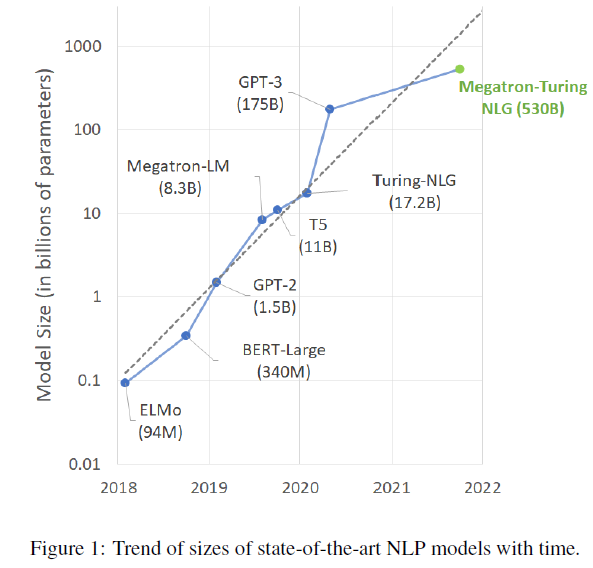
最近ChatGPT火爆出圈,一众朋友发来各种网红文问我怎么看。ChatGPT的模型与InstructGPT一样,只是数据收集方式有区别。而InstructGPT的提出已差不多有一年了,只不过最近才引起大家的注意。其实,今年已经有不少工作是延续InstructGPT对提升模型效果的,如
Diamonte
,参考了human feedback的思路,但将RL的方案替换成了额外的loss fuction项;
WeLM
,参考了人工编写prompt模板训练大规模语言模型。
话不多说,来看看原始的InstructGPT是如何打败大模型的。原始Paper很长,有68页,而事实上核心思想并不复杂。(PS: 现在训练个大模型要不写个50页以上的Paper,都对不起咱烧的那钱!)
Training language models to follow instructions with human feedback
Aligning Language Models to Follow Instructions
InstructGPT指出,模型并非越大越好:
Making language models bigger does not inherently make them better at following a user’s intent. For example, large language models can generate outputs that are untruthful, toxic, or simply not helpful to the user.
所以InstrcutGPT希望通过人工反馈让语言模型与用户意图更加align:
We show an avenue for aligning language models with user intent on a wide range of tasks by fine-tuning with human feedback.
最终训练出来1.3B的InstructGPT模型,人工评测比175B的GPT-3要更好:
In human evaluations on our prompt distribution, outputs from the 1.3B parameter InstructGPT model are preferred to outputs from the 175B GPT-3, despite having 100x fewer parameters.