大模型分布式训练的并行策略
随着神经网络模型规模的不断增大,对硬件的显存和算力提出了新的要求。首先模型参数过多,导致单机内存放不下,即使能放得下,算力也跟不上。同时,硬件算力的增长远远比不上模型增长的速度,单机训练变得不再可行,需要并行化分布式训练加速。比如Megatron-Turing NLG有 530B 的参数,训练需要超过 10T 的内存来存储权重、梯度和状态。
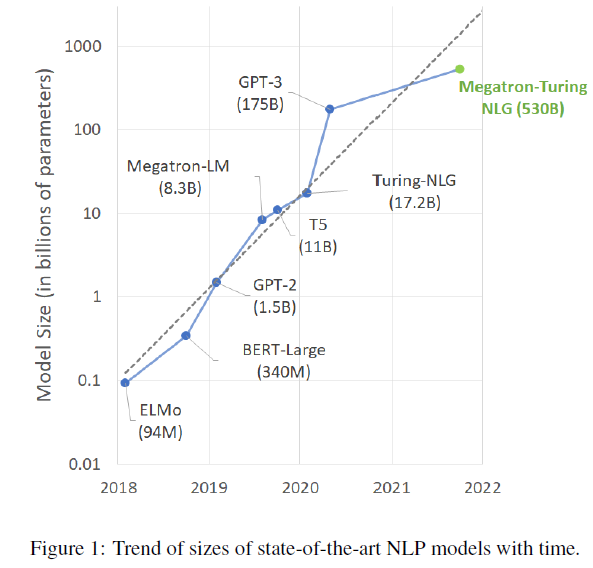
同时,模型是一个有机的整体,简单增加机器数量并不能提升算力,需要有并行策略和通信设计,才能实现高效的并行训练。本文简要介绍目前主流的几种并行策略:数据并行,张量并行,流水线并行和混合并行。
数据并行 (Data Parallelism)
Data parallelism is a ubiquitous technique in deep learning in which each input batch of training data is divided among the data-parallel workers.
示意图来自 ColossalAI :
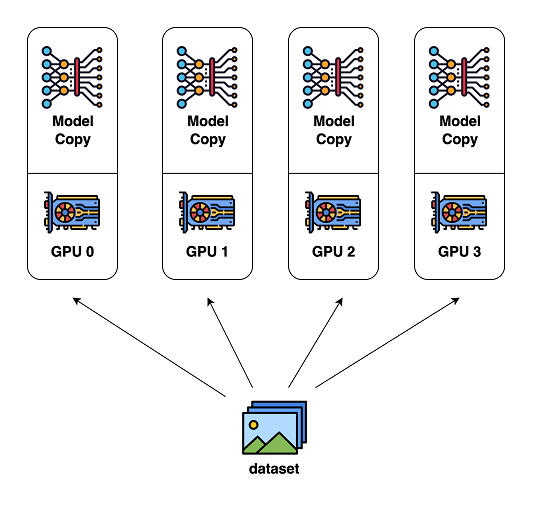
数据并行原理很简单,所有设备都保存完整的模型参数,仅把数据集切分成N份,在更新参数时,将所有设备的梯度进行聚合即可。数据并行实现简单,是首选的并行方案,缺点是存储效率不高,模型参数被冗余存储N次。当模型比较大时,通信开销很大,甚至会影响计算效率。所以数据并行适用于模型较小而数据量较大的情况 (不过根据 DPC 的结论,这样的情况不应存在)。
张量并行 (Tensor Parallelism)
Tensor model parallelism is a broad class of model parallelism techniques that partitions the individual layers of the model across workers.
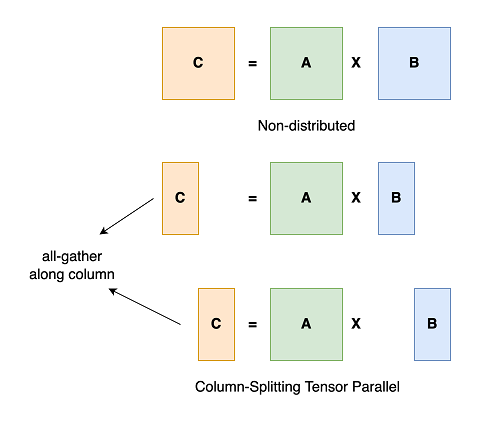
张量并行与流水线并行都属于模型并行,区别在于对模型参数的切分“方向”不同:张量并行把模型的每层进行切分 (intra-layer),而流水线并行则按层进行切分 (inter-layer) 并在不同设备处理。张量并行可以降低单机内存使用到模型大小的1/N,存储效率较高,但在每次前向和后向计算时会引入额外的通信开销。
示意图来自 ColossalAI :
流水线并行 (Pipeline Parallelism)
Pipeline model parallelism divides the layers of the model into stages that can be processed in parallel.
流水线并行按模型的不同层进行切分并在不同设备处理。模型越深,流水线并行越能降低内存使用,但是每层的计算量不变。由于通信只发生在阶段的边界,流水线并行也是三种并行策略中通信开销最小的一个。不过流水线并行并不能无限扩展,它的并行度受到模型深度的限制。此外,不同阶段的计算量需要比较均衡,否则并行效率会降低。
示意图来自 NVIDIA :
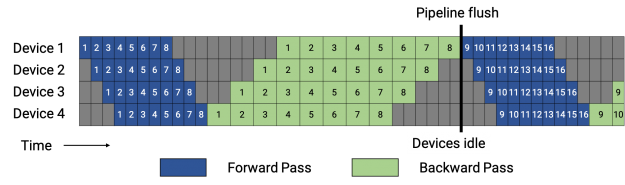
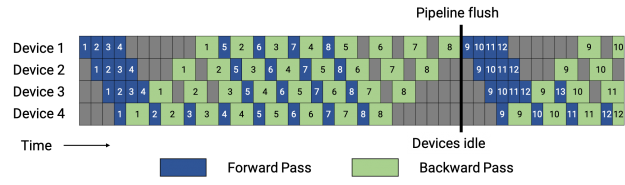
流水线并行原理与计算机体系结构中的指令并行非常类似,上图中把每个batch切分成了8个microbatch并在四个设备上并行计算。图中灰色的区域称为气泡 (bubble),即设备空闲的时间。流水线并行的设计就导致不可能达到100%的GPU利用率,因此,有不少后续工作如 PipeDream-Flush 对GPU使用率进行优化,就像这样:
3D并行 (3D Parallelism)
3D并行,或者混合并行 (Hybrid Parallelism),则是将以上三种策略结合起来使用,达到同时提升存储和计算效率的目的。Megatron-Turing NLG 就是先将 Transformer block 使用流水线和张量 2D 并行,然后再加上数据并行,将训练扩展到更多的GPU。
For example, each 530 billion parameter model replica spans 280 NVIDIA A100 GPUs, with 8-way tensor-slicing within a node and 35-way pipeline parallelism across nodes. We then use data parallelism to scale out further to thousands of GPUs.