漫谈 Knowledge Grounded Conversation
Knowledge Grounded Conversation (KGC),就是基于知识的对话生成,与不使用知识的对话生成相比,生成的回复更有信息量,可更好地与用户互动。
本文不是KGC的综述,所谓漫谈,则是比较随性地聊聊这个方向的代表工作,顺带简单梳理其发展脉络。
Knowledge Groudned Conversation 简介
KGC这个问题约在2018年底被Facebook提出,并同时发布了一个数据集 Wizard of Wikipedia (WoW) 与模型 Transformer Memory Network (TMN)。
[ICLR2019] [WoW] Wizard of Wikipedia: Knowledge-Powered Conversational Agents
在开放域对话中,恰当地使用knowledge是个必要的功能,但这个问题却没被很好地解决。seq2seq模型只能通过参数记忆输入到输出的映射,却不能很好地将knowledge作为上下文建模。所以WoW提出了一个有监督学习任务,可以让模型基于相关knowledge生成回复,也就是 Knowledge Grounded Conversation。
KGC Workflow
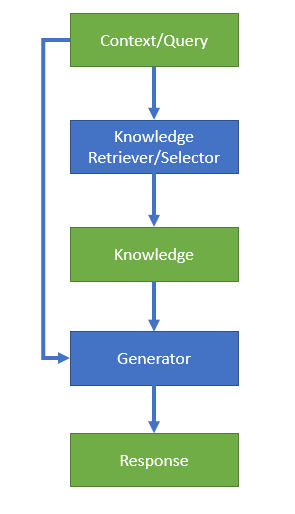
如上图所示,KGC的输入是Context/Query,通过 Knowledge
Selector 选出最优 Knowledge ,然后将
<Context/Query, Knowledge> 作为输入, Response
Generator 生成最终
Response。所以KGC模型主要由两部分构成:Knowledge
Selection 和 Response Generation。
Wizard of Wikipedia 数据集
WoW是KGC方向的经典数据集,几乎所有KGC相关的后续工作都会使用此数据集进行实验验证。对话由一个 Apprentice 和一个 Wizard 完成:
- Apprentice: 扮演的角色是一个好奇的学徒,很想聊天。双方的目标是针对一个选定的话题进行深入的聊天,同时保证整个会话比较吸引人和有趣。这种对话有别于普通的chitchat,它更强调使用knowledge进行聊天。
- Wizard: 扮演的角色是遇到了另一个好奇的人,同时自己也很希望与之深入交谈。在交流的过程中,Wizard可以借助一个IR系统从Wikipedia中检索相关的段落展开聊天,而这个段落对Apprentice是不可见的。Wizard在每轮对话前先阅读这个段落,然后基于这个知识与Apprentice进行对话,保证对话与此段落相关并且回复比较引人入胜。
对话开始时一方先选择一个话题开始,Apprentice提出问题后,Wizard这边会通过IR系统显示出相关的knowledge,他可以选择一个相关的knowledge进行对话,或者都不选进行回复。整个会话至少要持续4~5轮,最终构造出整个数据集。数据集的一些统计数据:
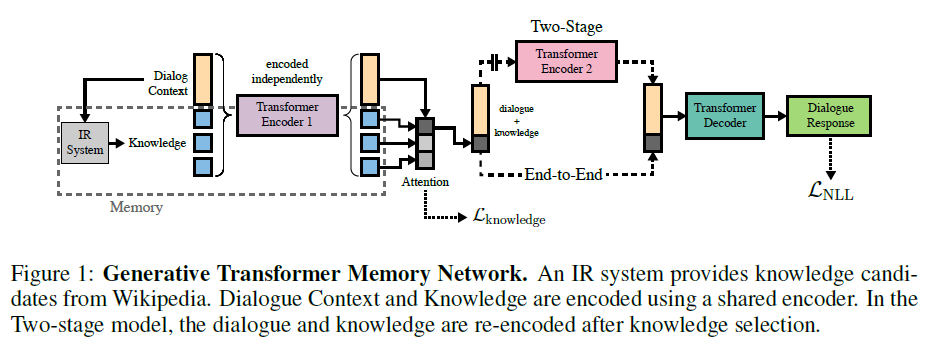
Transformer Memory Network
模型结构很直观,把context与knowledge分别编码,再输入decoder生成最终的回复。这里的 TMN 也是许多后续工作的baseline。
Knowledge Selection
很多工作都指出Knowledge Selection的准确性对于端到端性能的影响非常明显,即只要knowledge选择的准确性越高,模型效果越好。这一点也不难理解,很多选出来的knowledge甚至可以直接作为query的回复,后一步response generation仅需要对选出的knowledge做些许改写即可。因此,有不少工作都聚焦在knowledge selection部分。
