InstructGPT/ChatGPT 简读
最近ChatGPT火爆出圈,一众朋友发来各种网红文问我怎么看。ChatGPT的模型与InstructGPT一样,只是数据收集方式有区别。而InstructGPT的提出已差不多有一年了,只不过最近才引起大家的注意。其实,今年已经有不少工作是延续InstructGPT对提升模型效果的,如 Diamonte,参考了human feedback的思路,但将RL的方案替换成了额外的loss fuction项;WeLM,参考了人工编写prompt模板训练大规模语言模型。
话不多说,来看看原始的InstructGPT是如何打败大模型的。原始Paper很长,有68页,而事实上核心思想并不复杂。(PS: 现在训练个大模型要不写个50页以上的Paper,都对不起咱烧的那钱!)
Training language models to follow instructions with human feedback
Aligning Language Models to Follow Instructions
InstructGPT指出,模型并非越大越好:
Making language models bigger does not inherently make them better at following a user’s intent. For example, large language models can generate outputs that are untruthful, toxic, or simply not helpful to the user.
所以InstrcutGPT希望通过人工反馈让语言模型与用户意图更加align:
We show an avenue for aligning language models with user intent on a wide range of tasks by fine-tuning with human feedback.
最终训练出来1.3B的InstructGPT模型,人工评测比175B的GPT-3要更好:
In human evaluations on our prompt distribution, outputs from the 1.3B parameter InstructGPT model are preferred to outputs from the 175B GPT-3, despite having 100x fewer parameters.
训练方法
具体地来看InstructGPT的核心思想,此时必须祭出此图:

训练过程分三步:
- 收集demonstration data,finetune GPT-3 (Supervised FineTune, SFT): 从prompt库中Sample一个prompt,labeler人工编写对应的输出,然后用此数据finetune GPT-3。
- 收集comparison data,训练奖励模型 (Reward Model, RM): 采样一个prompt和多个模型输出结果,labeler对这些模型结果按质量排序,并用此数据训练RM。
- 使用RM作为强化学习的优化目标,利用PPO算法微调SFT模型: 采样一个新的prompt,PPO生成一个模型输出,用RM对其打分 (scalar reward),然后更新模型。
其中后两步可不断迭代,直到训练出一个足够优的模型。
数据集
Our prompt dataset consists primarily of text prompts submitted to the OpenAI API, specifically those using an earlier version of the InstructGPT models (trained via supervised learning on a subset of our demonstration data) on the Playground interface.
prompt数据集是从早期使用InstructGPT的用户处收集来的,这个playground现在长这样:
prompt dataset是labeler手写的,包含如下三类:
- Plain: 可以是任意task,保证任务足够的多样性。
- Few-shot: 以一段描述指南开头,和多个query/response对构成的任务。
- User-based: OpenAI API有不同类别的用例,labeler根据这些用例写prompt。
根据这些prompt,构造出三个数据集:SFT/RM/PPO,其中一些统计参数和用例的示例如下:
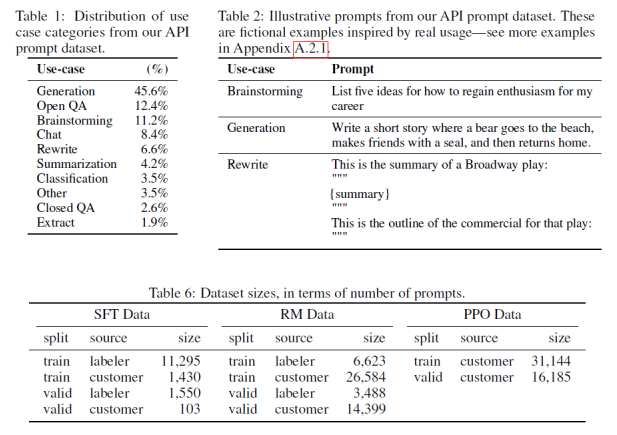
从数据统计上来看,大部分用例都是生成式的任务,而非分类和问答。标注数据量在万级别,不算小。数据集中96%都是英文,所以英文效果最好毋庸置疑。
论文中还提到了一个有意思的点:
Our aim was to select a group of labelers who were sensitive to the preferences of different demographic groups, and who were good at identifying outputs that were potentially harmful. Thus, we conducted a screening test designed to measure labeler performance on these axes.
在业界收集过人工标注数据集的应该都清楚,获取与预期一致的数据集有多困难。这里通过筛选更合适的labeler的方式,也是获取高质量数据集重要的一步。
模型
训练方法在前面训练方法已经说明,这里涉及一些模型训练的细节。
- Supervised fine-tuning (SFT): 由GPT-3开始,用对应的SFT数据集训练16个epoch。但validation loss在第1个epoch之后就出现了overfit (我认为是数据量相比模型大小太小的原因,1个epoch足矣)。继续训练至16个epoch的原因是因为有助于RM的打分训练,及人工标注结果更优。
- Reward modeling (RM): 基于SFT,去掉最后一个非嵌入层,得到RM。训练以一个prompt和多个response作为输入,scalar为输出。最终训练了一个6B的RM,原因在于175B的 RM 训练不稳定,在后续的RL训练中不可用。这也是大模型训练中的痛点:训练不收敛或不稳定。 还有一个trick,给定K个response,共有C(k,2)个对比组合,文中将它们放在了同一个batch中训练,将C(k,2)次forward pass减少为1次,同时避免了overfit的问题。
- Reinforcement learning (RL): 使用PPO算法和RM对SFT进行RL训练。这也是模型的创新点之一,在对话模型中如何建模reward是个难点,本文采用了训练一个reward模型并不断迭代的方案,收效不错。
效果评估
本文既然解决的是"aligned"的问题,那么什么是"align"?这个定义一直都不明确:
The definition of alignment has historically been a vague and confusing topic, with various competing proposals.
