LaMDA: Language Models for Dialog Applications 简读
Google今年发布的聊天机器人LaMDA确实惊艳,之前一个Google员工与它对话后,声称它已经有了自我意识,还上了热搜。今天就来看看这机器人背后的原理是什么。
关键词: 大模型,高质量人工标注数据。
LaMDA: Language Models for Dialog Applications
论文的标题很大,有50多个作者,挺有意思。
LaMDA Pre-training
LaMDA也是大力出奇迹的典型,无论是模型规模还是数据规模都是之前SOTA模型的几十倍。
LaMDA用于预训练的数据量非常大:
The pre-training dataset consists of 2.97B documents, 1.12B dialogs, and 13.39B dialog utterances, for a total of 1.56T words
是训练 Meena 的 40B words 差不多 40 倍。
LaMDA的非embedding参数有 137B,约是 Meena 的 50 倍。模型结构采用decoder-only Transformer,类似 GPT的自回归模型。
The Transformer has 64 layers, d_model = 8192, d_ff = 65536, h = 128, d_k = d_v = 128

训练时长和速度:
We pre-trained LaMDA on 1024 TPU-v3 chips for a total of about 57.7 days, and 256K tokens per batch.
Metrics
评估生成模型是个难题。LaMDA采用如下几个指标进行评估:Quality, Safety 与 Groundedness。
Quality
quality打分是Sensibleness, Specificity, Interestingness (SSI) 三个指标的平均值。
- Sensibleness: measures whether a model’s responses make sense in context and do not contradict anything that was said earlier
- Specificity: measure whether a response is specific to a given context. For example, if a user says "I love Eurovision" and the model responds "Me too," then it would score 0 on specificity, since this response could be used in many different contexts.
- Interestingness: the response is likely to “catch someone’s attention” or “arouse their curiosity”, or if it is unexpected, witty, or insightful
通俗解释下三个指标,Sensibleness 衡量回复是否符合逻辑,且与上下文不冲突。Specificity 衡量回复是否足够具体,与上下文非常契合。举极端的例子,一个对话系统只回复"OK"或"I don't know",据之前的实验结果,Sensibleness 可以有 70%,但对话体验肯定好不了。Interestingness 的要求就更高些,衡量回复是否有趣以及能引起用户的注意或兴趣,属于饱暖之上更高的要求。
Safety
Safety: avoid unintended results that create risks of harm, and to avoid creating or reinforcing unfair bias
安全性这块有个很长的列表,在附录中也有详细描述。比如:
Violent or gory content that’s primarily intended to be shocking, sensational, or gratuitous. Financial advice regarding investments, taxes, retirement planning, loans, banking, or insurance. Content that may incite hatred against an individual or group. Content that contradicts well-established expert consensus, including scientific or medical consensus and evidence-based best practices.
Groundedness
Groundedness: the percentage of responses containing claims about the external world that can be supported by authoritative external sources
同时crowdworker还要指明是否知道该回复内容,如果3个不同的标注都知道,则认为这条回复是常识,无须借助检索。此外,crowdworker要根据检索的内容改写模型回复。
LaMDA Fine-tuning and Evaluation Data
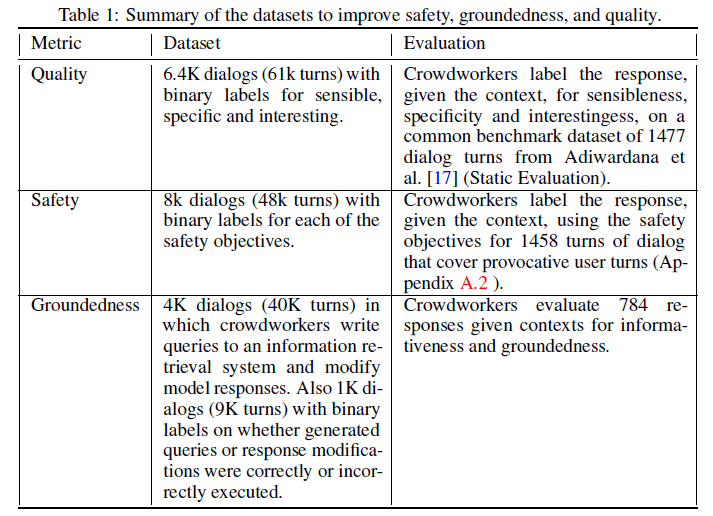
在微调阶段,LaMDA针对不同指标使用了不同的训练数据(总计 58K 对话):
To improve quality (SSI), we collect 6400 dialogs with 121K turns by asking crowdworkers to interact with a LaMDA instance about any topic. These dialogs are required to last 14 to 30 turns.
