Leveraging Passage Retrieval with Generative Models for Open Domain Question Answering 简读
开放域问答常常需要借助外部知识生成更有信息量和准确的答复。当检索出相关知识后,如何将它们融入生成模型就是个问题。Fusion-in-Decoder (FiD) 这篇文章提出了一个简单有效的方案。
[EACL2021] [FiD] Leveraging Passage Retrieval with Generative Models for Open Domain Question Answering
OpenQA场景
如上图所示,对一个问题,首先要从外部检索相关的文章片断,比如Wikipedia。然后,使用encoder-decoder结构,以
<question, retrieved passage>
作为输入,生成最终的回复。
This approach scales well with the number of retrieved passages, as the performance keeps improving when retrieving up to one hundred passages.
FiD模型
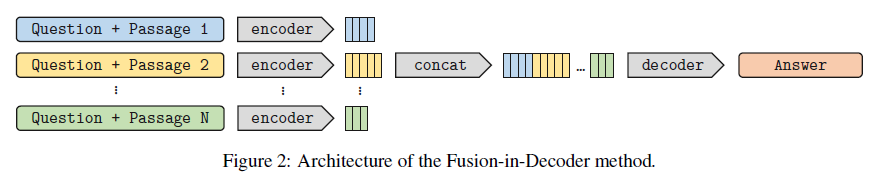
FiD的想法简单直接,将检索回来的每个passage都与question通过encoder分别编码,然后concat在一起输入decoder生成最终的回复。顾名思义,叫做Fusion-in-Decoder。
FiD模型的效果还出奇的好:
While conceptually simple, this method sets new state-of-the-art results on the TriviaQA and NaturalQuestions benchmarks.
同时,作者认为与检索模型相比,生成模型非常善于将多个passage的信息合成:
We believe that this is evidence that generative mod els are good at combining evidence from multiple passages, compared to extractive ones.
实验结果
FiD在三个数据集:NaturalQuestions,
TriviaQA, SQuAD 上的表现都非常好。
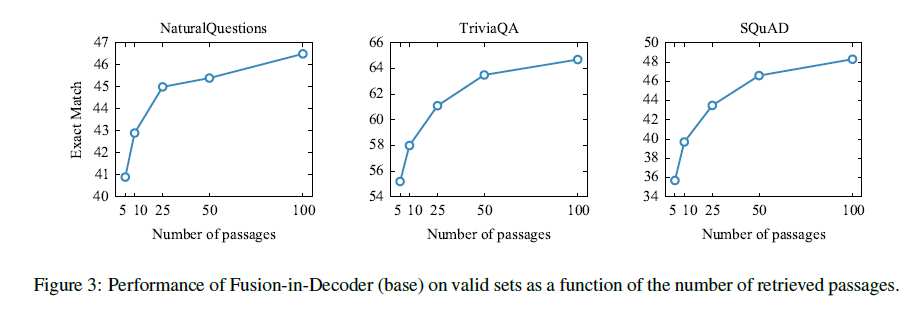
上图证明,输入生成模型的passage越多,模型的性能越好。
In particular, we observe that increasing the number of passages from 10 to 100 leads to 6% improvement on TriviaQA and 3.5% improvement on NaturalQuestions.
FiD的方案简单直接,但随着passage数目的不断增多,经concat之后decoder的输入会变得很长,训练起来的成本也随之增高不少。从 FiD github repo 的一段说明可见一斑:
Training these models with 100 passages is memory intensive. To alleviate this issue we use checkpointing with the
--use_checkpointoption. ... The large readers have been trained on 64 GPUs ...
除了OpenQA,FiD还可以拓展到一切需要多维输入的应用场景,如 Document Grounded Conversation 等。