Long-Term Open-Domain Conversation 简读
今天来看看这篇 ACL2022 的文章:
[ACL2022] Beyond Goldfish Memory: Long-Term Open-Domain Conversation
问题比较清楚,提升长期开放域对话的效果。题目用到一个梗:超越金鱼的7秒记忆,可以看出论文要解决的问题是跨越数小时甚至数天的会话。
注意: 这里是“长期” (long-term) 对话,不是 “长程”对话,即对话时间跨度比较长的对话。
本文同时发布了一个人与人进行长期对话的数据集
Multi-Session Chat (MSC),其中双方通过之前的会话互相了解对方的喜好,并在之后的对话中得以体现。
在长期对话中,使用retrieval-augmented的方式,结合对上下文对话的摘要,可以达到超越传统encoder-decoder架构的模型效果。
Introduction
Unfortunately, a major aspect missing from the current state of the art is that human conversations can take place over long time frames, whereas the currently used systems suffer in this setting.
实际的真人对话常常会持续很长的时间,而现有的对话系统处理这种情况往往不尽如人意。现有对话系统都用2~15轮对话轮数的短对话进行训练,并且只有一个会话
(session)。像目前的STOA系统Meena和Blender所使用的Transformer往往会按128个token的长度进行截断,显然不适用于处理长期对话。
Standard Transformers have a fixed context length which due to the all-vs-all self-attention mechanism becomes inefficient when it is too large.
Multi-Session Chat 数据集
本文的主要贡献之一就是收集并发布了 Multi-Session Chat 数据集,用于后续研究。
Eachchat session consists of 6-7 turns for each speaker.Then, after a certain amount of (simulated) time has transpired, typically hours or days, the speakers resume chatting, either continuing to talk about the previous subject, bringing up some other subject from their past shared history, or sparking upconversation on a new topic.
这个数据集的构建完全靠人工(真奢侈)。worker被要求扮演一个角色,而非他自己的人设进行对话。每个人设都用一系列句子来描述,这些人设共有1155条。
数据集由一系列episode构成,每个episode包括3~4个sesssion,构造方式如下:
- session 1: 使用PersonaChat数据集。
- session 2/3/4: 假设距session 1已经过去了1 ~ 7小时或 1 ~ 7天,然后两人再次进行对话 (reengage)。worker被要求与另一个worker聊6轮,且要考虑到在之前session中聊天的内容,就是说不仅要考虑自己当前的人设,也要考虑之前两人交互的细节。
个人觉得这种构建数据集的方式会导致对话内容比较刻意,而实际人与人的聊天不会信息量这么大,或者说内容聊得这么硬核。这些问题在之前构建 KGC 的 WoW 数据集时也存在。
论文列举了数据集的统计数据,及与其他数据集的对比:
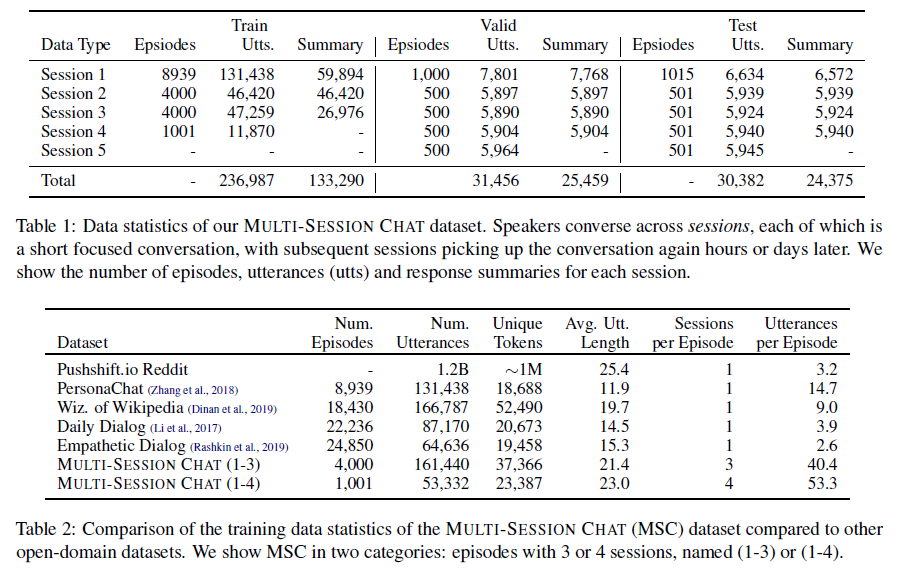
此外还有另一个众包任务,在每个session之后,要写一个之前聊天内容的摘要,所谓 Conversation Summaries。
As these summaries were collected in order to store the important points pertinent to either one or the other speaker, they can also be seen to function as extensions of the original given personas.