Knowledge
Selection是个one-to-many的问题,即给定了context之后,可能有多个候选的knowledge都是不错的选择,比如像WoW数据集,就是人为地从N个选择中挑一个,再根据
<context, selected knowledge>
进行最终回复生成。这就存在一个问题:数据集中所谓的 golden
knowledge,到底是不是真正的
golden?如果看看数据集会发现,很多情况下,其他未被选中的knowledge可能也是不错的选择。由此引发的问题就是:如果不看答案
(response),即使是真人也很难选出golden
knowledge,因为从context并不能提供足够多的信息来辅助选择。
下面就具体聊聊这些关于knowledge selection的工作。
PostKS
[IJCAI2019] PostKS Learning to Select Knowledge for Response Generation in Dialog Systems
PostKS 首先提出了一种提升Knowledge Selection效果的方案,思路很直观,用后验分布逼近先验分布,也就是说,用response来指导选择knoweldge,选择knowledge中与response比较接近的那个。
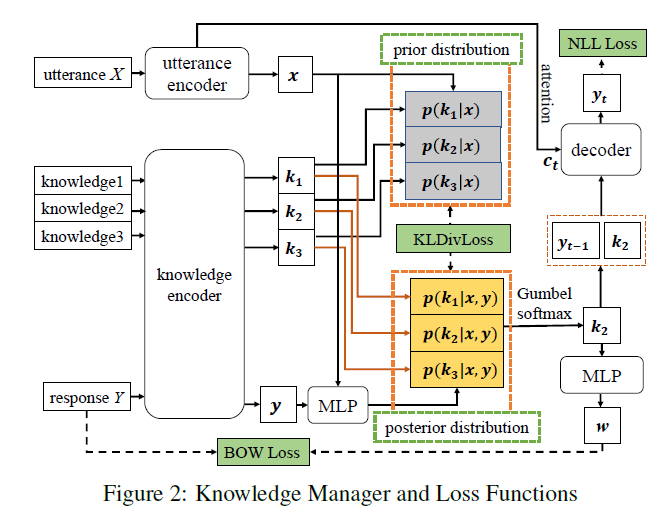
从上图可以看出,x是输入的句子(或者说上下文), y是生成的response,那么先验分布是 \(p(k|x)\),后验分布是 \(p(k |x, y)\),训练方案就是使用KL散度来最小化损失函数,达到后验逼近先验的目的,从而可以根据context来预测哪个是 golden knowledge。
SKT
[ICLR2020] SKT Sequential Latent Knowledge Selection for Knowledge-Grounded Dialogue
SKT 提出了另一种思路进行knowledge selection。论文首先做了一个实验,测试了看和不看response两种情况下,knowledge selection的准确率:

结果很有意思,对真人来说,不看response选对knowledge的准确率只有17.1%,而在看response的情况下,高达83.7%。所以论文的动机就很明确了:
Our sequential model can keep track of prior and posterior distribution over knowledge, which are sequentially updated considering the responses in previous turns, and thus we can better predict the knowledge by sampling from the posterior.
模型叫做 sequential knowledge transformer,与之前工作的区别在于:
First, we regard the knowledge selection as a sequential decision process instead of a single-step decision process. Second, due to the diversity of knowledge selection in dialogue, we model it as latent variables.
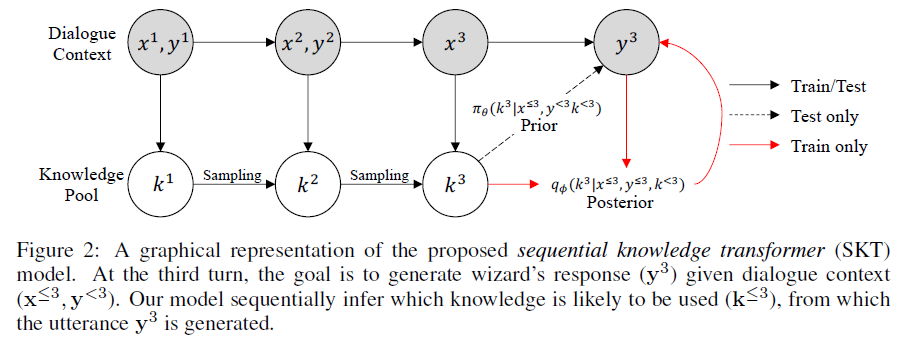
本质上也是后验逼近先验的方法,概率图模型如上图所示。对不同的对话轮数进行factorize,然后再优化其ELBO。
PIPM
[EMNLP2020] PIPM Bridging the Gap between Prior and Posterior Knowledge Selection for Knowledge-Grounded Dialogue Generation
腾讯之后提出了基于SKT的改进工作,从标题就能基本看明白想法:先验和后验信息之间存在gap。具体来说,从先验信息选择knowledge缺乏后验信息,模型训练时是基于后验选择的knowledge,而在推断时却只有先验分布。论文提出使用 Posterior Information Prediction Module (PIPM) 模块来预测和补全后验信息,和知识蒸馏的方式来解决用不合适的知识生成回复的问题。
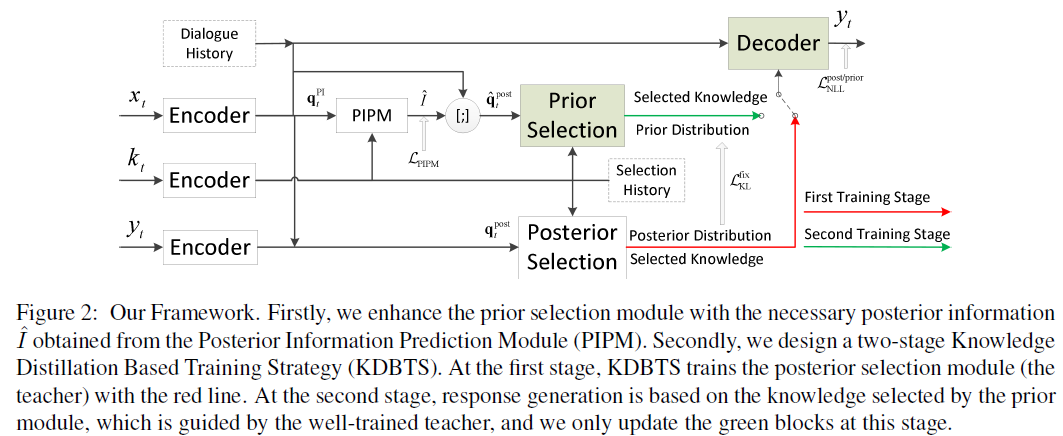
所谓的后验信息是以对话历史和knowledge pool作为输入,用前向网络来生成的一些词汇。
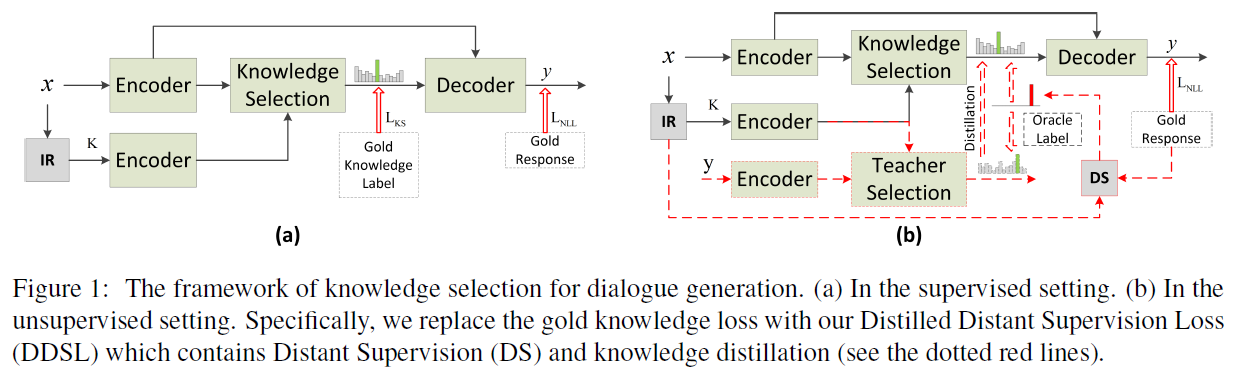
Unsupervised Knowledge Selection
[ACL2021findings] Unsupervised Knowledge Selection for Dialogue Generation
之后同作者又提出了使用无监督的方案来做knowledge selection, 所谓无监督,主要是不使用标注的golden label,而基于 Oracle Label进行选择。 Oracle Label 的生成是用启发式的方法找与response最接近的knowledge作为 golden:
Assuming that the gold knowledge should contribute most tokens to the response generation.
不过Oracle Label含有噪音,论文通过计算response与knowledge的相似度并重新归一化来提升效果。同时,还使用知识蒸馏的方式,teacher在训练时使用golden response作为额外输入,来引导student学习knowledge selection分布。
DiffKS
[EMNLP2020findings] DiffKS Difference-aware Knowledge Selection for Knowledge-grounded Conversation Generation
同期还有另一篇工作DiffKS,通过考虑历史选择的knowledge,来更好地指导本轮的选择。
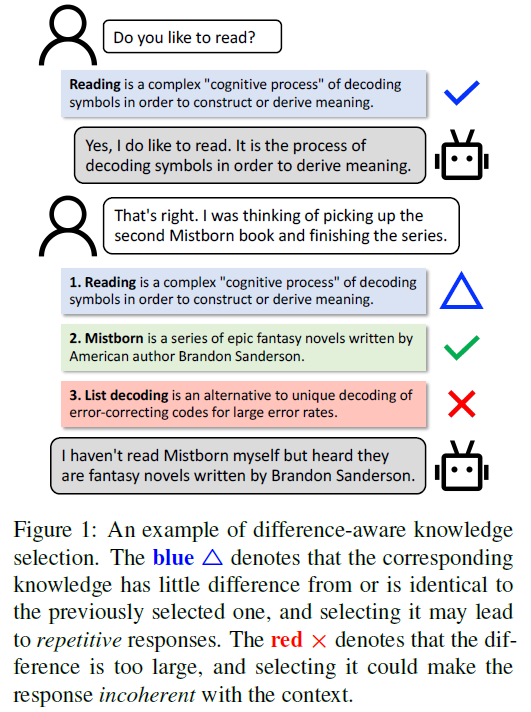
上面的例子解释了主要思路,如果本轮的选择与之前相同的knowledge,那么生成的回复就可能重复;如果本轮选择的knowledge与之前选择的knowledge差异过大,则会导致回复不一致的问题。
论文提出了两种方法引入对knowledge diff的建模:
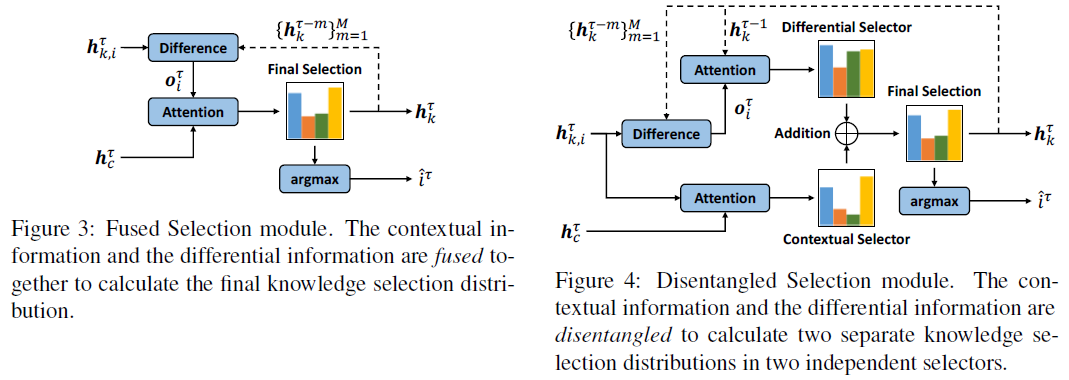
其中Disentangled Selection将上下文相关性与knowledge diff两部分的建模解耦,可以支持ablation study从而评估diff信息对模型性能的影响。最终实验也验证了diff信息在几个数据集上的效果都很明显。
Knowledge Augmentation
Retrieval Augmentation
[EMNLP2021findings] Retrieval Augmentation Reduces Hallucination in Conversation
对GPT3这样的大模型,在对话任务中常常会有一些额外的发挥,所谓hallucination:

为了解决这个问题,可以用KGC的方法,通过retrieval knowledge的方式,给模型提供更准确的信息,避免它自己的随意发挥。本文是个实验文章,对各种可能的 retrievers, rankers 和 encoder-decoders 进行排列组合,分析指出在什么情况下什么技术栈效果最好。同时它的最优模型也达到了SOTA的水平。
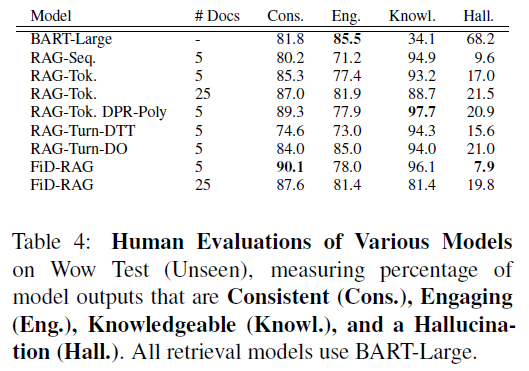
从结果来看,Response Generation中 FiD + RAG 的效果不错,而knowledge retrieval 使用 DPR 比较好。
Internet-Augmented Generation
[ACL2022] Internet-Augmented Dialogue Generation
即使语言模型很大,它记住的knowledge也会过时,于是就可能生成错误回复。结合前面的思路,既然提供额外的knowledge可以提升对话效果,减少自由发挥。那我们是否可以直接用搜索引擎根据上下文来搜索相关knowledge,同时解决自由发挥和知识实时性的问题?答案是肯定的,文章的标题已经把idea明确阐述。模型上也没有太多创新,还是 FiD+RAG, DPR 与 FAISS 这些,但有搜索引擎的强大搜索能力,回复质量得到了显著提升。
Generation Model
为了解决 <query, knowledge, response>
训练数据不足的问题,下面两篇文章分别在低资源和零资源的设定下,通过不同的模型结构达到构建可用KGC系统的目的。
Low-Resource KGC
[EMNLP2020] Low-Resource Knowledge-Grounded Dialogue Generation
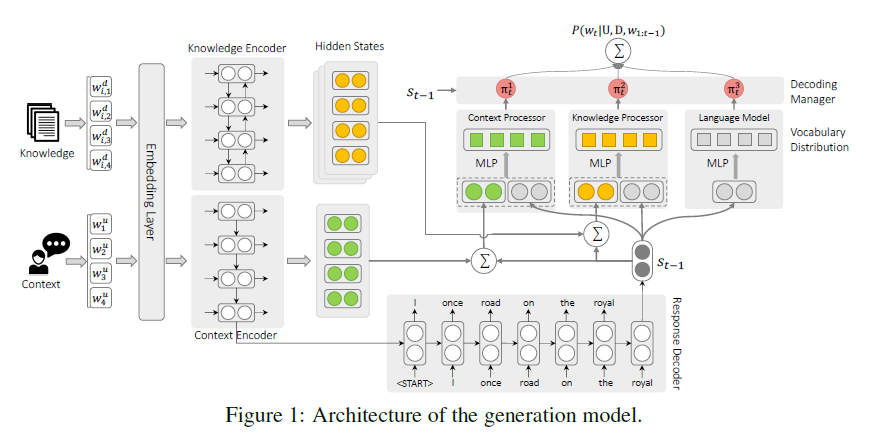
在训练数据较少的设置下,主要想法是通过解耦decoder,让生成模型的大部分参数可以通过较为容易获取的
<query, response> 数据进行学习:
The key idea is to make parameters that rely on knowledge-grounded dialogues small and independent by disentangling the response decoder, and thus we can learn the major part of the generation model from ungrounded dialogues and plain text that are much easier to acquire.
具体来看,在decoder每次进行word选择时,可以分成三部分:1. 语句通顺,符合语法 2. 符合上下文 3. 与提供的knowledge相符。而这三部分可以解耦单独学习,从而达到仅用少量数据就能学到完整模型的目的。
Zero-Resource KGC
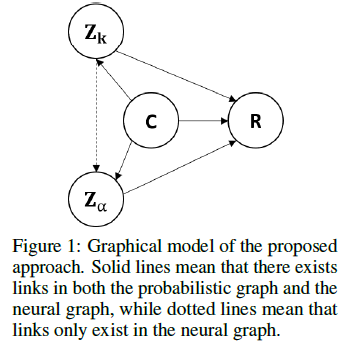
[NIPS2020] Zero Resource Knowledge Grounded Dialogue Generation
这篇文章是用变分推断的方式解决问题,引入了两个隐变量,其中 \(Z_k\) 代表 latent knowledge,\(Z_\alpha\) 控制要使用多少\(Z_k\)。目标是在无标注数据的情况下学习分布 \(p(R|C,K)\)。
KnowledGPT
[EMNLP2020] KnowledGPT Knowledge-Grounded Dialogue Generation with Pre-trained Language Models
同期的这篇工作是利用预训练语言模型对knowledge selection和response generation进行联合优化。使用GPT2作为预训练模型,构建由context-aware knowledge encoder和sequential knowledge selector组成的知识选择模块:
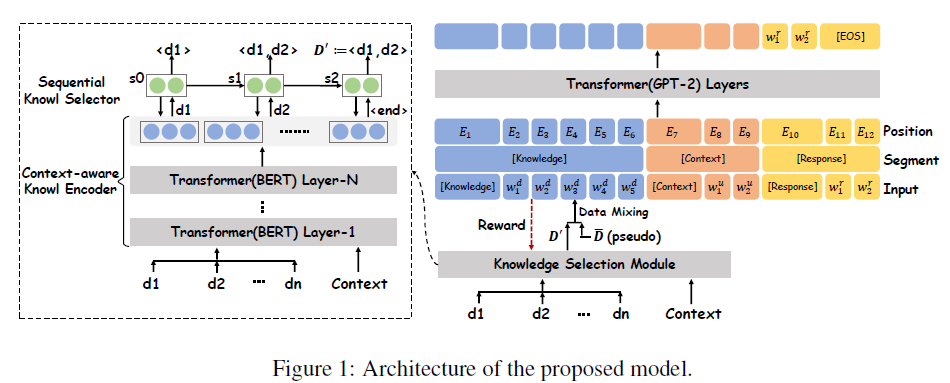
KnowledGPT 在WoW和CMU_DoG数据集中的大多评估指标上都达到了SOTA,说明预训练模型对KGC回复生成还是有显著的提升作用。
总结
本文简单梳理了KGC发展的脉络及代表工作,特别对 Knowledge Selection 与 Response Generation 部分工作的主要思想进行了概括和简介,没有公式,只谈思路,希望对大家有所启发。如对论文细节感兴趣,可参阅文末参考文献。疏漏在所难免,望见谅。
文中提到的都是传统KGC相关的工作,KGC作为研究热点,最近关于KGC的工作也是层出不穷,比如一些更难的问题 Stylized KGC, KGC与人设的结合等等。如有机会,且听下回分解~
参考文献
- [ICLR2019] [WoW] Wizard of Wikipedia: Knowledge-Powered Conversational Agents
- [IJCAI2019] PostKS Learning to Select Knowledge for Response Generation in Dialog Systems
- [ICLR2020] SKT Sequential Latent Knowledge Selection for Knowledge-Grounded Dialogue
- [EMNLP2020] PIPM Bridging the Gap between Prior and Posterior Knowledge Selection for Knowledge-Grounded Dialogue Generation
- [ACL2021findings] Unsupervised Knowledge Selection for Dialogue Generation
- [EMNLP2020findings] DiffKS Difference-aware Knowledge Selection for Knowledge-grounded Conversation Generation
- [EMNLP2021findings] Retrieval Augmentation Reduces Hallucination in Conversation
- [ACL2022] Internet-Augmented Dialogue Generation
- [EMNLP2020] Low-Resource Knowledge-Grounded Dialogue Generation
- [NIPS2020] Zero Resource Knowledge Grounded Dialogue Generation
- [EMNLP2020] KnowledGPT Knowledge-Grounded Dialogue Generation with Pre-trained Language Models