NLP Prompt技术简介
Prompt是当下最热的NLP技术之一,本文通过 what, why 和 how 三个问题对它进行介绍。力求简明扼要,不是完整综述,更多细节,可参考更多论文原文。
Prompt是什么
首先来看什么是Prompt,没有找到权威定义,引用一些论文中的描述来说明什么是Prompt。
Users prepend a natural language task instruction and a few examples to the task input; then generate the output from the LM. This approach is known as in-context learning or prompting.
By: # Prefix-Tuning: Optimizing Continuous Prompts for Generation
简单来说,用户用一段任务描述和少量示例作为输入,然后用语言模型生成输出。这种方法就叫做in-context learning或prompting。Prompting也有另一种偏概率的解释:
Prompting is the approach of adding extra information for the model to condition on during its generation of Y .
By: # The Power of Scale for Parameter-Efficient Prompt Tuning
举个PET中的示例来说明什么是Prompt,假设我们要对一句话Best pizza ever!进行情感分类,可以在这句话后面加上一句模板:
Best pizza ever! It was ___.那么基于前面这句话填空的结果,模型预测为great的概率要远高于bad。因此我们可以通过构造合适的Prompt把情感分类问题变成完形填空问题,从而可以很好地利用预训练模型本身的潜力。
关于Prompt为什么好使,PET中有如下解释:
This illustrates that solving a task from only a few examples becomes much easier when we also have a task description, i.e., a textual explanation that helps us understand what the task is about.
Pretrain-finetune与Prompt-tuning的主要区别在于前者通过finetune让模型更好地适应下游任务,而后者则是通过设计Prompt来挖掘预训练模型本身的潜能。
为什么用Prompt
现在的NLP模型都很大,下游任务也繁多,finetune的范式就需要对每个任务都使用一个特定的模型拷贝。解决这个问题的直观方案是轻量的finetune,即在finetune阶段只调整少量的参数,而保持大多数参数不可训练。
将这种做法做到极致就是Prompt,比如GPT3可以不经过finetune而完成多种下游任务。也就是说,Prompt是一种很好的Few-shot learning甚至Zero-shot learning的方法。
Prompt重在挖掘预训练模型本身的潜力,甚至在某些情况下可以超越之前finetune的SOTA。
此外,因为Prompt对原模型的改动较小甚至不改,可以比较轻量地实现个性化而无需每用户一个大模型,serving开销显著变小。
怎么用Prompt
那下面的问题就在于,如何找到合适的Prompt?
此处将不同方案使用的模板列出,保持与原文一致的符号标记。
离散式模板
制定离散式Prompt的模板需要对模型本身有一定的理解,而且考虑到模型的不可解释性,就需要对Prompt的模板进行不断的试验,所谓“有多少人工就有多少智能”。
这种离散型模板也叫做hard prompt。
PET
# Exploiting Cloze Questions for Few Shot Text Classification and Natural Language Inference
PET通过构造自然语言式的模板,将一些文本任务转换成完形填空任务,比如第一节中的示例。
PET提供的模板花样比较多,不同任务对应不同的人工设计模板,大概长这个样子,其中a和b是输入文本:
It was ___. a
a. All in all, it was ___.
a ( ___ ) b
[ Category: ___ ] a bAutoPrompt
# AutoPrompt: Eliciting Knowledge from Language Models with Automatically Generated Prompts
AutoPrompt本质上也是一种自然语言式的模板,但它的模板看起来通用性更强,分为三部分,原句,Trigger Tokens [T]和预测Token [P]。
{sentence} [T][T] . . [T] [P].在标注数据集上,通过最大化预测准确率的方法自动搜索最优的Trigger Tokens [T]。此方法的直觉是,通过标注数据搜索与任务相关的模板关键词知识 (auto knowledge probing)。并在之后通过这些寻找到的Trigger Token作为自动模板,将模型泛化。
连续向量模板
寻找像自然语言一样的离散模板比较困难,于是有一些后续改进的工作。实际上,Prompt不一定是离散的,甚至不一定是自然语言,Prompt可以是一个embedding,可以通过训练在连续向量空间中搜索得出。
这种连续型模板也叫做soft prompt。
Prefix-Tuning
# Prefix-Tuning: Optimizing Continuous Prompts for Generation
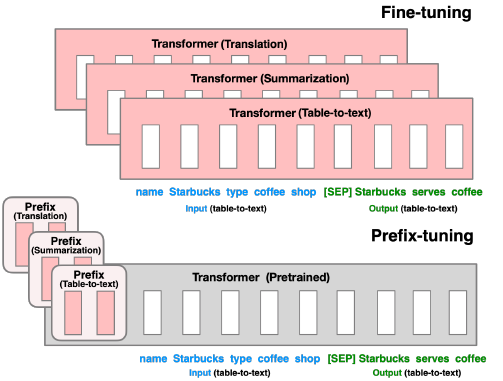
Prefix-Tuning固定了语言模型本身的参数,只在每层加入一个Prefix Vector,也就是一个Prefix Matrix,仅训练这一小部分连续并任务相关的参数即可提升一些文本生成任务(NLG)的效果。把这些virtual token对应的向量看做prompt。Prefix-Tuning的模板形式:
Autoregressive Model: [T] x y
Encoder-Decoder Model: [T] x [T'] y其中x是输入的source,y是target。
同时,在实验中也有一个关于表达力的比较,看起来连续的向量比离散的关键词模板更富有表达力 (expressive):
discrete prompting < embedding-only ablation < prefix-tuning
P-Tuning
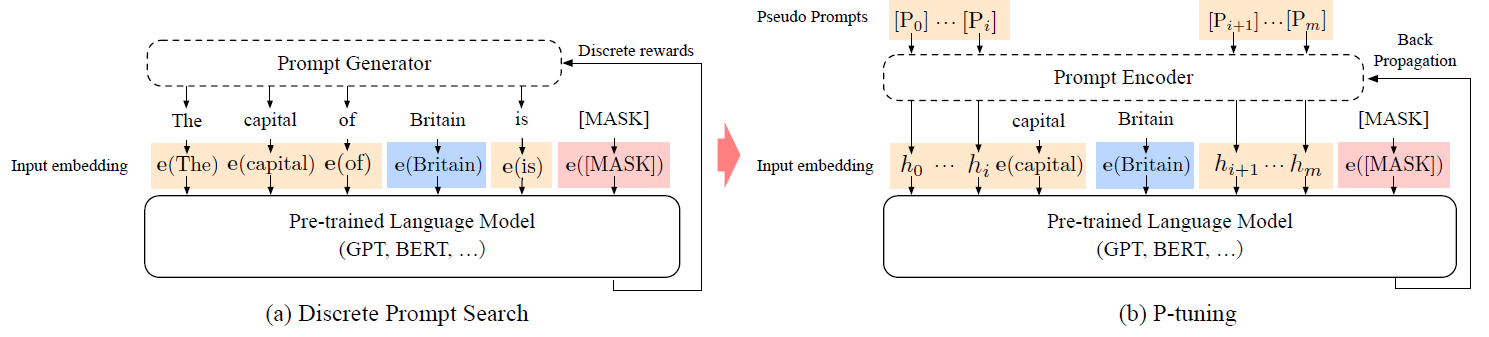
P-Tuning的思路其实与Prefix-Tuning非常类似,都是希望通过少量标注数据学习一个连续向量模板,主要区别在于P-Tuning更关注NLU。
To automatically search prompts in the continuous space to bridge the gap between GPTs and NLU applications.