模型
Baseline 就是 Transformer Encoder-Decoders,用个预训练语言模型即可,本文使用的是 BlenderBot 的 BST 2.7B 参数模型。
另一种更好的方式是使用 retrieval augmentation,比如 RAG 和 FiD-RAG模型。
此外,可以用摘要的方式更好地使用上下文:
- there is a lot of context to store, and hence retrieve from
- no processing has been done on that content, so the reading, retrieving and combining operations required to generate an answer leave a lot of work for the model to do.
文章使用之前标注的 Conversation Summaries 训练了一个 encoder-decoder abstractive summarizer来做 Summarization Memory-Augmentation。
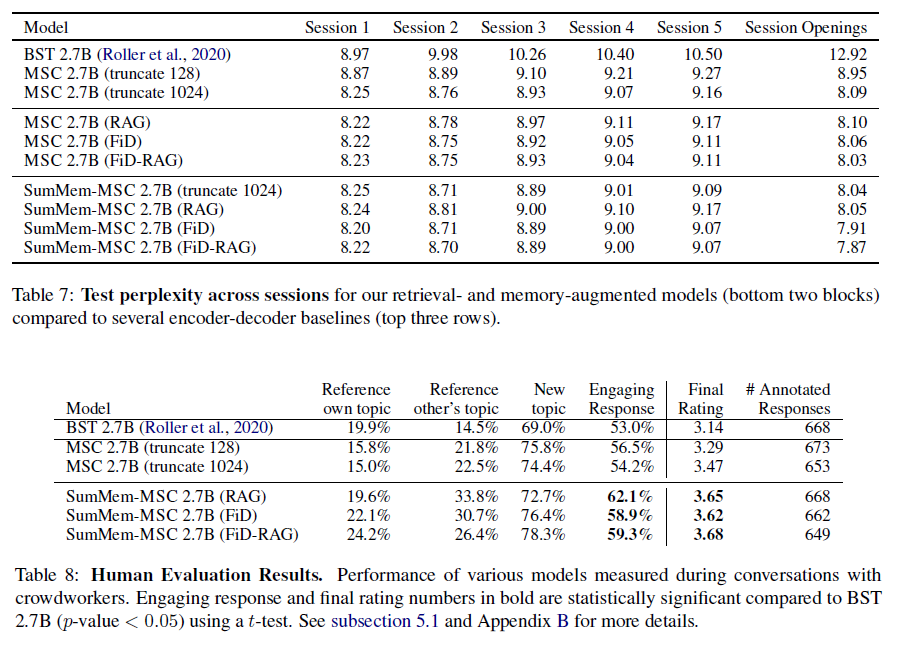
实验效果如下,SumMem-MSC (FiD-RAG) 的效果最佳,在PPL和Human evaluation中的表现都更好:
总结
本文提出了长期开放域对话的问题,构建和发布了对应的
Multi-Session Chat 数据集,指出传统的 encoder-decoder
模型在此问题上的表现一般。实验证明,使用检索加强的方式,并使用摘要式上下文,可以很好地建模长期开放域对话。
文章最大的贡献应该是斥资构建了一个人工编写的数据集,长期对话并不是个新问题,模型也是使用现成的模型,没有创新性。
最后附一个数据集对话实例:
