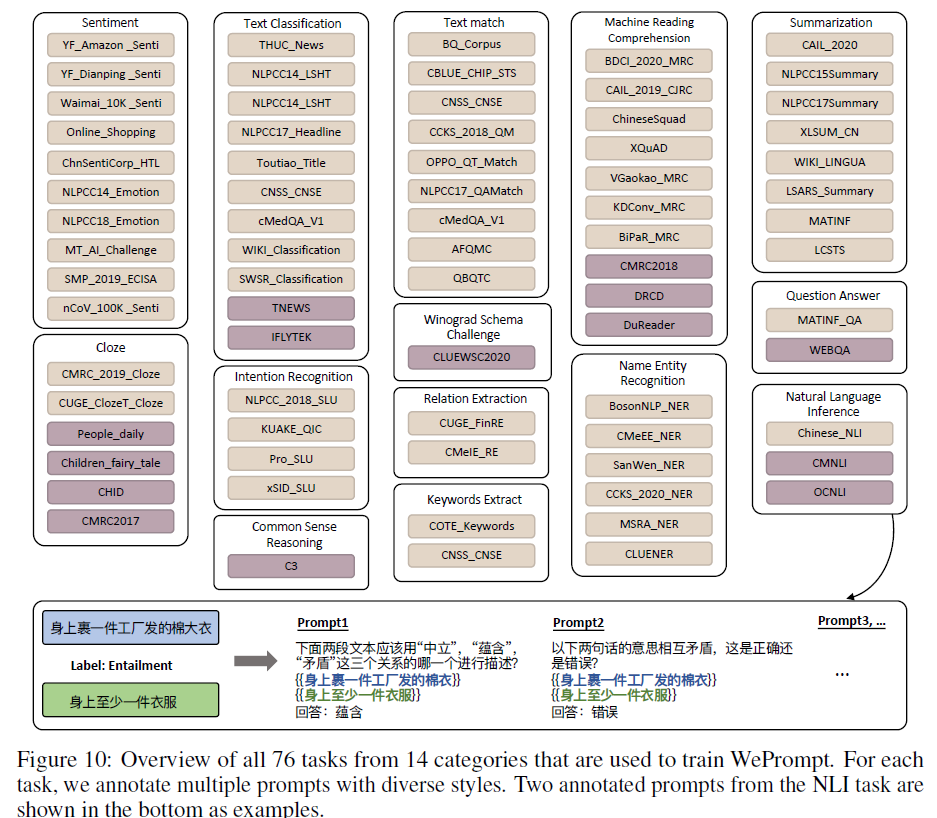
训练数据的构造:从76个任务中随机选择一个,再从该任务中采样一条标注数据和一条prompt模板,并通过这个模板构造一条自然语言训练数据,重复上述过程直到将这个句子达到2048 tokens。最后使用这些构造的数据fine-tune WeLM得到WePrompt。
WePrompt的效果自不必提,不过这解释了为什么WeLM要通过Prompt的方式进行使用:因为它是通过prompt tuning的方式进行训练的。
最后,模型还尝试了可解释性与自我纠错。看看下面这个自我纠错的例子:

总结
WeLM通过筛选高质量训练数据,跨语言训练并使用prompt tuning的方式提升模型的性能,在零样本和小样本学习中达到很好的效果。
目前看到的大模型基本都是采用与GPT3相同的自回归结构,与LaMDA一样,WeLM也花了不少功夫在筛选训练数据上面,不同的是,WeLM主要采用prompt进行推断。
目前看到的性能优良的模型,在模型本身上的创新都不多,为达更好性能基本都靠高质量数据与大力出奇迹。