即P-Tuning通过自动搜索Prompt,让GPT这样的autoregressive model很好地完成NLU的任务。具体地来看下P-Tuning的模板形式:
[h(0)]...[h(i)]; e(x); [h(i+1)]...[h(m)]; e(y)其中,h(i)就是Prompt,e是embedding函数,x是sentence tokens,y是target。
还有个值得注意的点,Prefix-Tuning和P-Tuning在训练搜索模板时都采用了reparametrize的方法,因为它们遇到了优化不稳定的问题:
Empirically, directly updating the P parameters leads to unstable optimization and a slight drop in performance.
By: Prefix-Tuning
In the P-tuning we propose to also model the h(i) as a sequence using a prompt encoder consists of a very lite neural network that can solve the discreteness and association problems.
By: P-Tuning
说句题外话,之前有许多关于BERT适合NLU而GPT适合NLG的说法和对应的解释,这篇论文是否推翻了这些推断? :-)
Prompt Tuning
# The Power of Scale for Parameter-Efficient Prompt Tuning
本文发表在EMNLP 2021,是对之前一些工作的总结和改进。与Prefix-Tuning的主要区别在于,前者对模型的每层都加入了prefix vector,而本文提出的方案,仅仅在输入层这一层加入一些额外的embedding,因而更加parameter-efficient。虽然进行tuning的参数更少,但模型效果不错,并且文中有一些有意思的insights:
如何初始化prompt vector?
Conceptually, our soft-prompt modulates the frozen network’s behavior in the same way as text preceding the input, so it follows that a word-like representation might serve as a good initialization spot.
从直观上说,因为这种加prompt的方式类似于在输入层添加一些token,因此将这些prompt vector初始化成词表中的word embedding vector相比于随机初始化是更好的做法。
prompt的长度选择?
简单来说,越短越好,越长训练的成本越高。后面的实验证明20就差不多,更长的prompt对性能提升效果有限。
The parameter cost of our method is EP, where E is the token embedding dimension and P is the prompt length. The shorter the prompt, the fewer new parameters must be tuned, so we aim to find a minimal length that still performs well.
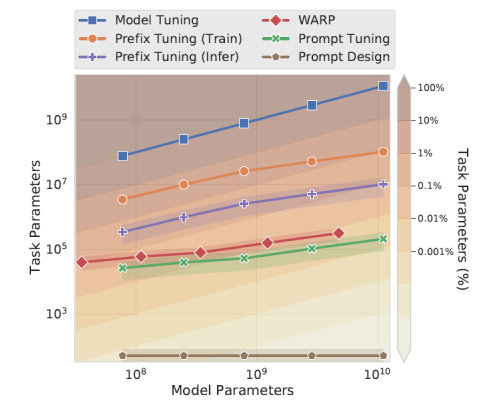
从上面模型参数数量对比来看,Prompt Tuning比Prefix Tuning更胜一筹,个人觉得本文最大的贡献在于发现了只要初始化方法得当,仅在输入层加入少量参数做prompt tuning就够了。
本质上,连续prompt模板就是在原有LM上增加了少量参数,并通过小样本仅学习这些参数调优取得更好性能的方法。 与直接添加参数相比,这些参数具有模板的形式(虽然不是自然语言形式),所以取得了更好的效果。
总结
Prompt无疑是当下最火的NLP技术之一,大家通过各种不同的Prompt方式来挖掘预训练模型本身的潜能。通过构造或查找合适的模板,prompt已经在各种不同的NLP任务上大放异彩。
同时,Prompt也存在一些问题,比如最优模板的构建和查找,模板的稳定性等:
Most of the work takes manually-designed prompts—prompt engineering is non-trivial since a small perturbation can significantly affect the model’s performance, and creating a perfect prompt requires both understanding of LMs' inner workings and trial-and-error.
By: # Prompting: Better Ways of Using Language Models for NLP Tasks
总之,作为一种对预训练模型知识提取和挖掘的方法,Prompt瑕不掩瑜,相信之后会有更多Prompt的工作推进NLP的发展。