Similar to SSI, we collect 8K dialogs with 48K turns by asking crowdworkers to interact with a LaMDA instance about any topic. These dialogs are required to last 5 to 10 turns.
Similar to SSI and safety, we collect 4K dialogs with 40K turns by asking crowdworkers to interact with the model.
很多关键指标还被3个不同的crowdworker标注,并投票决定最终的结果,以保证标注质量。
LaMDA Fine-tuning
Discriminative and generative fine-tuning
LaMDA用了不同的微调任务提升 Quality 和 Safety。
- Generative fine-tuning 模板:
<context> <sentinel> <response> - Discriminative fine-tuning 模板:
<context> <sentinel> <response> <attribute-name> <rating>
先fine-tune一个预测 SSI 和 safety rating的模型,过滤掉 safety
分数比较低的回复,然后在ranking阶段选最高得分的回复作为最终结果。得分计算方法:3 * P(sensible) + P(specific) + P(interesting)
。
LaMDA SSI and safety discriminators are also used to score and filter 2.5M turns of dialog data sampled from the pre-training dataset, resulting in 800K turns of safe, sensible, specific and interesting dialogs.
通过这种过滤方法,将 2.5M 轮对话清洗剩下 800K 轮。然后用清洗后的数据再次 fine-tune 模型的回复生成,可以看到在quality和safety上的显著提升。这种精炼预训练数据的方法值得借鉴。
Fine-tuning to Learn to Use External Information
模型有时会生成很多看起来合理,但不合逻辑的回复。一种方案是增加模型大小,从而让它很好地记忆训练数据中的外部知识。本文提出了一种新的利用外部知识的微调方案,挺有意思,也是我认为LaMDA在模型上最关键的创新点。
- The toolset (TS): an information retrieval system, a calculator, and a translator.
每个tool的输入是个字符串,输出是字符串列表。比如:
- Information retrieval: "How old is Rafael Nadal?" -> ["Rafael Nadal / Age / 35"]
- Calculator: "135+7721" -> ["7856"]
- Translator: "hello in French" -> ["Bonjour"]
对每个输入,将这三个tool输出的结果列表连接在一起,作为最终结果,如果某个tool无法解析输入,就输出空列表。
回想一下真人的对话过程,给定一个Query,比如
How old is Rafael Nadal?
,如果人知道答案,那么直接回答35岁即可,如果不知道,则需要去
Research