本文认为align就是模型行为与用户意图一致:
Our aim is to train models that act in accordance with user intentions. More practically, for the purpose of our language tasks, we use a framework similar to Askell et al. (2021), who define models to be aligned if they are helpful, honest, and harmless.
总结
让模型与用户意图align (通过人工标注数据),比单纯追求大模型要有效率得多。不必过度迷信大力出奇迹。本文这些标注数据使用了40人的标注团队,也不少。
Our results show that RLHF is very effective at making language models more helpful to users, more so than a 100x model size increase. This suggests that right now increasing investments in alignment of existing language models is more cost-effective than training larger models.
InstructGPT完成align的方法是人工撰写prompt数据集+强化学习,通过人工标注让模型更好地区别回复的好坏。模型本身并没有突破性的进展 (如果有,也不会是在提出一年之后才突然出圈爆火),出色的效果主要依赖于精细的工程化调优和大量数据工程。个人以为ChatGPT/InstructGPT在训练过程中还是有非常多细节上的优化和trick,只不过不会写在Paper上或写出来看着也比较trivial而已。但可能正是这些trick,才是国内大模型与顶尖大模型之间真正的差距。
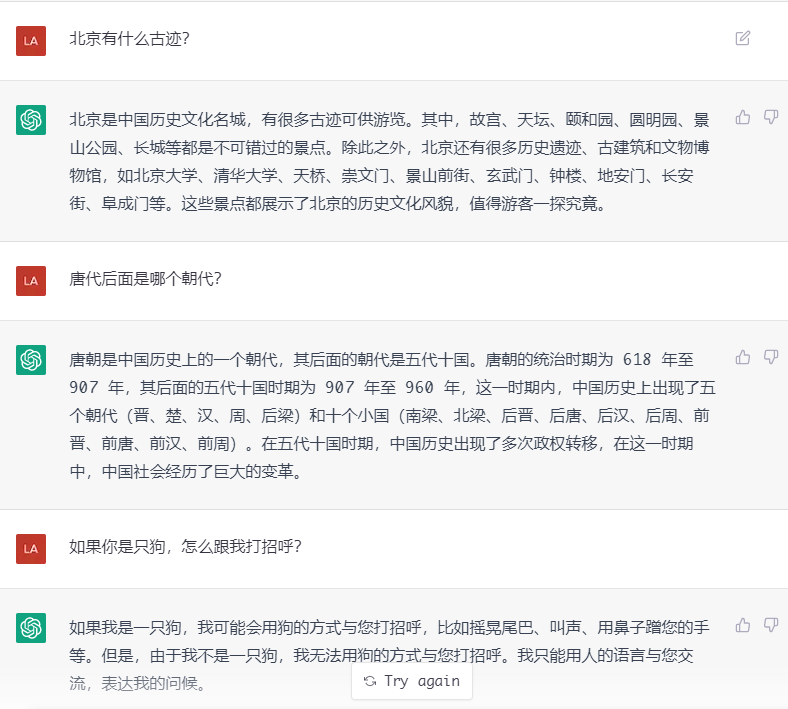
最后,我们来欣赏一下ChatGPT的惊艳效果,网上很多,就不过度炫技了 (预告:后续会更新一些它比较蠢的例子 :-) ):
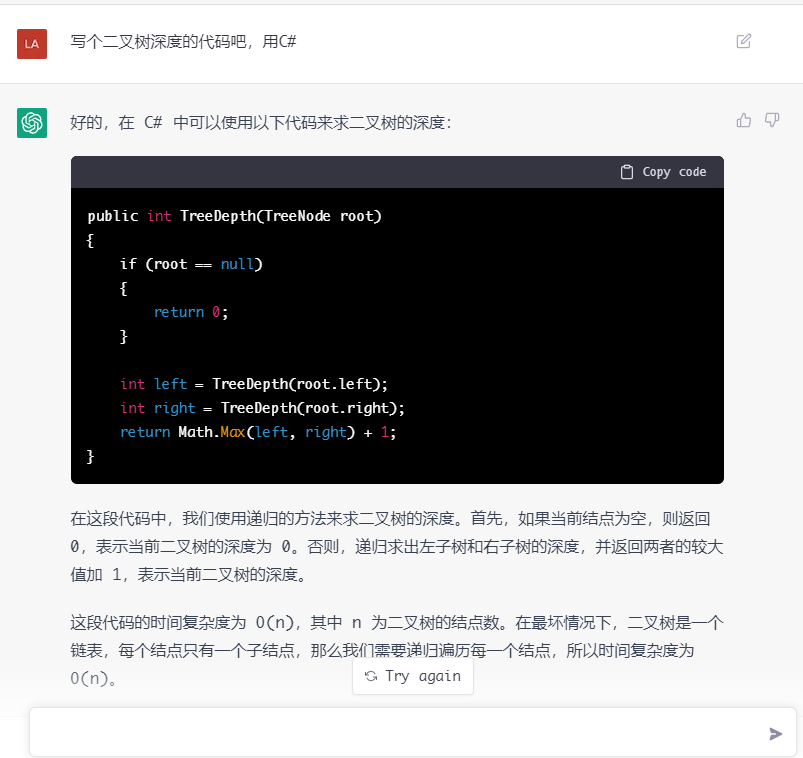
上面这二叉树深度的代码写得还真clean~
ChatGPT懂的语言还挺多:
![]()
QA问答: