贵州4月下旬自驾游记
好久没出去看大好河山,五一前休假去贵州自驾游,云贵川算是都打了卡。按照惯例,还是提前简单做下攻略,本想将行程设置宽松些,后来发现贵州的大部分景点门票预订(进景区时间)都要精确到小时,才不得不把行程提前细化。
贵州的主要景点也比较分散,不过都是以省会贵阳为中心放射状排列,本次自驾主要以黔东为主。之前找到一张不错的贵州景点分布图,记不清出处了:
好久没出去看大好河山,五一前休假去贵州自驾游,云贵川算是都打了卡。按照惯例,还是提前简单做下攻略,本想将行程设置宽松些,后来发现贵州的大部分景点门票预订(进景区时间)都要精确到小时,才不得不把行程提前细化。
贵州的主要景点也比较分散,不过都是以省会贵阳为中心放射状排列,本次自驾主要以黔东为主。之前找到一张不错的贵州景点分布图,记不清出处了:
3月22日,NVIDIA的CEO黄仁勋与OpenAI的创始人Ilya Sutskever进行了围炉对谈,通过视频可以更好地了解OpenAI是如何走到今天,又是如何理解ChatGPT和GPT-4这些大模型的。不过毕竟是非正式访谈,思路和观点略有发散,本文提取访谈中一些有意思的观点供参考。
BTW,网上的中文完整字幕翻译对某些观点的翻译解读有误,建议看原视频。
# AI Opener: OpenAI’s Sutskever in Conversation With Jensen Huang
戴了十几年的力洛克,一年前开始走时不准,最近每天能慢上一分钟,手动上弦似乎也有些问题,总是上不满弦,怀疑与之前疫情在家总手动上弦有关系 (最初怀疑发条断了)。
距上次保养已经5年有余,天梭官方授权的店保养一次 (所谓完全服务) 约一千块,而买块新的ETA-2824-2机芯也就差不多这个价,所以再去保养显得非常不划算。老爷子年轻时玩表修表,有此家学,再加上网上有许多机芯拆解洗油点油视频,看起来也不甚困难,跃跃欲试,决定自行保养维护。
前后历时一个月才保养完毕,趟坑无数。现在看来,动手时显然低估了保养洗油的难度,加之中间遇到的诸多难题,本想从玩表的过程获取些操作的成就感,不想却收获了诸多挫败感。修完后才感叹,授权店收一千块算是良心价了 :-) 。好在最终问题完美解决,记录下保养过程。
语言模型越来越大,但更大的模型并没有显示出更强的计算和推理能力。去年Google提出了Chain-of-Thought (CoT) 的方案,通过chain-of-thought提示,让模型逐步推断,使大模型的推理能力显著提升。本文来看一下chain-of-thought的原理。
Chain-of-Thought Prompting Elicits Reasoning in Large Language Models
大规模语言模型的春风已经吹遍大地,大家都惊叹于大模型出色的对话能力,但是在训练大模型时遇到的训练不稳定问题(training instabilities),可能关注的人并不太多。所谓量变引起质变,模型每大一个量级,就可能会出现一些意想不到的问题,比如莫名其妙的训练崩溃。当然,也有好的方面,在模型有一定规模后,是否有可能表现出一些弱智能,也很难说。
言归正传,今天聊聊在训练10B以上模型时遇到的训练不稳定现象,问题原因及当前的解法。
ChatGPT的大火让Google也坐不住了,许多人认为这一波Google已落后一个身位。坊间甚至传言创始人谢尔盖・布林都已“躬身入局”,亲自写代码了。上面的说法可以当八卦看来一乐,不过昨天微软官宣Bing和Edge浏览器要集成ChatGPT时,Google也不甘示弱,表示也要上线大模型Bard
(这个名字倒也颇具浪漫主义气质:吟游诗人)。
随着神经网络模型规模的不断增大,对硬件的显存和算力提出了新的要求。首先模型参数过多,导致单机内存放不下,即使能放得下,算力也跟不上。同时,硬件算力的增长远远比不上模型增长的速度,单机训练变得不再可行,需要并行化分布式训练加速。比如Megatron-Turing NLG有
530B 的参数,训练需要超过 10T 的内存来存储权重、梯度和状态。
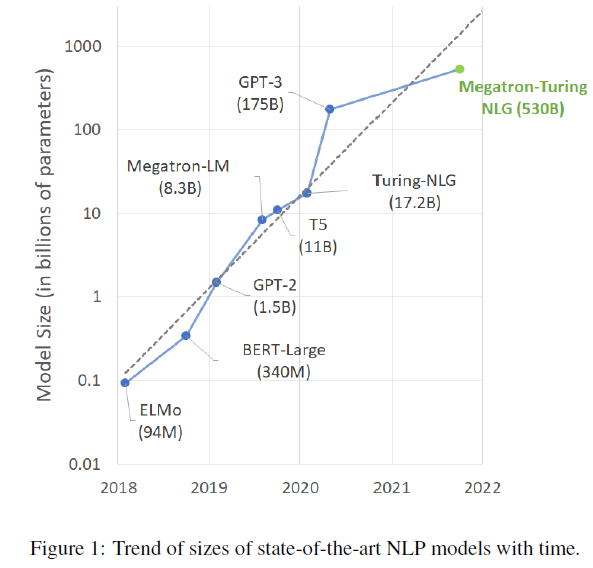
同时,模型是一个有机的整体,简单增加机器数量并不能提升算力,需要有并行策略和通信设计,才能实现高效的并行训练。本文简要介绍目前主流的几种并行策略:数据并行,张量并行,流水线并行和混合并行。
近来被人们玩坏的ChatGPT推出了收费订阅ChatGPT Plus,每月20刀,提供更好的可用性,更快的回复时间,和提前试用新功能的权益。
这个订阅目前仅对美国地区开放,先从之前登记的waitlist上邀请试用,后续会开放更多国家和地区。
好消息是免费版继续可用,推出收费版后可以更好地服务于更多的免费用户。
Recently I upgrade NexT theme to v8.14.1. The related post plugin
hexo-related-popular-posts had been replaced by
hexo-related-posts, which generates related posts by tf-idf
algorithm. However, the compute cost is a little bit heavy if you have
many posts. A good trade-off is enable this feature only for production
environment. The plugin hexo-related-posts
already takes this into account and use enable_env_name to
disable its execution. Unfortunately, the document has typo so I takes
some time to fix it.
So how to set environment variable in Hexo?
Short
Answer:$ hexo <command> --<env_key> env_value。
The following secitons will illustrate how to enable related post on production.
最近升级NexT主题到最新版v8.14.1,相关文章功能从v8.10开始由hexo-related-popular-posts替换成了hexo-related-posts,后者是用tf-idf算法对文章全文进行相似度计算而得相关文章,比hexo-related-popular-posts要精准和先进一些,不过副作用是计算量变大,在文章数较多的情况下运行会比较慢,这样在写完文章后用hexo s进行本地调试效率就变低了,每次文章修改都要重新计算一遍tf-idf。好在
hexo-related-posts
考虑到了此问题,可以通过设置enable_env_name变量,只在特定环境(如生产环境)中才开启此功能。不过文档略有些问题,费了一番周折才设置环境变量成功。
短答案:$ hexo <command> --<env_key> env_value。
长答案:本文介绍了如何使用环境变量仅在生产环境开启相关文章功能。