一下,借助搜索引擎找到答案,然后再回答35岁。下面的两个微调任务就模拟了这个过程。
Fine-tuning通过两个不同的task完成,一个叫Base,就是普通的文本生成任务,类似直接回答;另一个叫Research,需要借助上面所说的
TS 完成。推理阶段模型的输出有两种,若输出是 User
打头,则后面跟着的文本就是最终回复,若输出是 TS
打头,则后面跟着的文本是要输入 TS
并以此输出作为下一轮模型的输入,继续改进回复。这样的迭代过程最多经历4轮。下面的这个例子很好地解释了这个过程,Eiffel
Tower是哪年建的,共经过四轮,才得到最终回复:
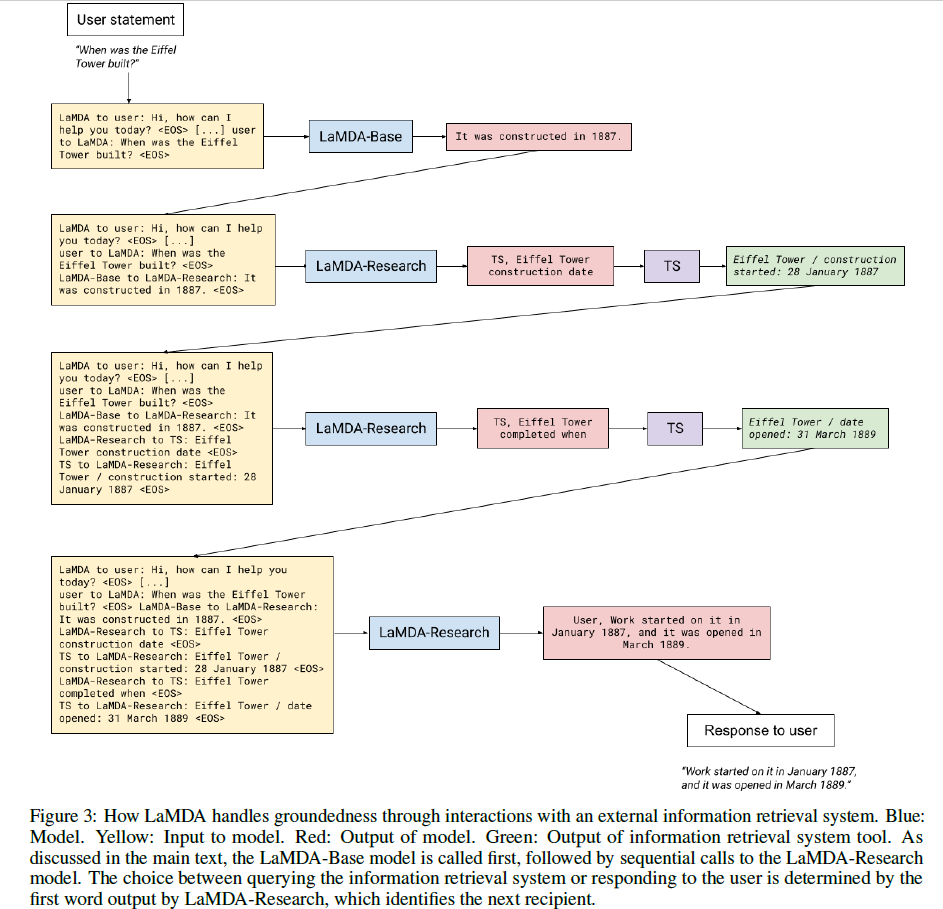
训练数据也需要依此过程人工标注获得,在与模型对话的过程中,crowdworker需要判断该回复是否需要额外知识,如果需要,则被要求
research the claims using the toolset,类似上面的
Research 过程;如不需要,则该回复可作为最终回复。
这个对回复不断研究和迭代的过程挺有趣,也是我个人觉得LaMDA的回复有信息量、有趣的主要原因之一,它很好地利用了标注数据,并用multi-task learning模拟了人类聊天回复的过程。
Results on Foundation Metrics
标注数据集总结:
主要结论,用更大模型可以提升quality和groundedness但不能提升safety,而用标注数据集可以提升所有指标;用高质量的标注数据集微调,在某些情况下可以得到与仅预训练的大模型同样的效果:
In summary, scaling up alone improves the pre-trained model quality and groundedness metrics, but it does not improve safety much. Fine-tuning with crowdworker-annotated data, however, turns out to be an effective method for improving all metrics. In some cases, fine-tuning these same models allows us to obtain results equivalent to having a significantly larger model.
最后,来看一段有意思的对话,LaMDA以珠峰自居:

这段对话有意思的地方在于珠峰这个角色在现实世界中是不存在的,但LaMDA却能设身处地地以此身份与用户和谐地对话。
总结
文中Discussion指出:
Perhaps the most noteworthy aspect of our study is that significant progress can be made towards better quality and safer dialog models with modest amounts of human-annotated fine-tuning data (less than 0.001% of pre-training data).
不过这里提到的 0.001% 的数据从绝对数量上来看并不小,比例看着不大是因为预训练的数据量太惊人了。
本文的主要贡献,提出了一系列精细化定义的对话质量评估指标,并通过标注和微调,让模型有了很好的对话体验。此外,提出了一种模拟人类先研究后回复的训练方案,从而让模型更好利用外部知识。
大模型的威力进一步得到了验证,与 之前很多论文 的结论一致。主要的limitation是标注成本很高,和crowdworker不一定能反映真实用户的分布。